数据分析
QQ群
视频号

微信

微信公众号

知识星球
- 153 次浏览
【假设分析】Apromore的业务流程模拟与假设分析
QQ群
视频号
微信
微信公众号
知识星球
什么是我的流程的最佳设计!?如果我收到两倍的订单,会发生什么?如果我再雇佣两名专家会怎么样?
现代业务流程挖掘(BPM)工具能够生成业务流程的副本(也称为数字孪生),运行模拟并分析如果条件发生变化会发生什么(假设分析)。本文是如何在Apromore(可用的最高级BPM工具之一)中执行此操作的逐步示例。
大纲:
- 创建流程模型,
- 定义模拟参数(任务需要多长时间以及有多少资源可用),
- 通过添加/删除资源、更改流程任务的持续时间或修改流程设计来创建模型的替代版本。
- 运行模拟并比较结果。
创建流程模型
让我们首先在Apromore的BPMN(业务流程模型和符号)编辑器中创建一个模型。顾名思义,您可以通过创建任务、网关并连接它们来构建传统的BPMN风格的流程。
为了这个演示的目的,我将对技术演示过程进行建模。这是我们部门的流程之一,旨在发现新的数字技术并向我们的业务部门演示。该过程包括以下步骤:
- 技术研究,
- 将技术添加到评估列表中,
- 验证技术,
- 根据评估结果,将技术标记为“测试”或“保持”,
- 选择要演示的技术,
- 找到一个用于演示的用例,
- 进行概念验证,
- 证明
下图显示了我们如何构建和连接流程的最初两个任务。
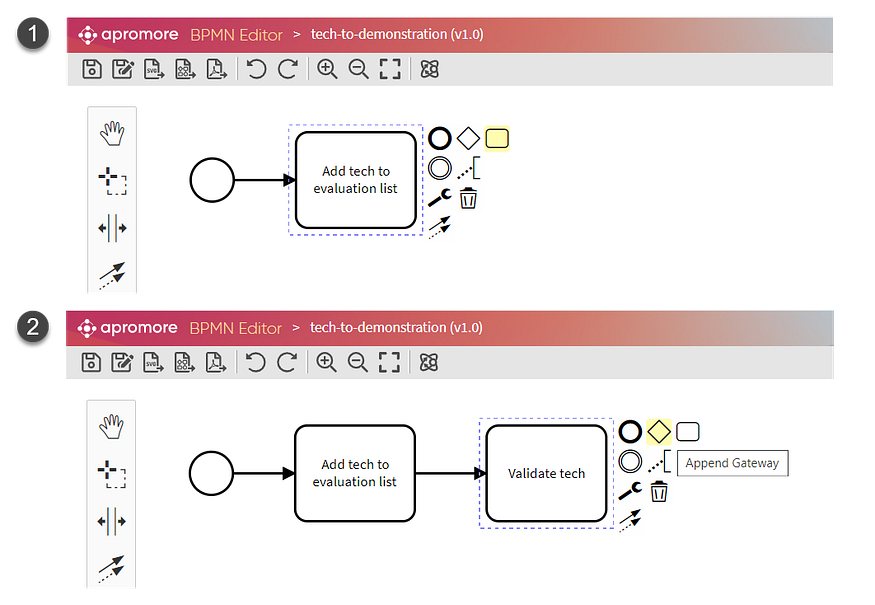
Figure 1: Building a process model with Apromore’s BPMN Editor (image by Author — screenshots from Apromore)
我们继续添加任务、网关和连接器,直到模型完成。是的,我知道这是老的无聊BPMN的东西,但我保证事情很快就会变得更有趣:)!
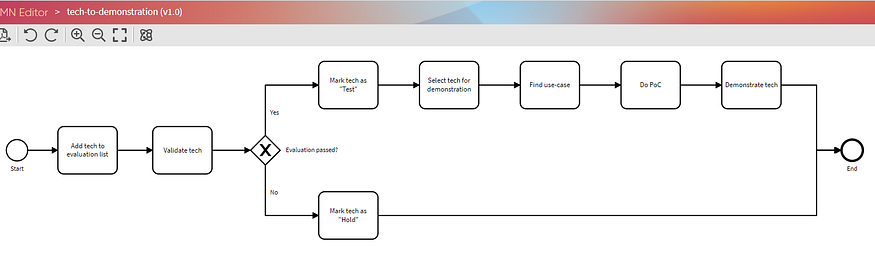
Figure 2: Fully built process model in Apromore’s BPMN Editor (image by Author — screenshots from Apromore)
定义模拟参数
Apromore的BPMN编辑器通过“模拟参数”定义流程元素的动力学,使我们的静态模型栩栩如生。下图显示了可以设置的不同类型的模拟参数:
- 一般——我们多久会有一个新的案例出现,正在模拟的流程实例(案例)的总数以及模拟的开始日期。
- 任务——设置所有流程任务的持续时间分布(即:执行任务需要多长时间)。
- 时间表——定义人员和机器的工作时间表(例如,专家从上午9点到下午17点工作)。
- 资源——定义可用资源(人员和机器)的类型和数量。
- 网关——定义网关的转换概率(例如,通过评估的案例比例是多少)。
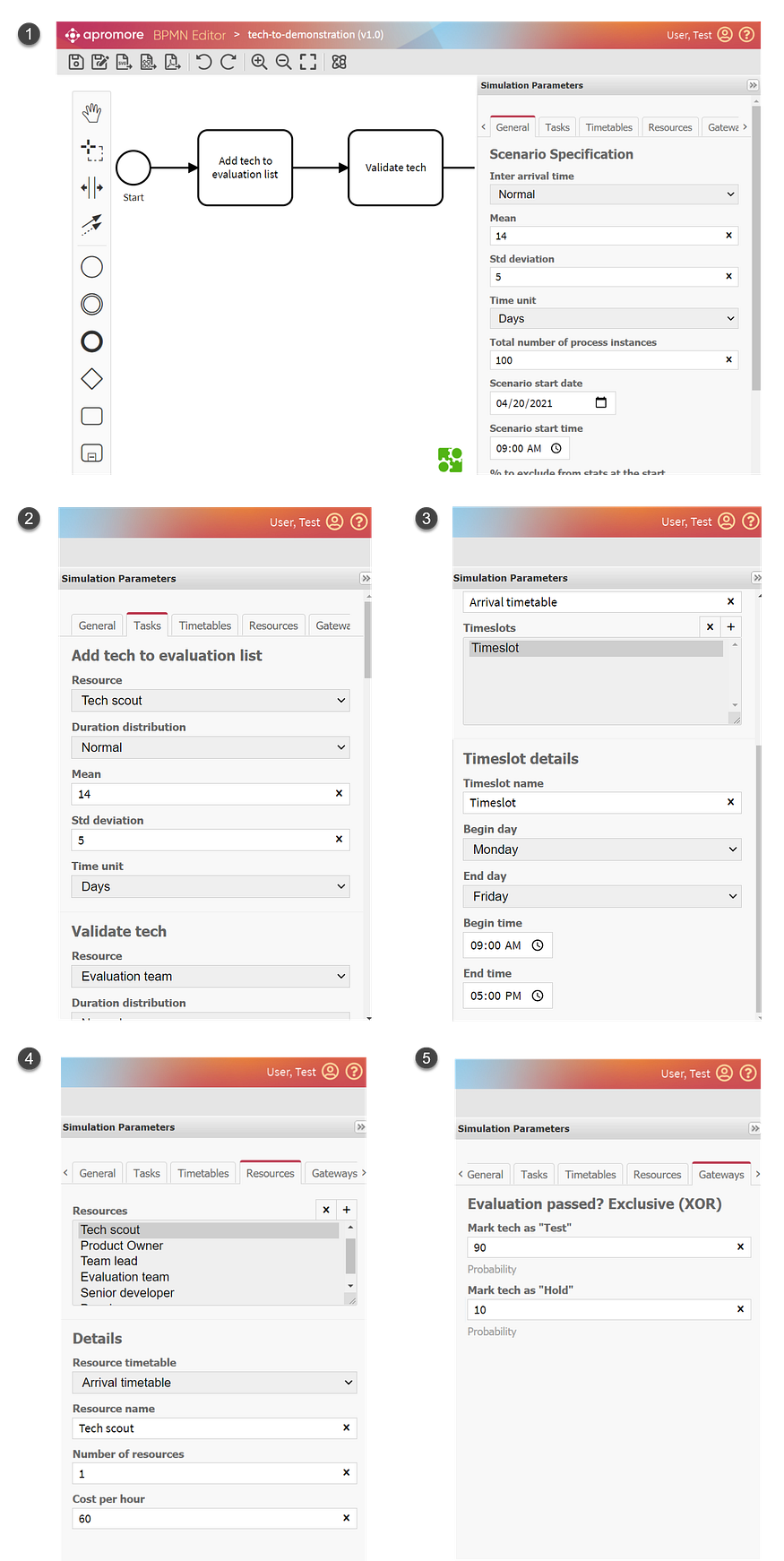
Figure 3: Different types of simulation parameters in Apromore (image by Author — screenshots from Apromore)
注意:注意,该工具可以将持续时间设置为概率分布。换言之,我们可以说,平均而言,新病例每两周出现一次,但有时需要5天甚至10天的时间,有时新病例在最后一例病例出现几天后才出现。这种概率性在模拟中非常重要,因为使用静态值,我们将无法看到边缘情况(例如,可能发生的最坏情况是什么)。
运行模拟
定义所有任务的模拟参数后,我们可以通过选择模型并使用“模拟模型”功能(1)来运行模拟。这产生了一个模拟的业务日志(2),我们可以打开并分析它。
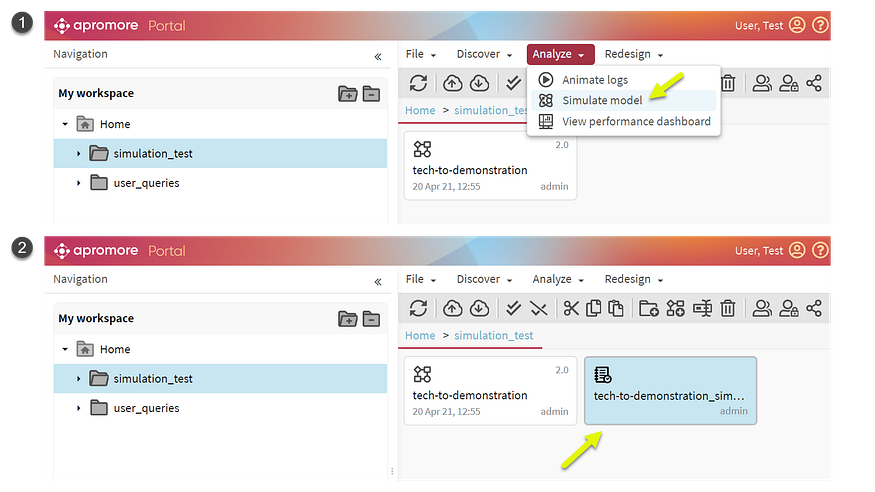
Figure 4: Generating the simulated process log in Apromore (image by Author — screenshots from Apromore)
假设分析
假设分析是关于更改模拟参数(例如添加或删除资源)并重新运行模拟。这些步骤包括:
- 在BPMN编辑器中更改一些模拟参数。
- 运行模拟以创建替代过程日志。
- 分析模拟日志以查看更改。
下图显示了如果我添加一个额外的开发团队会怎样的结果。在商业模式的第一个版本中,我将开发团队的数量设置为2个,在第二个版本中我将团队的数量增加到3个。在这两个版本中,都创建了一个模拟流程日志(img 1)。接下来,我比较了流程日志的统计数据,看看添加开发团队(img 2和img 3)的确切效果如何。
我们的假设分析显示,对于2个开发团队(img 2),执行20个技术到演示流程实例大约需要1年零1个月的时间。对于3个团队(img 3),相同数量的流程实例大约需要11个月。因此,基于假设分析,我们可以得出结论,拥有一个额外的开发团队将使我们获得2个月的时间。
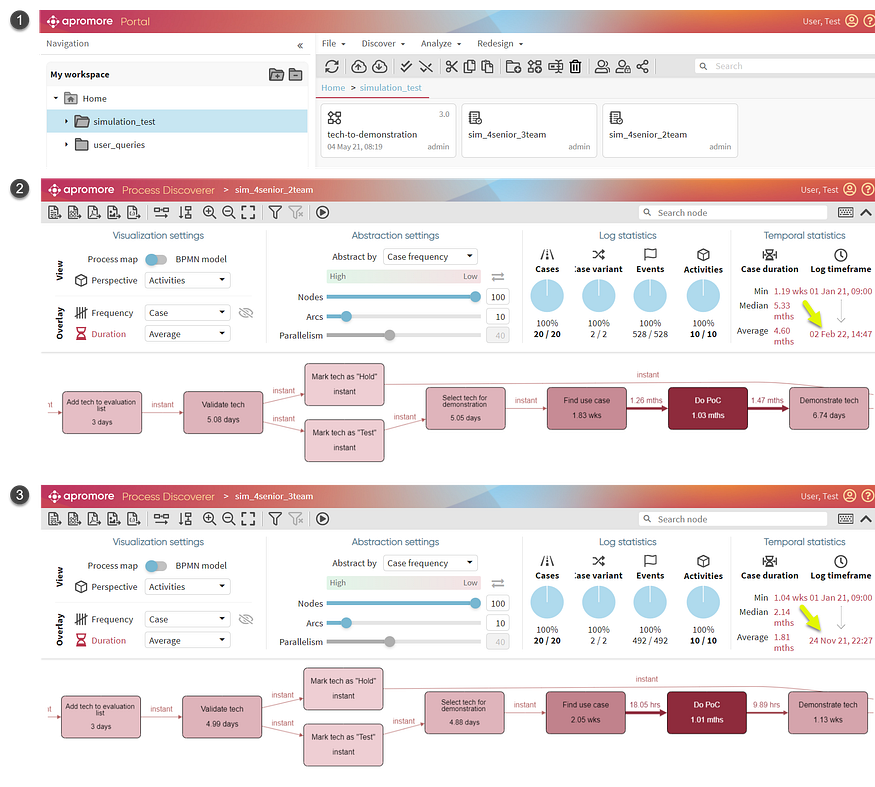
Figure 5: Analyzing the effect of adding an additional development team (img 2 has 2 dev teams and img 3 has 3 dev teams) by comparing two simulated process logs (image by Author — screenshots from Apromore)
总结
新颖的过程挖掘工具能够创建动态过程模型,用于模拟各种条件下的过程。假设分析就是模拟一个过程的几个不同版本并比较结果。在设计新的业务流程时,这是一个有用的功能——可以利用不同的流程设计,修改资源数量以找到最佳设置。此外,假设分析对现有流程很有用,因为它可以a)分析添加/删除资源的效果,b)通过增加传入工作来测试流程的限制,c)在安全(模拟)环境中看到重新设计的效果。总之,模拟和假设分析的结合有很大的潜力将流程管理带入一个新时代。
- 25 次浏览
【图型计算架构】GraphTech生态系统2019-第2部分:图形分析
这篇文章是关于GraphTech生态系统系列文章的一部分。这是第二部分。它涵盖了图形分析领域。第一部分是关于图形数据库,第三部分将列出现有的图形可视化工具。
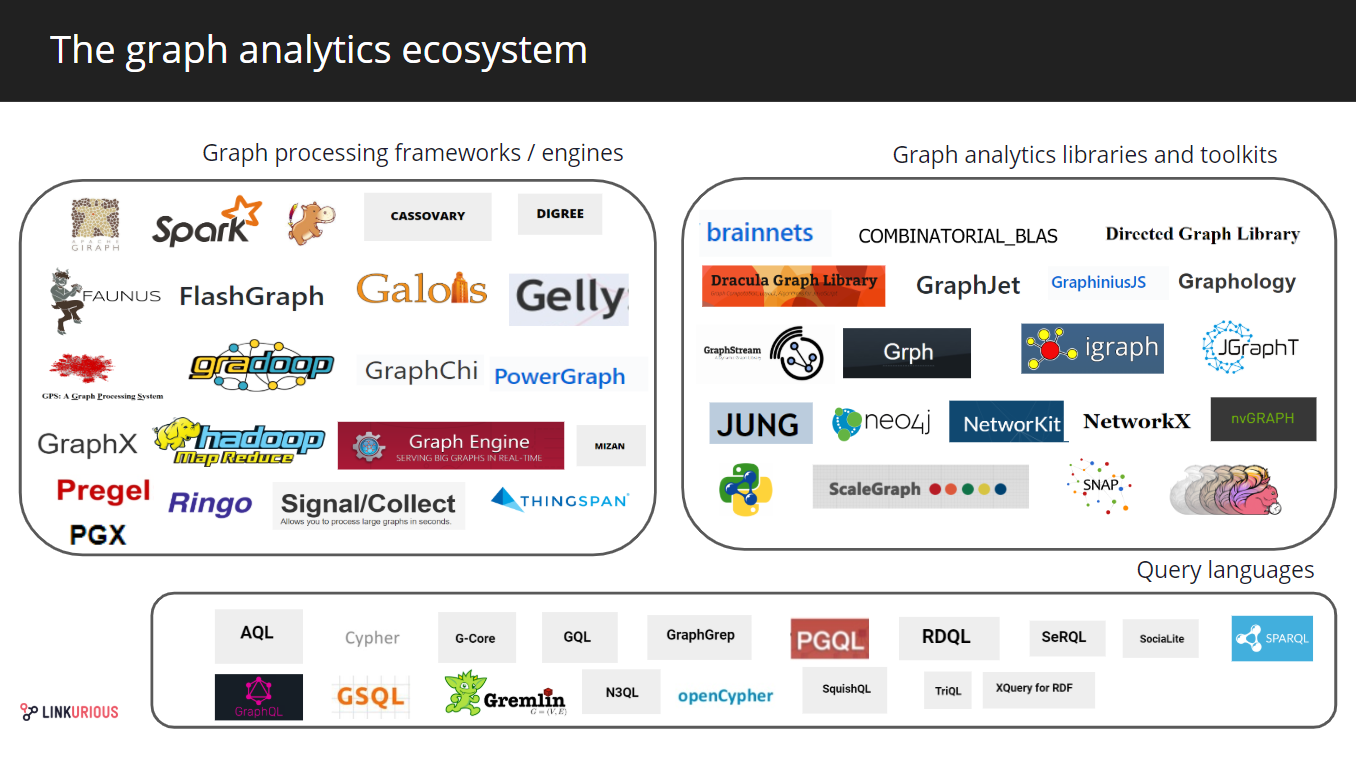 Actors of the graph analytics landscape in 2019
Actors of the graph analytics landscape in 2019
第二层是另一个后端层:图形分析或计算框架。它们由一组工具和方法组成,这些工具和方法是为了从以图形形式建模的数据中提取知识。它们对于许多应用程序都至关重要,因为处理复杂连接数据的大数据集在计算上具有挑战性。
对大规模分析的需求
图论领域已经产生了多种算法,分析人员可以依赖这些算法来发现隐藏在图表数据中的见解。从Google著名的PageRank算法到遍历和路径查找算法或社区检测算法,都有大量的计算可以从图表中获得见解。
我们在上一篇文章中提到的图形数据库存储系统擅长将数据存储为图形,或者管理诸如数据检索、编写实时查询或本地分析之类的操作。但是,他们可能在规模化的图形分析处理方面存在不足。这就是图形分析框架介入的地方。与常见的图形算法、处理引擎,有时还有查询语言一起,它们处理在线分析处理,并将结果保存回数据库。
图形处理引擎
图形处理生态系统提供了各种方法来应对图形分析的挑战,历史玩家占据了市场的很大一部分。

Main graph engine processing and framework vendors
2010年,Google率先发布了Pregel,一个“大规模图形处理”框架。几个解决方案,如Apache GIRAPH,一个开放源码的图形处理系统在2012由Apache基金会开发。它利用MapReduce实现来处理图形,是Facebook用来遍历其社交图的系统。其他开源系统迭代了Google的,比如Mizan或GPS。
其他系统,比如GraphChi或PowerGraph Create,都是在GraphLab于2009年发布之后推出的。这个系统最初是卡内基梅隆大学的一个开源项目,现在被称为Turi。
oraclelab开发了PGX(Parallel Graph AnalytiX),这是一个图形分析框架,包括一个支持Oracle大数据空间和图形的分析处理引擎。
微软于2013年推出的分布式开源图形引擎Trinity现在被称为微软图形引擎。GraphX于2014年推出,是在apachespark之上构建的用于并行计算的嵌入式图形处理框架。后来又引入了一些其他系统,例如信号/采集。
图形分析库和工具箱
在图形分析领域,也有专门用于图形分析的单用户系统。图分析库和工具箱提供图论算法的实现。
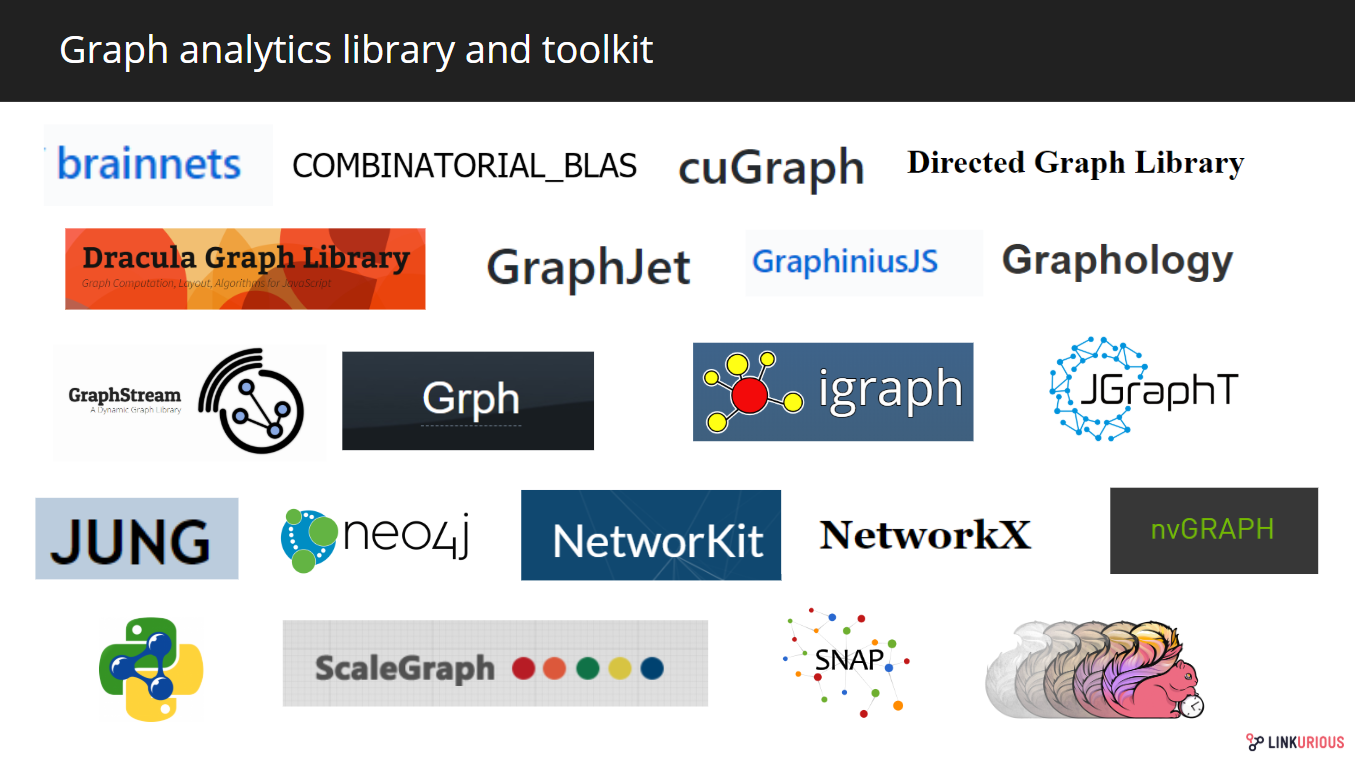
Some libraries and toolkits offering graph analytics capabilities
有独立的库,如NetworkX和NetworKit,用于大规模图形分析的python库,或iGraph,一个用C编写并以python和R包提供的图形库,以及由图形数据库供应商Neo4j及其图形算法库提供的库。
其他技术供应商为高性能图形分析提供图形分析库。这是GPU技术提供商NVIDIA及其NVGraph库的例子。地理信息软件QGIS也建立了自己的网络分析库。
其中一些库还提出了图形可视化工具来帮助用户构建图形数据探索接口,但这是本系列第三篇文章的主题。
图形查询语言
最后,还没有提到的一个重要的分析框架:图形查询语言。
对于任何存储系统,查询语言是图形数据库的基本元素。这些语言使得将数据建模为图形成为可能,并且它们的逻辑非常接近于图形数据模型。除了数据建模过程外,还使用图形查询语言对数据进行查询。根据它们的性质,它们可以用于数据库系统,也可以作为领域特定的分析语言。大多数高级计算引擎允许用户使用这些查询语言进行编写。
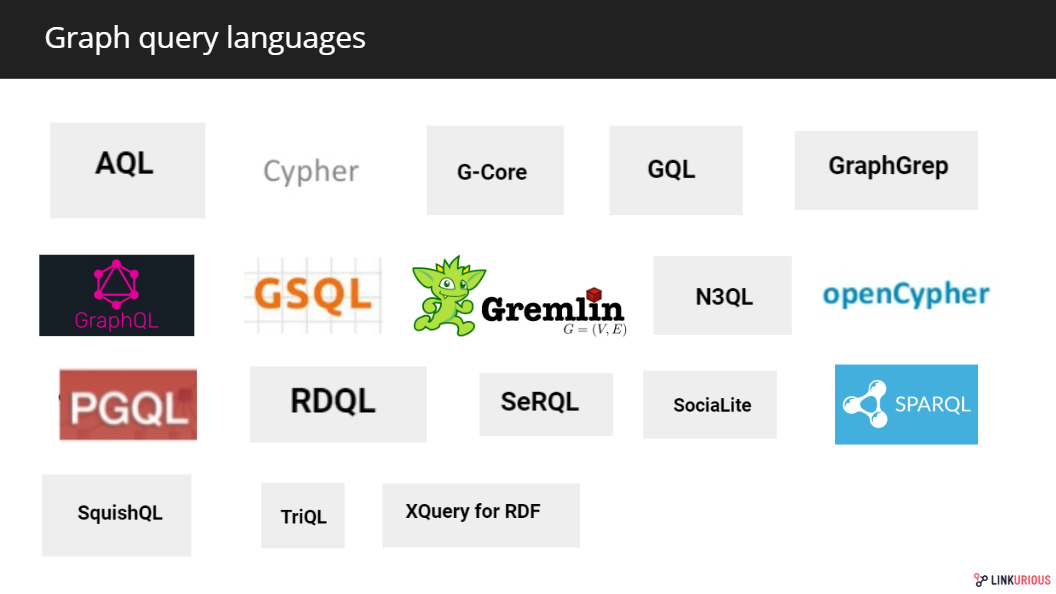
Some of the existing graph query languages and similar projects
Cypher是Neo4j在2011年创建的,用于他们自己的数据库。它在2015年作为一个名为OpenCypher的独立项目被开源。其他值得注意的图形查询语言还有:Gremlin(2009年创建的apachetinkerpop查询语言的图形遍历语言)或SPARQL(W3C在2008年创建的查询RDF图的类SQL语言)。最近,TigerGraph开发了自己的图形查询语言GSQL,Oracle创建了PGQL,这两种都是类似SQL的图形查询语言。G-Core是由链接数据基准委员会(LDBC)于2018年提出的,作为连接学术界和工业界的语言。其他供应商,如OrientDB,则使用关系查询语言SQL。
去年,Neo4j发起了一项计划,将Cypher、PGQL和G-Core统一到一种标准图形查询语言GQL(graph query language)下。该计划将在2019年3月的W3C研讨会上讨论。其他一些查询语言特别专用于图形分析,如SocialSocial。
Facebook的GraphQL本来不是一种图形查询语言,但值得一提。这个API语言已经被图形数据库供应商扩展为一种图形查询语言。Dgraph使用itnativelyas作为查询语言,Prisma正计划将其扩展到各种图形数据库,Neo4j已经将其推进到GRANDstack及其查询执行层Neo4j中-图形ql.js.
原文:https://medium.com/@Elise_Deux/the-graphtech-ecosystem-2019-part-2-graph-analytics-8ca5af4f83a9
本文:http://jiagoushi.pro/node/1093
讨论:请加入知识星球【首席架构师圈】或者微信小号【jiagoushi_pro】
- 57 次浏览
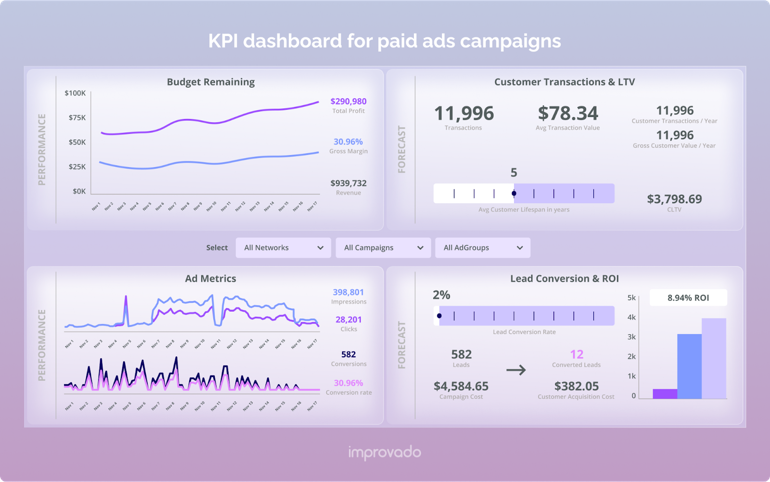
【数据分析】KPI仪表板:它们是什么以及如何构建
QQ群
视频号
微信
微信公众号
知识星球
创建关键绩效指标(KPI)是一回事。了解如何阅读这些KPI并有效跟踪完成进度是另一回事。
在一个仪表板上显示所有KPI有助于创建一个连贯的数据故事,帮助团队实现并超越目标。如果没有仪表板,通常很难看到森林中的树木,也很难自信地完成所有目标。
准备好了解更多有关KPI仪表板的信息并探索如何为自己构建一个仪表板了吗?然后,让我们深入了解。
关键要点
- KPI仪表板将来自各种来源的数据组合在一起,并使用图表和图形等视觉元素显示关键见解。
- 有效的KPI仪表板以目标为中心,只包括最终用户回答KPI特定业务查询所需的数据。
- KPI仪表盘的一些关键好处包括促进高管决策,识别机会和表现不佳,提高团队协作和透明度,以及促进大规模实时数据分析。
- 要创建KPI仪表板,请首先选择要跟踪的KPI和指标。然后选择相关的数据源。一旦你确定了这些,就可以使用相关的图表来可视化数据。最后,共享仪表板。
- 遵循最佳实践构建每个人都信任的KPI仪表板。只包括与目标相关的数据,有效地使用文本和交互式元素,在视觉上保持一致,保持简单,并使用高质量的数据。
- Improvado等分析工具可以自动同步来自不同来源的所有数据,确保所有数据都具有令人满意的质量,并为您提供KPI仪表板,作为团队的单一真相来源。
什么是KPI仪表板?
KPI或关键绩效指标是跟踪公司、部门、团队或个人在实现目标方面进展情况的衡量标准。换句话说,它们是根据不同来源的数据计算的成功指标。
KPI仪表板以直观、易于理解的格式显示KPI的进度,以帮助为业务决策提供信息。实时仪表板自动化了任何手动数据争论过程,使团队能够专注于揭示对其目标进展的见解。
KPI仪表盘是希望加入数据驱动方的团队和公司的必要基础。然而,确保您使用高质量的数据来避免错误的见解是至关重要的。
KPI仪表板包括什么?
KPI仪表板包括最终用户为实现最终目标做出数据驱动决策所需的所有相关数据,并随时调整其战略。
包含的指标取决于仪表板的受众。他们的目标是什么?他们想回答什么问题?哪些KPI对受众衡量绩效很重要?哪些数据最能帮助他们获得可操作的业务见解?
一旦确定了这些变量,请选择需要包含在仪表板中的所有相关数据。使用各种可视化技术,如随时间变化的趋势分析、比较和基准,以提供更多的上下文。
此外,在视觉效果中添加注释,以帮助向最终用户描述数据。
KPI仪表板的主要业务优势
只有当你能理解数据时,数据才有用。然而,随着你收集的数据数量的增加,理解数据变得越来越复杂。这就是KPI仪表板可以帮助您做到的。让我们回顾一下这究竟是如何实现的。
促进有效的行政决策
有了KPI仪表板,高管们不必等待不同部门报告他们的活动和绩效。所有这些信息都存储在公司KPI的单一真实来源中。
高管们可以实时查看每个团队的绩效以及对组织底线的贡献。这意味着他们可以看到要专注于哪些单元和流程,以更快地实现业务目标。
提高运营效率和有效性
KPI仪表板简化了组织工作流程,使员工能够轻松高效地工作。
比方说,营销团队需要销售团队的客户转化率数据或客户支持团队的客户满意度指数得分。在这些情况下,他们可以从KPI仪表板中获取这些信息,而无需等待有人将数据交给他们,从而停止了各方之间耗时的来回交流。
提高团队之间的协作和透明度
有了实时数据的共享KPI仪表板,团队可以轻松地做出决策,而无需等待其他人的输入。
这使数据民主化,促进协作和加速沟通,最终实现更好的团队协作和更快乐的员工。
方便大规模的实时数据分析
KPI仪表盘的实时交付使高管能够在业务运营发生时深入了解业务运营。
使用仪表板的交互式元素,他们可以深入了解每个特定的KPI,而无需浏览许多电子表格或浏览不同的程序。
为预测业务增长提供有价值的数据
KPI告诉你如何朝着目标前进。有了KPI仪表板,您就有了一个工具,可以帮助您评估业务的发展方向。
您可以更好地了解模式和预测业务增长,并据此决定下一步将使您能够有效地实现业务目标。
提供关于优先事项的见解
数据淹没对许多决策者来说是一个巨大的问题。拥有相关KPI的仪表盘——由高质量的数据推动——意味着您可以更好地分析业务运营,而不会不知所措。
由于仪表板能够正确地组织和可视化关键信息,因此您可以快速确定要关注的内容和优先级。
创建KPI仪表板的步骤
开发KPI仪表板是一项复杂而耗时的活动。但是,不适合那些知道正确步骤并使用正确工具来可视化KPI的人。
选择要跟踪的KPI和指标
最终用户希望回答哪些问题,他们需要什么信息?在创建KPI仪表板时请考虑这一点,这样您就不会以虚荣指标为特色。
只关注受监控活动的最关键指标。例如,如果你正在构建一个销售渠道仪表板,你肯定不需要包括CLTV或CPA,因为销售人员几乎与这些指标无关。
大多数KPI仪表板使用MAD框架,这是一种创建仪表板的三级方法。它包括年度经常性收入或相对市场份额等高级KPI的监控级别,用于分析各个部门的KPI的分析级别,以及用于深入分析的详细KPI的演练级别。
选择相关数据源
评估所有可用的数据源,并决定哪些数据源是相关的。这并不总是那么简单,尤其是现在企业使用的许多工具。
明智地选择数据源,因为每一个新的数据源都会带来工程和维护方面的麻烦。你必须将每个源连接到你的仪表板工具,获取正确的数据,将其转换为易于理解的形式,并想出新的图表来可视化它。更不用说数据源带有独特的API,需要在后端频繁更新。
更好的选择是将所有所需的数据源与自动化分析平台连接起来。例如,Improvado集成了500多种不同的营销和销售数据源,可以快速提取数据,并将其简化为适合用户目标的仪表板。使用Improvado的即插即用方法,您可以通过添加库中的数据源来启动分析并在进行分析时进行扩展。
创建合适的图表
数据可视化的重要性不亚于数据收集。你的主要挑战是想出正确的方式用图表和图表讲述你的故事。
例如,如果要比较值,请使用条形图和散点图。对于分析趋势,折线图和柱状图是理想的。您可以使用Mekko/Marimekko等图表来了解数据分布。
再说一遍,从头开始构建可视化需要商业智能工具的分析专业知识和经验。
但你可以走轻松的路。Improvado为您的营销和销售数据提供了各种仪表板模板。您不必创建任何图表。只需连接数据源,选择模板,然后根据需要修改图表。这就是如何在拥有商业智能工具提供的相同灵活性的同时节省仪表板开发时间的方法。
共享仪表板
向所有需要查看KPI面板的人授予访问权限(具有适当的权限)。您还可以将其导出为PDF文档,以便通过电子邮件、会议或演示文稿进行共享。
构建KPI仪表板的最佳实践
当您遵循一些最佳实践时,创建有效的KPI仪表板会变得更容易。
仅包括与目标相关的KPI
始终了解受众,以及他们为什么需要KPI仪表板。
他们想知道什么?他们需要比较和对比哪些KPI?在考虑受众的情况下构建仪表板将揭示应该包含哪些信息。
有效使用文本
你的数据说明了一个故事。尽管图表和图表说明了这一点,但用于标记和描述的语言也是如此。
使用经过深思熟虑的注释原则,明确您想要理解的见解。
清楚地标记交互式元素,并明确它们是可点击或可钻取的。
以视觉一致性为目标
拥有好看的KPI仪表板是有效仪表板的关键要素。您的最终目标是显示组织中的关键人员可以快速深入了解的数据。
做到这一点的一种方法是坚持一致的颜色和风格,并应用视觉设计原则。
保持简单
你很容易对所有数据中的各种图表感到兴奋,但混乱会破坏KPI仪表盘。
让它们尽可能简单。过度使用无关数据——无论多么有趣——只会分散你试图传达的叙事的注意力。
确保使用干净的数据
KPI仪表板使数据易于理解。但是,如果这些数据来自质量较差的来源,那就没有用了。在创建仪表板之前,请确保数据的完整性和准确性是可靠的。
如何使用Improvado创建KPI仪表板
创建KPI仪表板是一项耗时的工作,尽管这是一项非常宝贵的时间。如果你做得很好,从数据收集到图表造型,你的任何商业活动都会有一个单一的真相来源。
营销分析平台使流程简化了10倍。您只需插入所需的数据源,选择要跟踪的指标,然后选择适合您的仪表板模板。
使用Improvado和自己构建仪表板的主要区别在于,我们已经为您完成了所有工作。你只需要选择你想在仪表板上看到什么以及你想如何看到它。
- 156 次浏览
【数据分析】Web服务度量的时间序列分析与预测
讨论用于分析和预测Web服务度量及其应用的各种机器学习技术。
概述
在本文中,我们将讨论各种用于分析和预测web服务度量及其应用的机器学习技术。自动伸缩是这方面的一个很好的应用,其中可以应用预测技术来估计web服务的请求速率。类似地,可以将预测技术应用于服务度量,以预测警报和异常。
在本文中,我将首先讨论时间序列数据及其在预测技术中的作用。稍后,我将演示一个用于预测web服务请求率的预测模型。本文提供了对时间序列预测技术的基本理解,这些技术可以应用于服务度量或任何时间序列数据。
开始…
什么是时间序列?
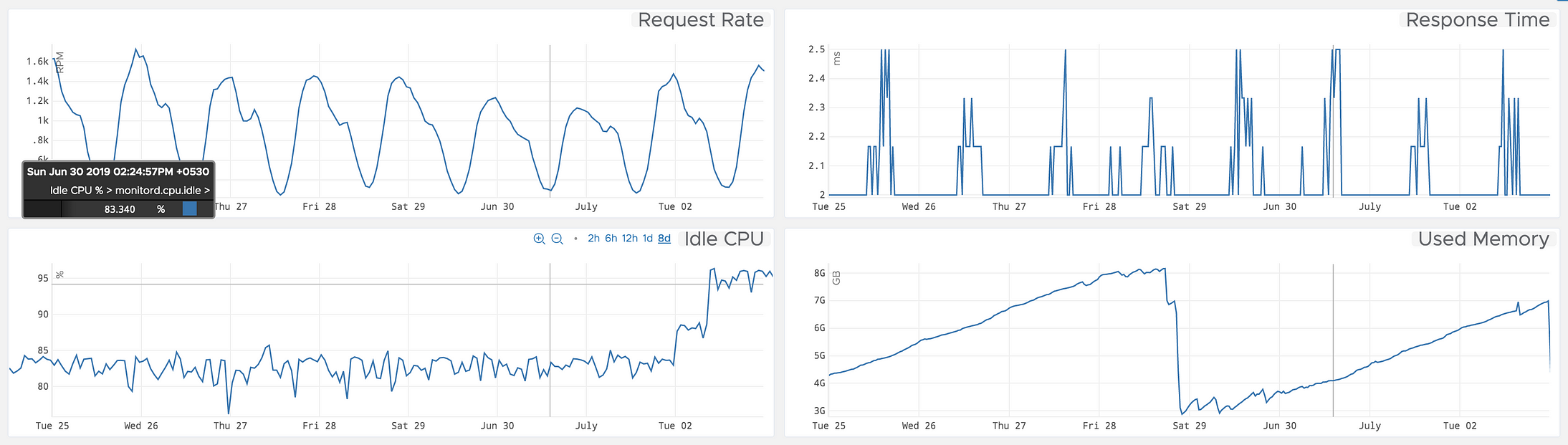
时间序列是以固定时间间隔收集的数据点的集合。时间序列数据的示例可以从应用程序指标(如以RPM为单位的请求速率)到系统指标(如以固定时间间隔获取的空闲CPU%)不等。
为了利用机器学习技术解决预测问题,需要将数据转换为时间序列格式。时间序列数据具有自然的时间顺序。时间序列分析可以应用于实值、连续数据、离散数值数据或离散符号数据。
为了便于说明,我使用了Python。Numpy、Pandas、Matpoltlib模块将用于转换和分析,Statsmodel将用于预测模型。
import pandas as pd
dateparse = lambda dates: pd.to_datetime(dates, unit = 's')
df = pd.read_csv('ServiceEndpointRpm.csv', parse_dates =
['epoch'], index_col = 'epoch', date_parser = dateparse)
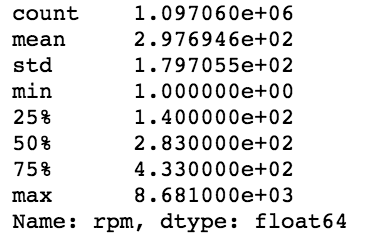
df.describe()
Statistics of Request Rate data
df.tail()

Few data points of time series
import matplotlib.pylab as plt
ts = df["rpm"]
plt.title(label="Service Requests per Minute Graph",
fontsize=32)
plt.plot(ts)
plt.xlabel("Time", fontsize=20)
plt.ylabel("Requests per Minute", fontsize=20)
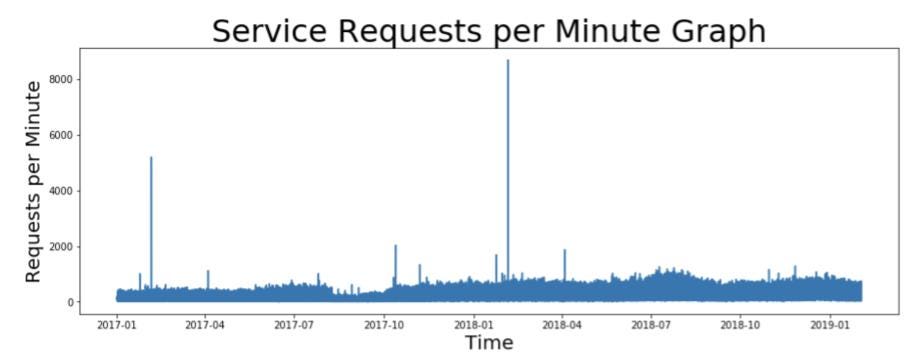
Time series graph representing request rates (in RPM) for a web service taken at every minute of interval.
数据预处理
请看上面RPM中的请求率图表,您是否看到数据存在任何挑战? 在上图中,您可以看到有太多的数据点和尖峰需要处理。 如何处理? *重采样:每隔一分钟采集所有数据点。将数据重新采样为每小时、 每天或每周有助于减少需要处理的数据点的数量。在本例中, 我们将使用平均每日重采样值。 *变换:可以应用对数、平方根或立方根等变换来处理图形中的峰值。 在本例中,我们将对时间序列执行日志转换。
ts_1d = ts.resample('D', closed='right', label='left').mean()
plt.title(label="Service Requests per Minute Graph", fontsize=32)
plt.plot(ts_1d)
plt.xlabel("Time", fontsize=20)
plt.ylabel("Requests per Minute", fontsize=20)

Observe that large number of data points have reduced and the graph looks smoother as a result of daily resampling.
import numpy as np
ts_1d_log = np.log(ts_1d)
plt.title("Log Transformed RPM Data for Service",
fontsize=32)
plt.xlabel("Time (in Days)", fontsize=20)
plt.ylabel("Logarithm of RPM", fontsize=20)
plt.plot(ts_1d_log)
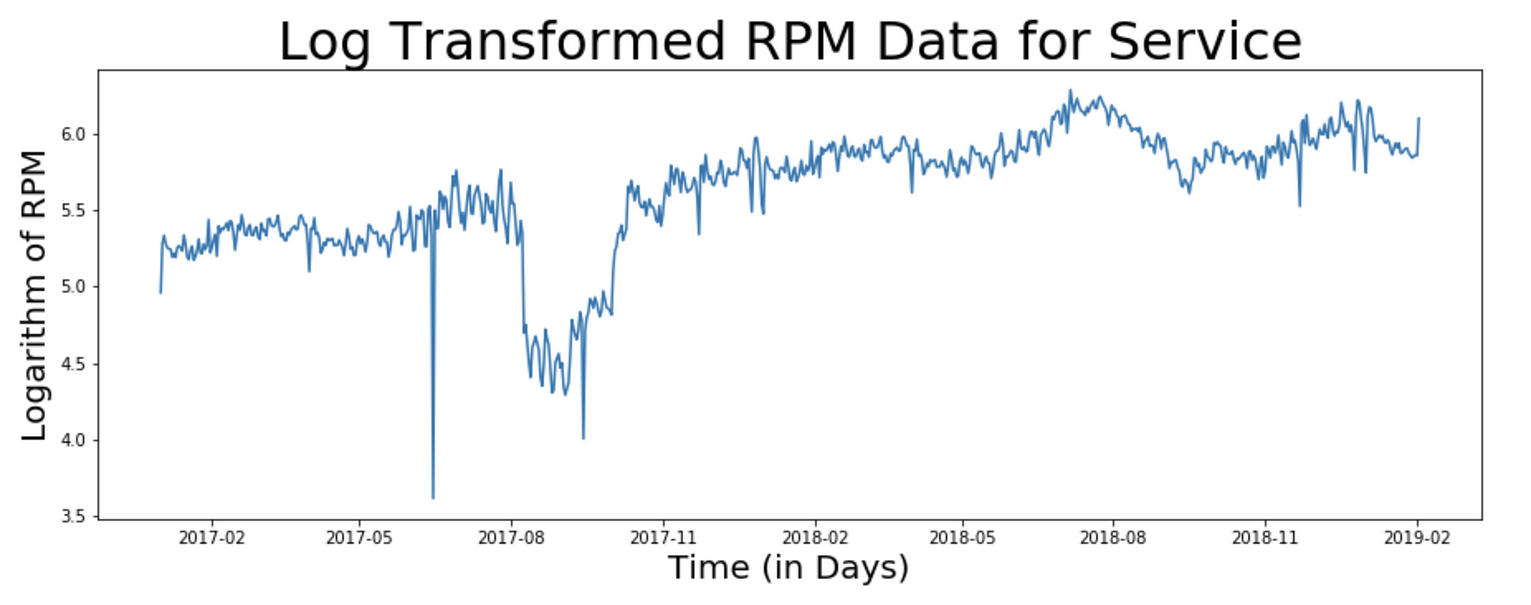
Observe the values on the y-axis as a result of log transformation
时间序列基础
单变量与多变量时间序列
单变量时间序列数据仅由一个变量组成。单变量分析是数据分析的最简单形式,所分析的数据只包含一个变量。因为它是一个单一变量,所以它不处理原因或关系。这种单变量时间序列的一个例子是请求速率度量。
当时间序列由两个变量组成时,它被称为二元时间序列。对这类数据的分析涉及原因和关系,分析的目的是找出这两个变量之间的关系。例如,web服务的CPU使用率为%,这取决于请求速率。这些变量通常绘制在图形的X轴和Y轴上,以便更好地理解数据,其中一个变量是独立的,而另一个是相关的。
多元时间序列由三个或更多变量组成。多变量时间序列的例子可以是依赖于多个变量的股票价格。
时间序列的组成部分
为了找到一个合适的时间序列预测模型,了解时间序列数据的组成部分非常重要。时间序列数据主要由以下部分组成:
趋势
趋势显示数据在长时间内增加或减少的总体趋势。趋势是一种平稳的、普遍的、长期的、平均的趋势。在给定的时间段内,增加或减少的方向并不总是相同的。web服务的请求率可能在很长一段时间内表现出某种移动趋势。
季节性
这些是由于季节性因素而在数据中出现的短期变动。短期通常被认为是一个时间序列发生变化的时期。电子商务网络服务在某些月份可能会收到更多的流量。
周期
这些是发生在时间序列中的长期振荡。
错误
这些是时间序列中的随机或不规则运动。这些是时间序列中发生的不太可能重复的突然变化。
加法与乘法模型
简单分解模型可以是: 加性模型:Y[t]=t[t]+S[t]+e[t] 乘法模型:Y[t]=t[t]*S[t]*e[t] 其中,Y[t]是时间't'的预测值,t[t],S[t]和e[t]分别 是时间't'的趋势分量、季节分量和误差。
from statsmodels.tsa.seasonal import seasonal_decompose
def seasonal_decompose_analysis(timeseries, model, periods):
decomposition = seasonal_decompose(timeseries,
model = model, freq = periods)
trend = decomposition.trend
seasonal = decomposition.seasonal
residual = decomposition.resid
plt.subplot(411)
plt.title('Original', fontsize=20)
plt.plot(timeseries, label='Original')
plt.subplot(412)
plt.title('Trend', fontsize=20)
plt.plot(trend, label='Trend')
plt.subplot(413)
plt.title('Seasonality', fontsize=20)
plt.plot(seasonal,label='Seasonality')
plt.subplot(414)
plt.title('Residuals', fontsize=20)
plt.plot(residual, label='Residuals')
plt.tight_layout()
return decomposition
seasonal_decompose_analysis(ts_1d, 'additive', 365)
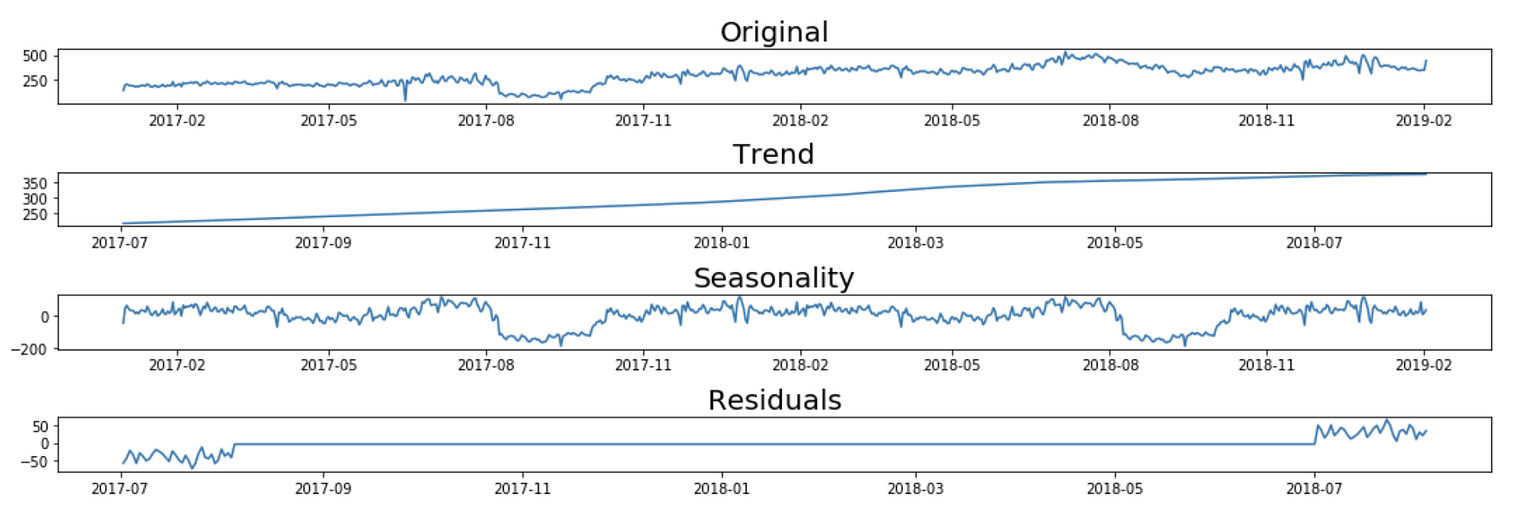
Additive Decomposition Model for time series
seasonal_decompose_analysis(ts_1d, 'multiplicative', 365)
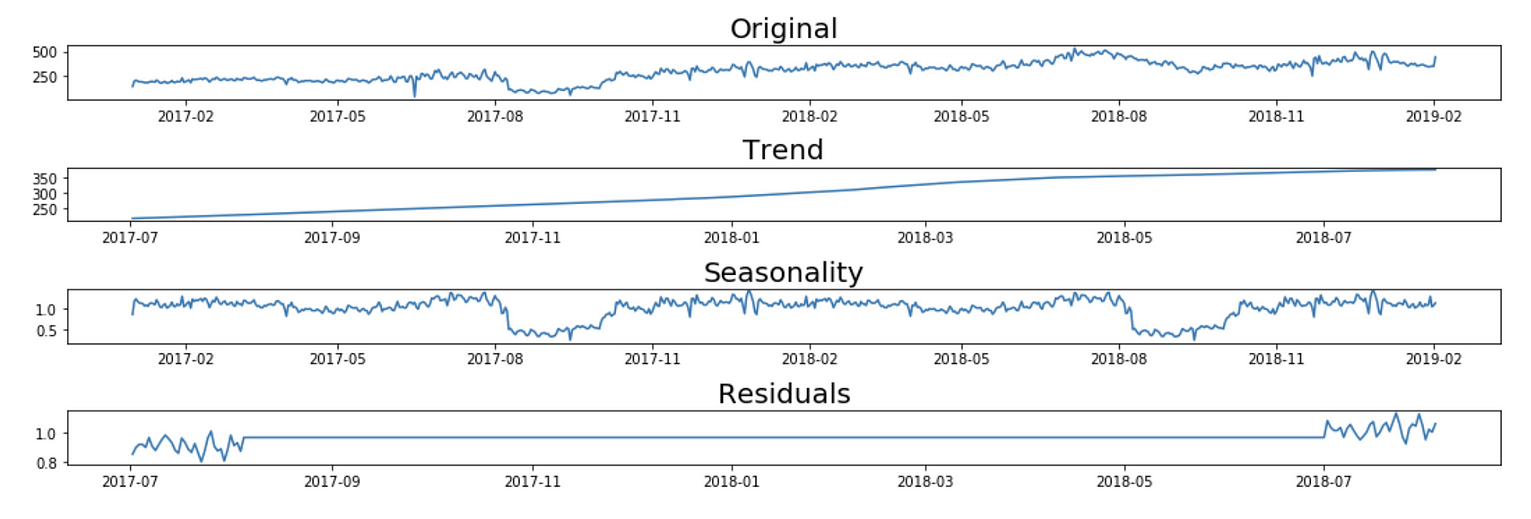
Multiplicative Decomposition Model for time series
平稳序列
如果时间序列在一段时间内具有恒定的统计特性,则称其为平稳的,即:
- 常均值
- 恒定方差
- 不依赖于时间的自协方差。
大多数时间序列模型要求时间序列是平稳的。
如何检查时间序列的平稳性?
以下是检查时间序列平稳性的一些方法:
滚动统计
我们可以绘制移动平均值或移动方差来检查随时间的变化。例如,7天内每分钟请求的滚动平均值。这是一种视觉技术。
富勒检验(Dickey-Fuller Test)
这是检查平稳性的统计测试之一。这是一种单位根测试。测试结果包括一个测试统计量和一些不同置信水平的临界值。如果“检验统计量”小于“临界值”,我们可以拒绝零假设,并说序列是平稳的。这里的零假设是时间序列是非平稳的。
from statsmodels.tsa.stattools import adfuller
def stationarity_test(timeseries, rolling_window):
rolling_mean = pd.rolling_mean(timeseries,
window=rolling_window)
rolling_std = pd.rolling_std(timeseries,
window=rolling_window)
orig = plt.plot(timeseries, color='blue',
label= 'Original')
mean = plt.plot(rolling_mean, color='red',
label= 'Rolling Mean')
std = plt.plot(rolling_std, color='black',
label = 'Rolling Std')
plt.title('Rolling Mean & Standard Deviation')
plt.show()
# Dickey-Fuller test
print('Results of Dickey-Fuller Test')
test = adfuller(timeseries, autolag='AIC')
output = pd.Series(test[0:4], index=['Test
Statistic','p-value',
'#Lags Used','Number of Observations Used'])
for key,value in test[4].items():
output['Critical Value (%s)'%key] = value
print(output)
stationarity_test(timeseries = ts_1d,
rolling_window = 365)
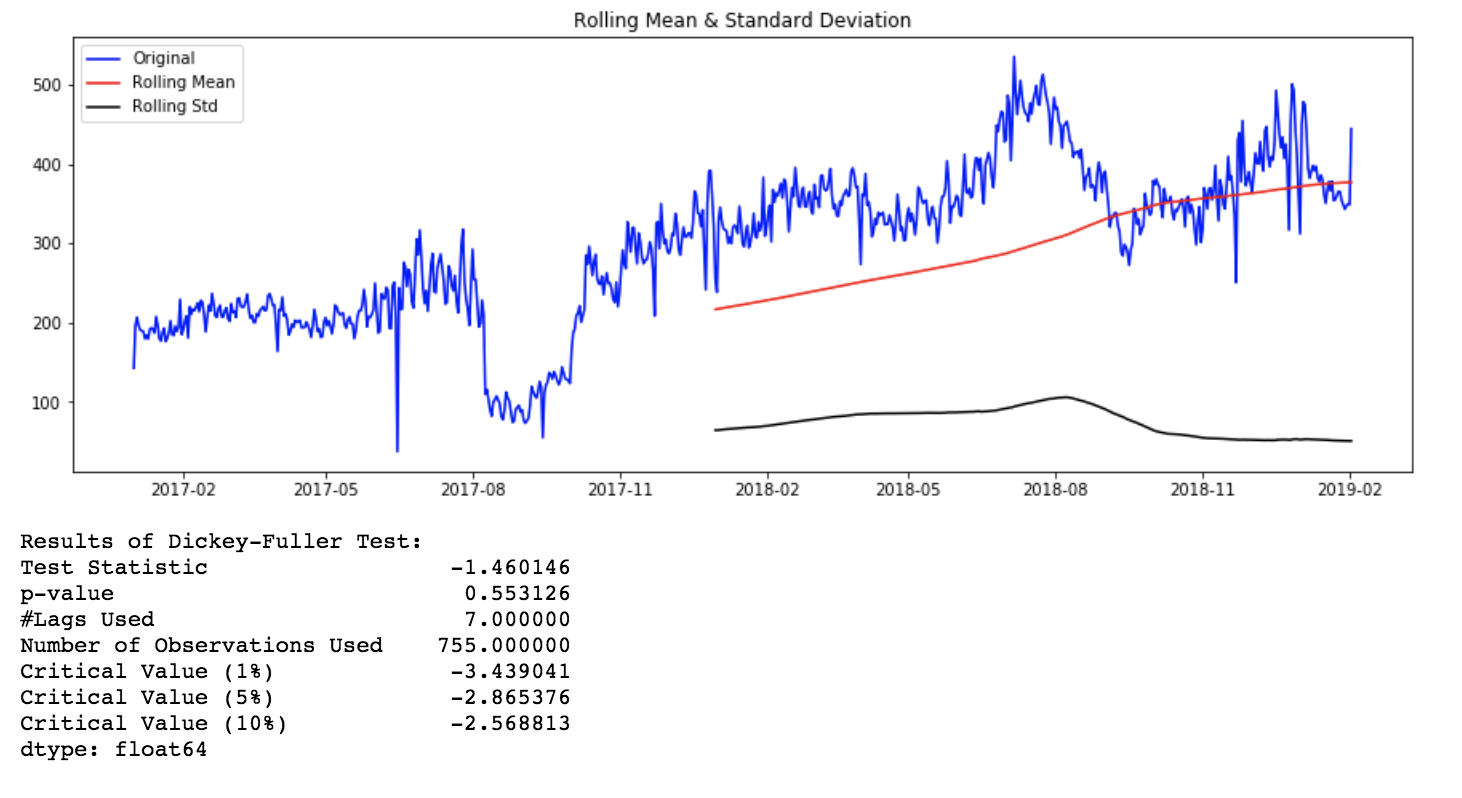
Rolling Stats Plot and AD Fuller Test results for original time series
如何使时间序列保持平稳?
有多种方法可以使时间序列保持平稳。其中有些是差分、去趋势化、变换等。
stationarity_test(timeseries = ts_1d_log_diff_1.dropna(), rolling_window = 365)
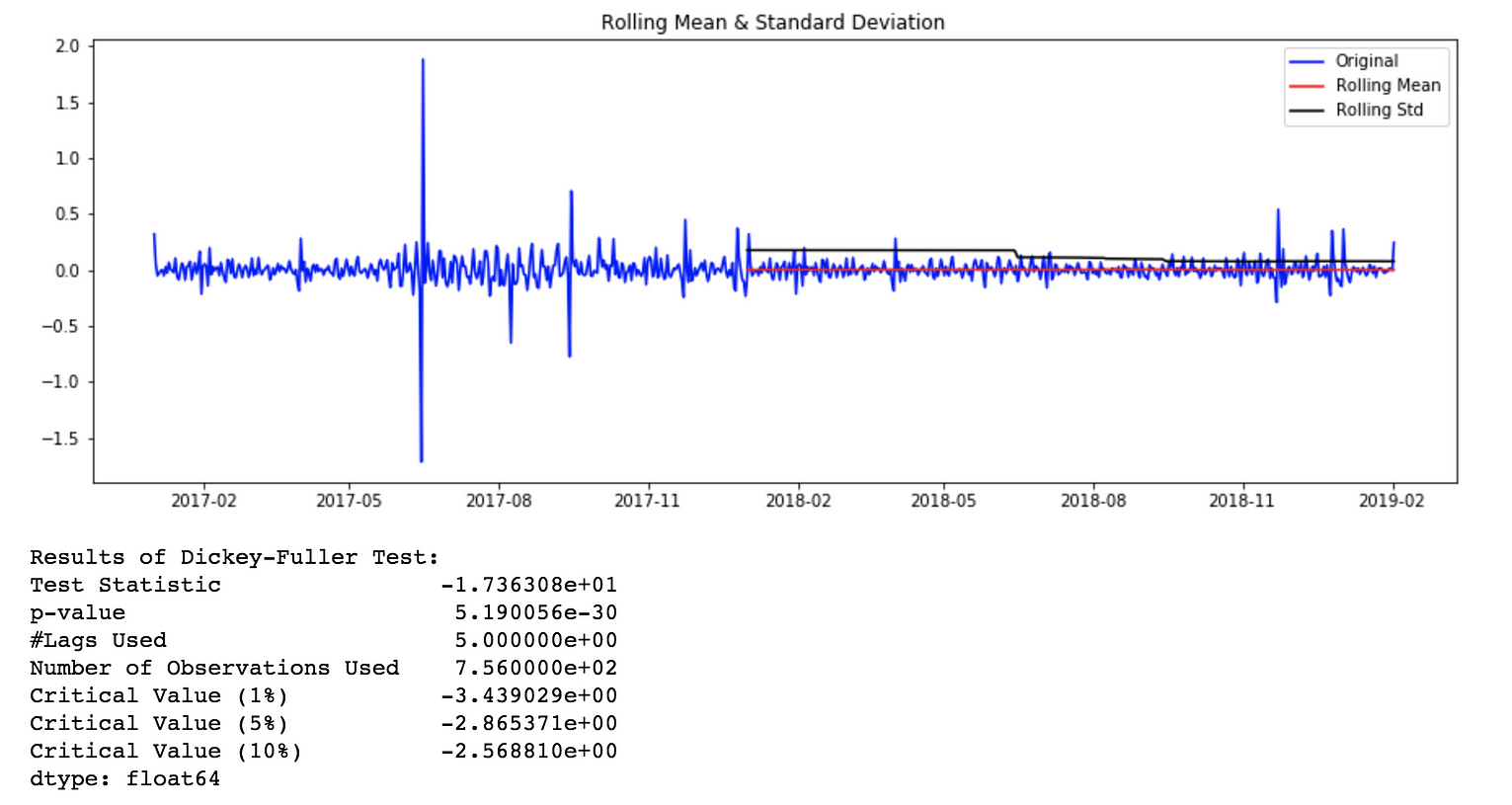
Rolling Stats Plot and AD Fuller Test results for log transformed and differenced time series.
模型拟合与评价
我将广泛讨论两种预测模型,数学模型和人工神经网络。
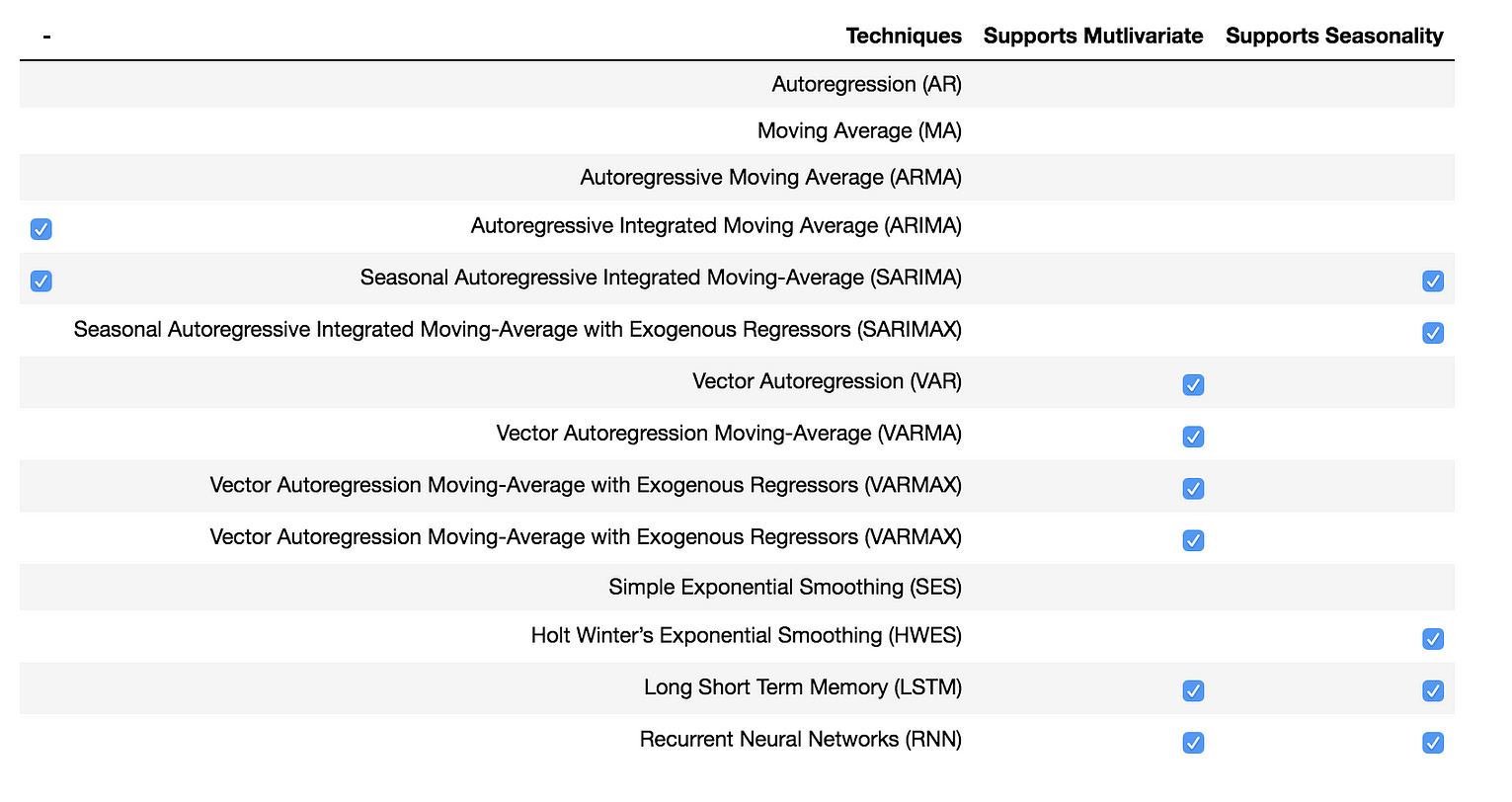
Predictive Models
数学模型
下面将介绍一些经典的时间序列预测模型。我将为我们的场景演示SARIMA模型。
AR、MA、ARMA、ARIMA等模型都是SARIMA模型的简单例子。VAR、VARMA、VARMAX与前面提到的模型类似,它们适用于向量数据而不是单变量时间序列。
在某些情况下,霍尔特-温特模型可用于预测存在季节性成分的时间序列。
萨里玛模型(SARIMA Model)
当时间序列中存在趋势和季节性时,非常流行的方法是使用季节性自回归综合移动平均(SARIMA)模型,该模型是ARMA模型的推广。
SARIMA模型由SARIMA(p,d,q)(p,d,q)[S]表示,其中
- p、 q指ARMA模型的自回归和移动平均项
- d是差异程度(减去数据过去值的次数)
- P、 D和Q是指ARIMA模型季节部分的自回归、差分和移动平均项。
- S指每个季节的时段数
模型参数估计
*对于SARIMA(p,d,q)(p,d,q)[S]模型,我们需要估计7个参数。 *从季节分解可以看出,时间序列数据具有季节性。因此,S=365, 表示季节变化滞后365天。 *对于p、q、p&q参数,我们可以绘制ACF(自相关函数)和PACF(偏自相关函数), 对于参数d&d,我们可以尝试绘制相同的曲线图,但时间序列不同。
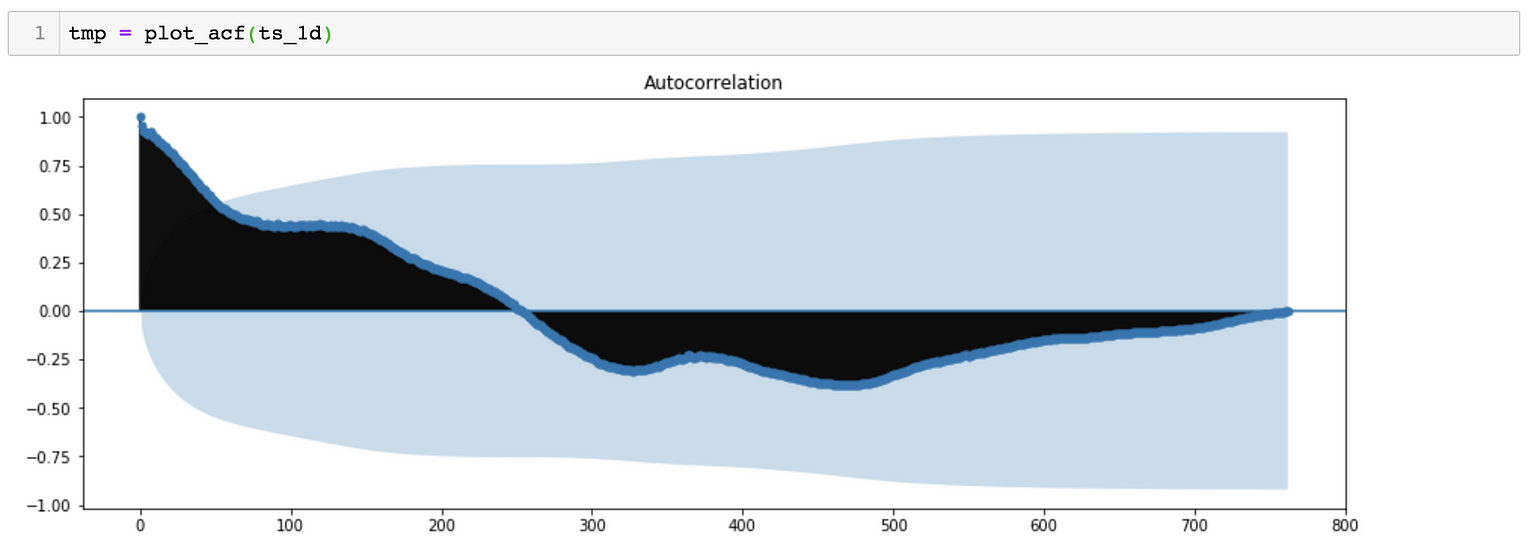
ACF Plot suggests a possibility of P = 0 and D = 0
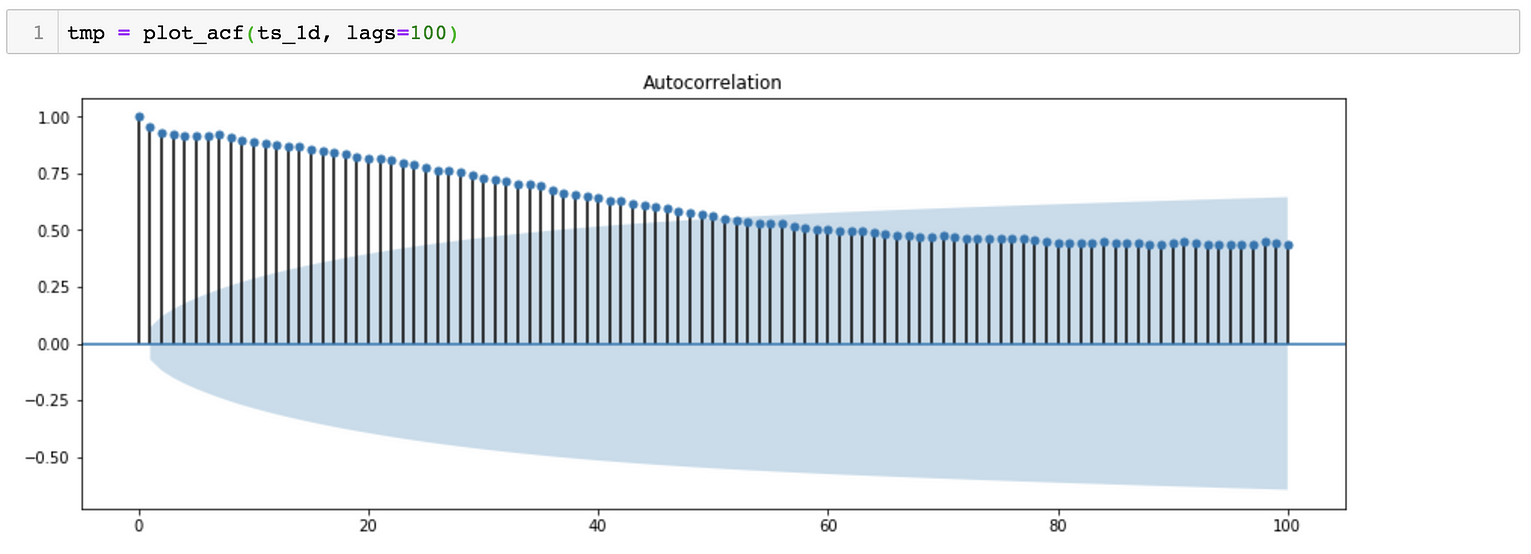
ACF Plot suggests a possibility of p ~ 43 and d = 0
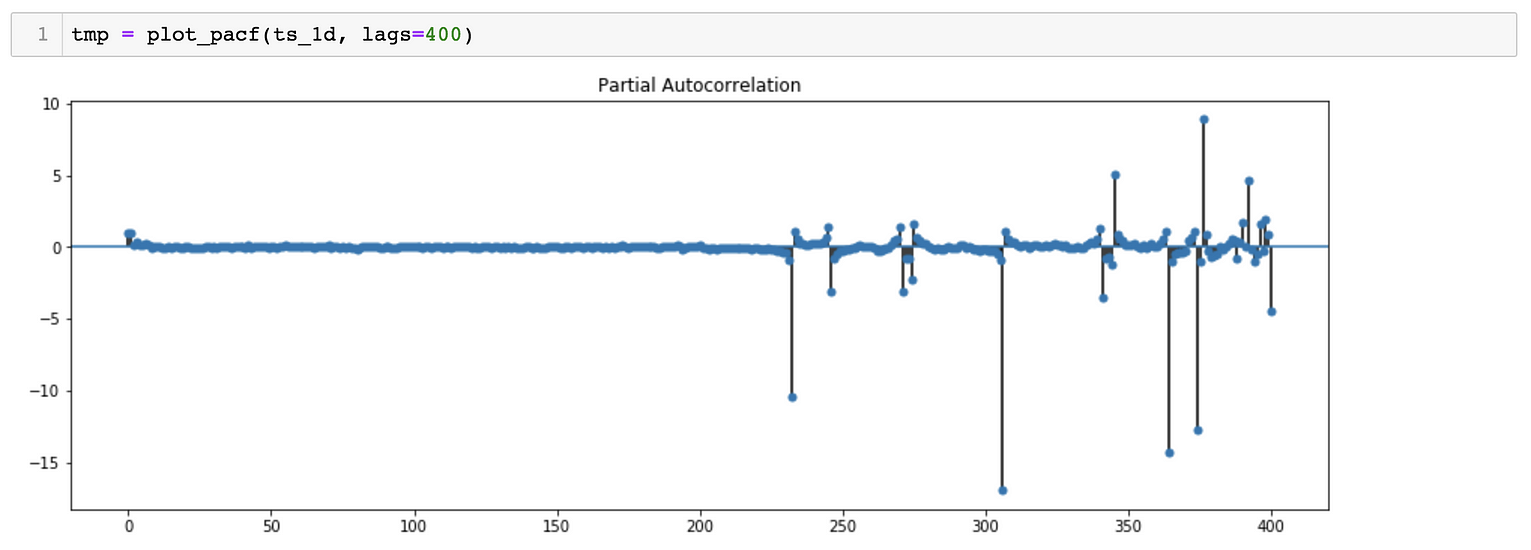
PACF Plot suggests a possibility of Q = 0 and D = 0
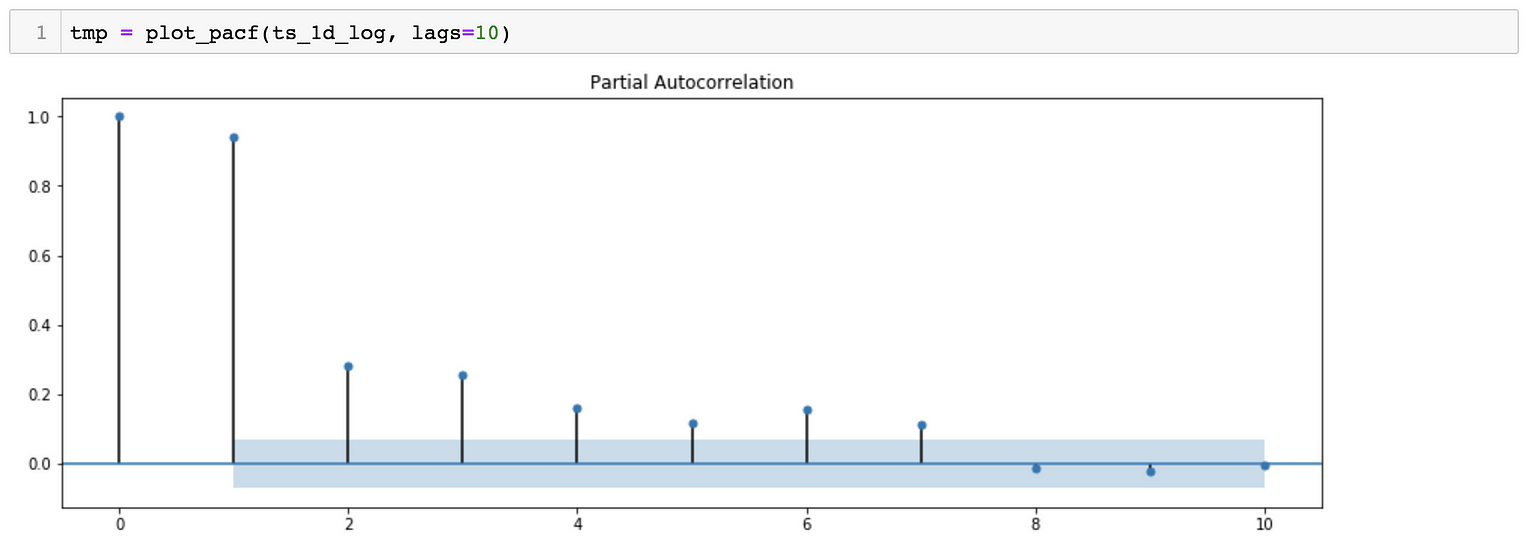
PACF Plot suggests a possibility of q ~ 7 and d = 0
*估计参数的另一种方法是尝试多组值,以找到AIC(Akaike信息标准)值相对较小的模型。
*该模型的估计参数为:SARIMA(2,1,4)(0,1,0)[365]
训练和测试数据集分割
与其他机器学习模型一样,为了评估模型的准确性,我们将数据集分为训练数据集和测试数据集。这一比率可能在60%到90%之间变化。在我们的例子中,由于数据点的数量较少,我将保持95%的比率。保持比率为95%的另一个原因是,为了使SARIMA模型能够准确预测,训练数据集应该有足够的两个季节的数据点。
t_ratio = 0.95
t_size = int(len(ts_1d_log) * t_ratio)
train_1d_log, test_1d_log = ts_1d_log[:t_size].asfreq('D'),
ts_1d_log[t_size:].asfreq('D')
print("Original Data Length =", len(ts_1d_log))
print("Training Data Length =", len(train_1d_log))
print("Test Data Length =", len(test_1d_log))
# Original Data Length = 763
# Training Data Length = 724
# Test Data Length = 39
Model will be trained with 2 years data and tested with 39 days data.
模型拟合
拟合的数据是每日平均重采样和对数转换的时间序列。为模型调用估计参数(2,1,4)(0,1,0)[365]。观察此型号的AIC值为-296.90。
import statsmodels.api as sm
sarima_model = sm.tsa.statespace.SARIMAX(train_1d_log,
order=(2, 1, 4),
seasonal_order=(0, 1, 0, 365),
enforce_invertibility=False,
enforce_stationarity=False)
result_sarima = sarima_model.fit()
print('SARIMA - AIC : {}'.format(result_sarima.aic))
# SARIMA - AIC : -296.90534927970805
预测
既然模型经过训练,我们就可以进行预测了。为此,我们可以提供要预测的步数作为参数。
pred_sarima = result_sarima.predict(start=0, end=800)
plt.title('Model Fitting and Forecasting', fontsize=32)
plt.xlabel('Future Time (in Days)', fontsize=20)
plt.ylabel('Predicted Avg. Daily RPM', fontsize=20)
plt.plot(train_1d_log, label='Training')
plt.legend(loc='best')
plt.plot(test_1d_log, label='Test')
plt.legend(loc='best')
plt.plot(pred_sarima['2018-12-26':'2019-02-02'], label='Predicted')
plt.legend(loc='best')
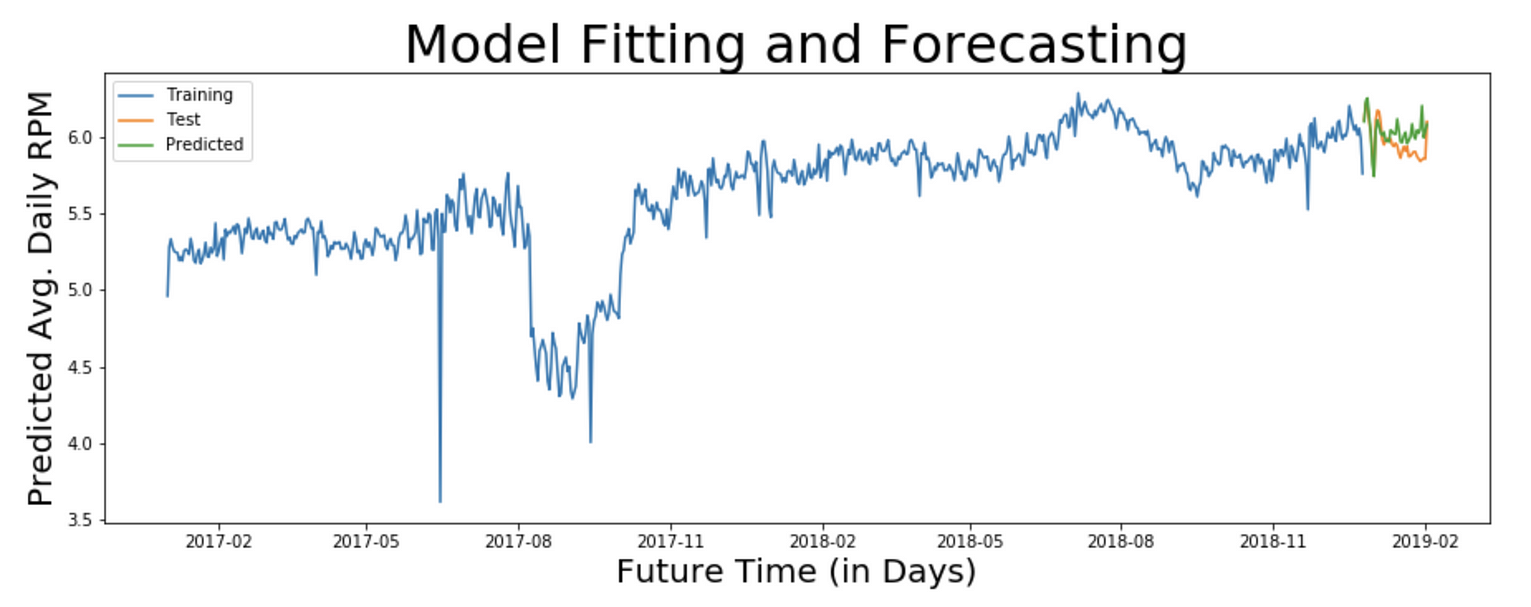
Graph showing Training, Test and Predicted values for Average Daily and Log Transformed RPM values for the service.
注:观察本文开头原始图表和上述预测图表中y轴上的值。web服务的RPM值约为300,预测值约为5,这是因为预测值经过转换。我们需要应用逆变换来获得原始尺度上的值。根据我们应用的变换,你能猜出哪个逆变换是合适的吗?
基于应用的对数变换,我们需要应用指数变换进行反演。在评估预测之前需要这样做,因为我们需要知道原始尺度上预测值的准确性。
验证预测
现在,我们已经将预测值反变换回原始比例,我们可以评估预测模型的准确性。
为此,我们需要找到原始测试值和预测测试值之间的误差,以计算:
- *均方误差(MSE)
- *均方根误差(RMSE)
- *变异系数
- *四分位分散系数等
由于我们的数据集只有39个数据点,我们将能够评估39天的预测。让我们对模型进行39天和20天的评估,以比较结果。
39天预测
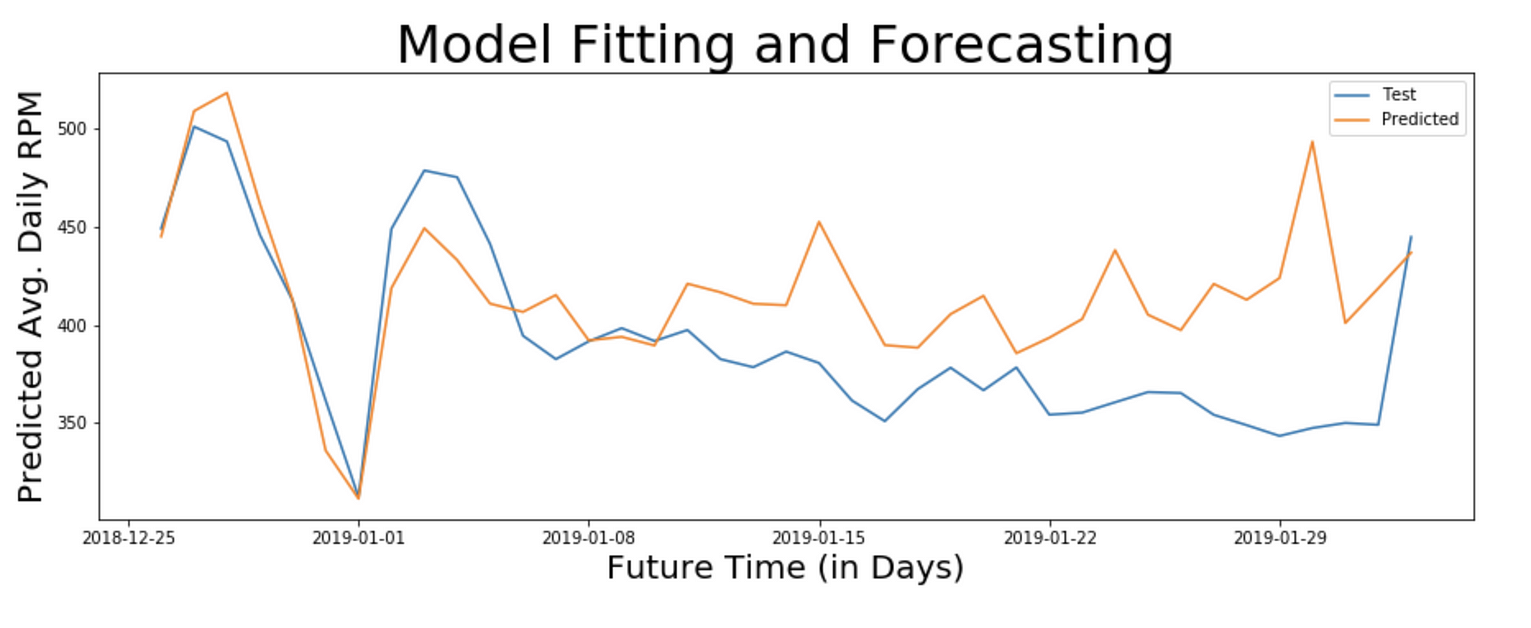
Actual and Predicted RPM for 39 days
mse_38d = mean_squared_error(np.exp(test_1d_log),
np.exp(pred_sarima_214_010_365_1d_log['2018-12-26':'2019-02-02']))
rmse_38d = np.sqrt(mse_38d)
cov_38d = rmse_38d / (np.exp(test_1d_log)).mean() * 100
print ("Mean Squared Error (MSE) =", mse_38d)
print ("Root Mean Squared Error (RMSE) =", rmse_38d)
print ("Coefficient of Variation =", cov_38d, "%")
# Mean Squared Error (MSE) = 2071.720645305662
# Root Mean Squared Error (RMSE) = 45.51615806837899
# Coefficient of Variation = 11.645373540724746 %
注:变异系数为11.645,这意味着该模型能够预测未来39天服务的日平均RPM,准确率为88%。
20天预测
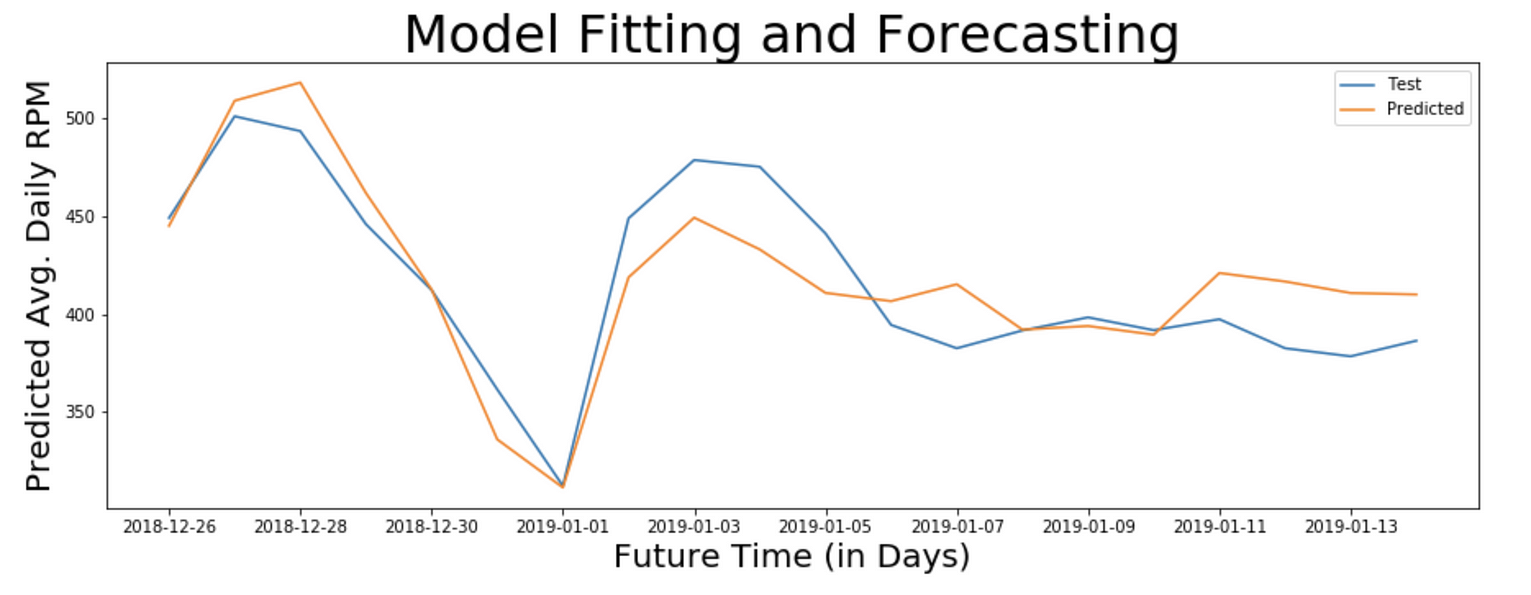
Actual and Predicted RPM for 20 days
mse_20d = mean_squared_error(np.exp(test_1d_log[0:20]),
np.exp(pred_sarima_214_010_365_1d_log['2018-12-26':'2019-01-14']))
rmse_20d = np.sqrt(mse_20d)
cov_20d = rmse_20d / (np.exp(test_1d_log[0:20])).mean() * 100
print ("Mean Squared Error (MSE) =", mse_20d)
print ("Root Mean Squared Error (RMSE) =", rmse_20d)
print ("Coefficient of Variation =", cov_20d, "%")
# Mean Squared Error (MSE) = 533.8336605253844
# Root Mean Squared Error (RMSE) = 23.10484062973351
# Coefficient of Variation = 5.552258462827946 %
注:变异系数为5.55,这意味着该模型能够预测未来20天服务的日平均RPM,精确度为94%。
神经网络
基于预测的问题的神经网络模型与数学模型的工作方式不同。递归神经网络(RNN)是一类具有时间动态特性的人工神经网络。
LSTM(长-短期记忆)是最合适的RNN之一。为了发展LSTM模型,必须将时间序列预测问题重新定义为监督学习问题。
结论
- 为了预测某些指标,如web服务的响应时间,需要非常有效的模型来预测实时时间序列数据。
- 每个度量都有与其相关联的时间步长的适当粒度。对于预测响应时间,合适的时间步长粒度为秒或分钟。而对于自动缩放,预测每日RPM就足够了。
- 在预测涉及多变量时间序列(如CPU使用率%或磁盘交换)的复杂指标时,应选择适当的模型,因为它可能不是单变量时间序列,且多个变量必须影响其值。
- 为预测一个指标而开发的预测模型可能不适用于另一个指标。
- 通过使用更大的数据集对模型进行训练并微调模型参数,可以提高模型的精度。
进一步阅读
- 要了解本文中提到的其他时间序列预测模型的更多信息,您可以阅读Winter Holt和LSTM。
- 要了解多变量时间序列的时间序列分析,请阅读Granger因果关系检验。
- 对于ACF和PACF图,请参考自相关和偏自相关。
- To know more about other time series prediction models mentioned in this article you can read Winter-Holt and LSTM.
- To understand time series analysis of multi-variate time series, read up on Granger Causality test.
- For ACF and PACF Plots refer to Autocorrelation and Partial Autocorrelation.
原文:https://towardsdatascience.com/time-series-analysis-and-forecasting-of-…
- 55 次浏览
【数据分析】什么是描述性分析?
QQ群
视频号
微信
微信公众号
知识星球
描述性分析是一种统计解释,用于分析历史数据,以确定模式和关系。描述性分析试图描述一个事件、现象或结果。它有助于了解过去发生的事情,并为企业跟踪趋势提供完美的基础。

描述性分析就是在数据中寻找意义。数据需要上下文:分析提供了在何时何地将数据转化为可衡量的模式。
作为数据分析的一种形式,描述性分析是数据分析的四种关键类型之一。其他是诊断分析、预测分析和规定分析。
四种类型的分析如何协同工作
从一般意义上讲,分析就是发现数据中的模式,并将这些趋势传达给各个利益相关者。在处理丰富的记录数据时,分析使用统计、编程和运营研究来验证数据性能。分析有四种基本类型——描述性、诊断性、预测性和规定性。
组织通常将描述性分析和其他形式结合起来,以更全面地了解公司的业绩。描述性分析总结和解释历史数据,而其他分析论文则研究趋势和未来结果背后的原因。除了人类驱动的分析之外,这个过程还可能利用机器学习自动发现数据中的模式和连接。
诊断分析检查事情为什么会以这种方式发生,诊断问题或根本原因。它试图确定描述性分析之前可能发现的趋势和异常的原因。诊断分析可以通过数据挖掘和关联等方法来实现这一点。
顾名思义,预测分析使用历史数据进行预测。它提供了对特定未来结果的概率和可能影响的预测。这使组织的管理层能够以积极主动、数据支持的方式进行决策。公司还可以利用预测分析来了解问题可能产生的影响。
最后,规定性分析利用描述性、诊断性和预测性分析的结果,为企业提供建议,以确保良好的潜在结果。
描述性分析提供了什么信息?
描述性分析可以应用于企业的各种日常运营活动。库存报告、各种工作流程、销售数据和收入统计数据都基于描述性分析。这些报告共同为一家公司提供了其运营的历史概览。可以收集此类语句中的数据,作为创建各种业务相关函数的特定快照的基础。
社会分析是创建此类快照的描述性分析的一个例子。对于社交媒体上发布的每一篇帖子,都可以对页面的关注者、帖子获得的点赞、互动评论、页面浏览量和可用响应时间进行分析。所有这些因素都确定了页面对目标受众的影响,并且在汇总时,将重点关注任何差距或需要改进的领域。它有助于更好地理解消费者的态度。
然而,必须理解的是,描述性分析只确定模式,而不会超越表面数据分析。他们不会做出推论或做出预测。虽然年度收入销售报告可能显示企业今年盈利,但管理层需要其他方法将其与前几年的账目进行比较,以了解该利润是高于还是低于前几年。这样的比较将有助于组织得出一个趋势。
描述性分析是如何工作的?
为了使描述性分析发挥作用,组织首先需要创建一组衡量业务绩效和业务目标的指标。例如,制造业企业可能会出现原材料价格同比变化或月度收入增长指标。科技公司可能会检查他们每月增加了多少用户,或者他们创建了多少技术升级。有了必要的衡量标准,就必须收集相关数据。然后必须对其进行管理、清理,并为下一步数据分析做好准备。
描述性分析的历史数据收集使用两种主要技术——数据聚合和数据挖掘。公司通过数据聚合将数据收集并组织到可管理的数据集中。收集的数据使用各种工具和方法进行分析,如汇总统计或模式跟踪。分析师利用这些数据来研究数据,发现模式,进而发现性能。
公司如何使用描述性分析的示例:
- 描述性分析的一些结果包括创建与销售、收入和工作流程相关的广泛报告,包括库存报告
- 基于多种指标,从各种平台深入了解社交媒体的使用及其参与度
- 已结束的事件摘要,如营销活动、运营数据、与销售相关的可衡量指标
- 调查结果整理
- 关于总体趋势的报告
这种形式的分析对于评估学习者的数据以从培训计划中创造更好的结果非常宝贵。
例如,当多国董事会举行数字会议时,描述性分析可以确定有多少成员是讨论的积极参与者、互动水平以及有多少成员被发布在讨论论坛上。另一个例子是报告财务指标,如定价的同比变化、月度销售额增长(或下降)数字和订户收入。这些数据基于固定业务期间内发生的情况。
如何将描述性分析应用于组织
理解描述性分析的基本原理似乎很简单,但在现实生活中应用它可能很有挑战性。组织需要遵循以下几个步骤才能将描述性分析应用于其业务。
确定相关指标
首先,组织需要知道要创建的度量。这些指标应该反映公司或组织每个部门的主要业务目标。管理层可能希望从季度角度看待增长,或者可能需要跟踪未付款项以了解延迟情况。识别各种数据度量是第一步。
如果这一步骤没有经过一些考虑就完成了,那么结果将毫无帮助。组织需要了解什么是可衡量的,如何收集适当的数据,以及它是否适用。
营销和销售部门就是一个例子;销售代表将跟踪每月的销售收入。会计会想检查财务指标,如毛利率。
确定支持这些指标的数据
下一步是找到支持所需指标所需的数据。这些数据可以在一些组织的多个siloe和文件中找到。如果一个组织已经使用企业资源规划(ERP)系统,那么所需的大部分数据可能已经在公司内部。确定所需的任何外部来源,特别是与行业基准、非公司数据库、电子商务网站和许多社交媒体网站相关的来源。
数据提取和准备
如果一个组织跨多个数据源工作,则需要提取数据、合并数据,并为分析做好准备,以确保一致性。这是一个旷日持久的过程,但对准确性至关重要。数据清理是去除冗余和错误,并以适合分析的格式创建数据的一部分。
数据分析
有几种工具可用于提供描述性分析。这些可以从基本的电子表格到各种更复杂的商业智能(BI)软件。这些可以是基于云的、现场的。这些程序使用各种算法来创建对所提供数据的准确摘要和见解。
数据展示
描述性分析的最后一个方面是呈现数据。这通常是使用可视化技术来完成的,通过引人注目和令人兴奋的演示形式,让用户可以访问数据以理解。条形图、饼图和折线图等选项显示信息。虽然这样一个视觉上吸引人的演示是一些部门喜欢他们的知识的方式,但金融专业人士可能会选择表格和数字中的数据。应为最终用户提供便利。
描述性分析的好处
描述性分析有几个好处。
简单分析
描述性分析不需要统计学方法或分析方面的专业知识或经验。
许多可用工具
许多应用程序将此功能作为一种即插即用的分析形式。
它回答了最常见的业务绩效问题
大多数利益相关者和销售人员都希望简单回答基本问题,如“我们过得怎么样?”或“为什么销售额下降?”描述性分析提供了有效回答这些问题的数据。
描述性分析面临的挑战
与任何其他工具一样,描述性分析也并非没有问题。对于想要使用描述性分析的组织来说,有三个重大挑战。
它是一个没有洞察力的生硬工具
描述性分析考察了少数变量之间的关系,仅此而已。它简单地描述了正在发生的事情。组织必须确保用户了解描述性分析将提供什么。
它告诉一个组织什么,而不是为什么
描述性分析报告事件发生的情况,而不是事件发生的原因或接下来可能发生的事情。组织将需要完全运行完整的分析套件来掌握情况。
可以测量错误的东西
如果使用了不正确的度量,则分析是无用的。组织必须分析他们想要衡量的内容以及原因。必须将思想融入这一过程,并与当前数据所能提供的结果相匹配。
数据质量差
虽然可以收集大量的数据,但如果没有帮助或充满错误,就不会产生准确的结果。在组织决定了所需的指标后,必须对数据进行检查,以确保它能够提供这些信息。一旦确定它将提供相关信息,就必须彻底清理数据。必须解决错误数据、重复数据和丢失的数据字段。
未来数据分析中的描述性分析
从销售和财务到改善供应链,企业越来越成为数据驱动型企业,使用描述性分析的结果进行优化或商业实践。未来的预测是,数据分析将脱离预测分析,转向规范分析。
数据分析的理想用途是描述已经发生的事情,并准确预测未来。以GPS导航系统为例。描述性分析评估以前的交付路线、所用时间和燃料使用情况。然而,它没有预测未来最快的路线、提高速度的方法或如何减少燃料使用。
为此,组织需要使用预测分析。比简单的描述性分析更进一步,将为组织提供最佳的交付方向。使用规范性分析可以帮助比较多条旅行路线,并为驾驶员、道路或一天中的时间提出最佳路线。
描述性分析是企业用来理解其收集的大量历史数据含义的基本技术。这是一种有助于监控趋势和性能的技术,同时跟踪关键性能指标和您缩小范围的任何其他指标。然而,这是一个简单的工具,应该被视为过程中的一个步骤,而不是最终目标。为了获得最佳结果,组织必须在预测、诊断和规定分析的同时使用描述性分析,以获得更深刻的见解、准确的预测,以及如何改进结果。
- 93 次浏览
【数据分析】什么是描述性分析?5个示例
QQ群
视频号
微信
微信公众号
知识星球
对于旨在增加收入、改进产品和留住客户的企业来说,数据分析是一种有价值的工具。根据全球管理咨询公司麦肯锡公司的研究,使用数据分析的公司在获得新客户方面比非数据驱动的公司更有可能超越竞争对手23倍。在客户忠诚度方面,他们超过他们的可能性是他们的9倍,实现高于平均水平盈利的可能性是其他公司的19倍。
数据分析可分为四种关键类型:
- 描述性,回答问题“发生了什么?”
- 诊断,它回答了一个问题,“为什么会发生这种情况?”
- 预测,它回答了“未来可能发生什么?”
- 规定性的,它回答了“我们下一步应该做什么?”
每种类型的数据分析都可以帮助您实现特定目标,并协同使用来创建数据的全貌,为您的组织的战略制定和决策提供信息。
描述性分析可以单独使用,也可以作为其他三种分析类型的基础。如果你是商业分析领域的新手,那么描述性分析是一个容易上手且值得入手的地方。
什么是描述性分析?
描述性分析是使用当前和历史数据来确定趋势和关系的过程。它有时被称为最简单的数据分析形式,因为它描述了趋势和关系,但没有深入挖掘。
描述性分析是相对可访问的,很可能是您的组织每天使用的东西。基本的统计软件,如Microsoft Excel或数据可视化工具,如Google Charts和Tableau,可以帮助解析数据,识别趋势和变量之间的关系,并直观地显示信息。
描述性分析对于传达随着时间的变化尤其有用,并将趋势作为进一步分析的跳板来推动决策。
以下是五个描述性分析的例子,可用于您的组织。
相关:专业人士的5项商业分析技能
描述性分析的5个例子
1.交通和参与报告
描述性分析的一个例子是报告。如果你的组织以社交媒体分析或网络流量的形式跟踪参与度,那么你已经在使用描述性分析了。
这些报告是通过获取用户与您的网站、广告或社交媒体内容交互时生成的原始数据来创建的,并使用这些数据将当前指标与历史指标进行比较并可视化趋势。
例如,您可能负责报告哪些媒体渠道为您公司网站的产品页面带来了最大的流量。使用描述性分析,您可以分析页面的流量数据,以确定每个来源的用户数量。您可以决定更进一步,将流量源数据与来自相同来源的历史数据进行比较。这可以让你更新你的团队的动态;例如,强调付费广告的流量同比增长了20%。
然后,可以使用其他三种分析类型来确定每个来源的流量随着时间的推移而增加或减少的原因,预测趋势是否会继续,以及团队的最佳行动方案是什么。
2.财务报表分析
你可能熟悉的描述性分析的另一个例子是财务报表分析。财务报表是一种定期报告,详细说明企业的财务信息,并综合反映公司的财务健康状况。
财务报表有几种类型,包括资产负债表、利润表、现金流量表和股东权益表。每一个都迎合了特定的受众,并传达了关于公司财务的不同信息。
财务报表分析可以通过三种主要方式进行:纵向、横向和比率。
垂直分析包括从上到下阅读一份声明,并将每个项目与上面和下面的项目进行比较。这有助于确定变量之间的关系。例如,如果每个行项目都占总数的一个百分比,那么比较它们可以深入了解哪些项目占总数的百分比越来越大。
横向分析包括从左到右阅读一份声明,并将每一项与前一时期的内容进行比较。这种类型的分析决定了随时间的变化。
最后,比率分析包括根据报告的一个部分与整体的关系将其与另一部分进行比较。这可以直接比较不同时期的项目,以及您公司与行业的比率,以衡量您公司的表现是过度还是表现不佳。
这些财务报表分析方法都是描述性分析的例子,因为它们提供了基于当前和历史数据的趋势和变量之间关系的信息。
3.需求趋势
描述性分析也可用于识别客户偏好和行为的趋势,并对特定产品或服务的需求做出假设。
流媒体提供商Netflix的趋势识别为描述性分析提供了一个极好的用例。Netflix的团队有着高度数据驱动的记录,他们收集用户在平台内行为的数据。他们分析这些数据,以确定哪些电视剧和电影在任何给定时间都在流行,并在平台主屏幕的一部分列出流行标题。
这些数据不仅让Netflix用户能够看到什么是受欢迎的,因此,他们可能喜欢看什么,而且让Netflix团队知道在某个时间段,哪些类型的媒体、主题和演员特别受欢迎。这可以推动有关未来原创内容创作、与现有制作公司签订合同、营销和重新定位活动的决策。
4.汇总调查结果
描述性分析在市场研究中也很有用。当需要从调查和焦点小组数据中收集见解时,描述性分析可以帮助识别变量和趋势之间的关系。
例如,你可以进行一项调查,发现随着受访者年龄的增长,他们购买你产品的可能性也会增加。如果你在几年内多次进行这项调查,描述性分析可以告诉你这种年龄购买相关性是否一直存在,或者是今年才发生的事情。
像这样的见解可以为诊断分析铺平道路,解释为什么某些因素是相关的。然后,您可以利用预测性和规范性分析,根据这些趋势规划未来的产品改进或营销活动。
5.实现目标的进展
最后,可以应用描述性分析来跟踪实现目标的进度。报告关键绩效指标(KPI)的进展情况可以帮助您的团队了解工作是否正在进行或是否需要进行调整。
例如,如果你的组织的目标是达到每月500000次的独特页面浏览量,你可以使用流量数据来沟通你是如何跟踪的。也许在这个月的一半,你的独特页面访问量达到了200000次。这将表现不佳,因为你希望在这一点上达到目标的一半——25万次独特的页面浏览量。这种对团队进度的描述性分析可以进行进一步的分析,以检查可以采取哪些不同的措施来提高流量,并回到实现KPI的轨道上。
利用数据识别关系和趋势
哈佛商学院教授Jan Hammond在在线课程《商业分析》中表示:“以前从未有过每天每秒都会收集和存储这么多不同事物的数据。”。“在这个大数据的世界里,数据素养——分析、解释甚至质疑数据的能力——是一项越来越有价值的技能。”
利用描述性分析来传达基于当前和历史数据的变化,并作为诊断、预测和规定分析的基础,有可能让您和您的组织走得更远。
- 37 次浏览
【数据分析】什么是数据挖掘?它的工作原理、优点、技术和示例
QQ群
视频号
微信
微信公众号
知识星球
什么是数据挖掘?
数据挖掘是搜索和分析大量原始数据以识别模式并提取有用信息的过程。
公司使用数据挖掘软件来了解更多关于客户的信息。它可以帮助他们制定更有效的营销策略,增加销售额,降低成本。数据挖掘依赖于有效的数据收集、仓储和计算机处理。
关键要点
- 数据挖掘是分析大量信息以辨别趋势和模式的过程。
- 从了解客户对什么感兴趣或想买什么到欺诈检测和垃圾邮件过滤,公司都可以使用数据挖掘。
- 数据挖掘程序根据用户请求或提供的信息来分解数据中的模式和连接。
- 社交媒体公司使用数据挖掘技术将用户商品化,以产生利润。
- 这种数据挖掘的使用最近受到了批评,因为用户往往不知道他们的个人信息中发生的数据挖掘,尤其是当它被用来影响偏好时。
数据挖掘的工作原理
数据挖掘包括探索和分析大块信息,以收集有意义的模式和趋势。它用于信用风险管理、欺诈检测和垃圾邮件过滤。它也是一种市场研究工具,有助于揭示特定人群的情绪或意见。数据挖掘过程分为四个步骤:
- 数据在现场或云服务上收集并加载到数据仓库中。
- 业务分析师、管理团队和信息技术专业人员可以访问数据,并决定如何组织数据。
- 自定义应用程序软件对数据进行排序和组织。
- 最终用户以易于共享的格式显示数据,例如图形或表格。
数据仓库和挖掘软件
数据挖掘程序根据用户请求分析数据中的关系和模式。它将信息组织到类中。
例如,一家餐厅可能想使用数据挖掘来确定它应该提供哪些特色菜以及在什么日子提供。数据可以根据客户访问的时间和他们订购的内容组织成类。
在其他情况下,数据挖掘者根据逻辑关系找到信息集群,或者查看关联和顺序模式,以得出有关消费者行为趋势的结论。
仓储是数据挖掘的一个重要方面。仓储是将组织的数据集中到一个数据库或程序中。它允许组织剥离数据片段,供特定用户根据其需求进行分析和使用。
云数据仓库解决方案利用云提供商的空间和能力来存储数据。这使较小的公司能够利用数字解决方案进行存储、安全和分析。
数据挖掘技术
数据挖掘使用算法和各种其他技术将大量数据集合转换为有用的输出。最流行的数据挖掘技术类型包括:
- 关联规则,也称为市场篮子分析,搜索变量之间的关系。这种关系本身在数据集中创建附加值,因为它努力链接数据片段。例如,关联规则将搜索一家公司的销售历史,以查看哪些产品最常一起购买;有了这些信息,商店可以进行计划、促销和预测。
- 分类:使用预定义的类来指定给对象。这些类描述项目的特征,或者表示数据点与每个数据点的共同点。这种数据挖掘技术允许对基础数据进行更巧妙的分类,并在类似的功能或产品线中进行总结。
- 聚类:类似于分类。然而,集群识别对象之间的相似性,然后根据它们与其他项目的不同对这些项目进行分组。虽然分类可能会产生“洗发水”、“护发素”、“肥皂”和“牙膏”等组,但聚类可能会识别出“头发护理”和“牙齿健康”等组
- 决策树:用于根据一组标准或决策列表对结果进行分类或预测。决策树用于要求输入一系列级联问题,这些问题根据给出的回答对数据集进行排序。决策树有时被描述为类似树的可视化,当深入数据时,决策树允许特定的方向和用户输入。
- K-最近邻(KNN)是一种根据数据与其他数据的接近程度对数据进行分类的算法。KNN的基础植根于这样一种假设,即彼此接近的数据点比其他数据位更相似。这种非参数监督技术用于基于单个数据点预测组的特征。
- 神经网络:通过使用节点来处理数据。这些节点由输入、权重和输出组成。数据是通过监督学习绘制的,类似于人脑互联的方式。该模型可以被编程以给出阈值来确定模型的准确性。
- 预测分析:努力利用历史信息建立图形或数学模型来预测未来的结果。该技术与回归分析相重叠,旨在根据现有数据支持未来的未知数字。
数据挖掘过程
为了最有效,数据分析师通常在数据挖掘过程中遵循一定的任务流。如果没有这种结构,分析师可能会在分析过程中遇到一个问题,如果他们更早做好准备,这个问题本可以很容易地避免。数据挖掘过程通常分为以下几个步骤。
第一步:了解业务
在接触、提取、清理或分析任何数据之前,了解底层实体和手头的项目是很重要的。该公司试图通过挖掘数据来实现哪些目标?他们目前的业务状况如何?SWOT分析的结果是什么?在查看任何数据之前,挖掘过程首先要了解在过程结束时成功的定义。
第2步:了解数据
一旦明确定义了业务问题,就应该开始考虑数据了。这包括可用的来源,如何保护和存储这些来源,如何收集信息,以及最终结果或分析可能是什么样子。此步骤还包括确定数据、存储、安全性和收集的限制,并评估这些限制将如何影响数据挖掘过程。
步骤3:准备数据
收集、上传、提取或计算数据。然后对其进行清理、标准化、清除异常值、评估错误并检查合理性。在数据挖掘的这个阶段,还可以检查数据的大小,因为过大的信息集合可能会不必要地减慢计算和分析。
步骤4:建立模型
有了我们干净的数据集,是时候处理数字了。数据科学家使用上述类型的数据挖掘来搜索关系、趋势、关联或顺序模式。数据还可以被馈送到预测模型中,以评估先前的信息比特如何转化为未来的结果。
第5步:评估结果
数据挖掘以数据为中心的方面通过评估一个或多个数据模型的发现来结束。分析的结果可能会被汇总、解释并呈现给决策者,而到目前为止,决策者在很大程度上被排除在数据挖掘过程之外。在这一步骤中,组织可以选择根据调查结果做出决策。
步骤6:实施变更和监控
数据挖掘过程以管理层根据分析结果采取措施结束。公司可能会认为信息不够有力,或者调查结果不相关,或者公司可能会根据调查结果进行战略调整。在任何一种情况下,管理层都会审查业务的最终影响,并通过识别新的业务问题或机会来重新创建未来的数据挖掘循环。
不同的数据挖掘处理模型将有不同的步骤,尽管一般过程通常非常相似。例如,知识发现数据库模型有九个步骤,CRISP-DM模型有六个步骤,SEMMA过程模型有五个步骤。1
数据挖掘的应用
在当今的信息时代,几乎任何部门、行业、部门或公司都可以利用数据挖掘。
销售额
数据挖掘鼓励更智能、更高效地利用资本来推动收入增长。考虑一下你最喜欢的当地咖啡店的销售点登记。每次销售,咖啡馆都会收集购买的时间和销售的产品。利用这些信息,商店可以战略性地设计其产品线。
市场营销
一旦上面的咖啡馆知道了它的理想阵容,是时候实施这些改变了。然而,为了使营销工作更加有效,该店可以使用数据挖掘来了解客户在哪里看到广告,目标人群是什么,在哪里投放数字广告,以及哪些营销策略最能引起客户的共鸣。这包括根据数据挖掘结果调整营销活动、促销优惠、交叉销售优惠和计划。
制造业
对于生产自己商品的公司来说,数据挖掘在分析每种原材料的成本、最有效地使用哪些材料、在制造过程中花费的时间以及对过程产生负面影响的瓶颈方面发挥着不可或缺的作用。数据挖掘有助于确保货物的流动不受干扰。
欺诈检测
数据挖掘的核心是找到将数据点连接在一起的模式、趋势和相关性。因此,公司可以使用数据挖掘来识别不应该存在的异常值或相关性。例如,一家公司可能会分析其现金流,并发现一个未知账户的重复交易。如果这是出乎意料的,该公司可能希望调查资金是否管理不善。
人力资源
人力资源部门通常有广泛的数据可供处理,包括关于留用、晋升、工资范围、公司福利、这些福利的使用以及员工满意度调查的数据。数据挖掘可以将这些数据关联起来,以更好地了解员工离职的原因以及吸引新员工的因素。
客户服务
客户满意度的产生(或破坏)可能有多种原因。想象一下,一家运输货物的公司。客户可能对运输时间、运输质量或通信不满意。同一位客户可能会因电话等待时间过长或电子邮件回复缓慢而感到沮丧。数据挖掘收集有关客户互动的运营信息,并总结调查结果,以找出薄弱环节,突出公司的正确做法。
数据挖掘的好处
数据挖掘可以确保公司收集和分析可靠的数据。它通常是一个更严格、结构化的过程,正式识别问题,收集与问题相关的数据,并努力制定解决方案。因此,数据挖掘有助于企业变得更有利可图、更高效或运营更强大。
数据挖掘在不同的应用程序中看起来可能非常不同,但整个过程几乎可以用于任何新的或遗留的应用程序。从本质上讲,任何类型的数据都可以收集和分析,几乎每一个依赖于合格证据的业务问题都可以使用数据挖掘来解决。
数据挖掘的最终目标是获取原始信息,并确定数据之间是否存在内聚性或相关性。数据挖掘的这一好处使公司能够利用手头的信息创造价值,否则这些信息不会过于明显。尽管数据模型可能很复杂,但它们也可以产生令人着迷的结果,挖掘隐藏的趋势,并提出独特的策略。
数据挖掘的局限性
数据挖掘的复杂性是其最大的缺点之一。数据分析通常需要技术技能和某些软件工具。规模较小的公司可能会发现这是一个难以克服的进入壁垒。
数据挖掘并不总是能保证结果。一家公司可能会进行统计分析,根据强有力的数据得出结论,实施变革,但不会获得任何好处。通过不准确的发现、市场变化、模型错误或不适当的数据群体,数据挖掘只能指导决策,而不能确保结果。
数据挖掘还有一个成本组成部分。数据工具可能需要昂贵的订阅,并且某些数据位的获取成本可能很高。安全和隐私问题可以得到缓解,尽管额外的IT基础设施也可能成本高昂。当使用庞大的数据集时,数据挖掘可能也是最有效的;然而,这些数据集必须被存储,并且需要大量的计算能力来进行分析。
即使是大公司或政府机构也面临数据挖掘方面的挑战。以美国食品药品监督管理局关于数据挖掘的白皮书为例,该白皮书概述了不良信息、重复数据、少报或多报的挑战。2
数据挖掘与社交媒体
数据挖掘最有利可图的应用之一是由社交媒体公司进行的。Facebook、TikTok、Instagram和Twitter等平台根据用户的在线活动收集了大量用户数据。
这些数据可以用来推断他们的偏好。广告商可以将他们的信息瞄准那些看起来最有可能做出积极回应的人。
社交媒体上的数据挖掘已成为争论的焦点,几份调查报告和曝光显示,挖掘用户的数据可能具有多大的侵入性。问题的核心是,用户可能会同意网站的条款和条件,但没有意识到他们的个人信息是如何被收集的,也没有意识到信息被卖给了谁。
数据挖掘示例
数据挖掘可以被用来做好事,也可以被非法使用。以下是两者的一个例子。
易趣和电子商务
易趣每天都从卖家和买家那里收集无数的信息。该公司使用数据挖掘来确定产品之间的关系,评估所需的价格范围,分析先前的购买模式,并形成产品类别。3
易趣将推荐流程概括为:
- 原始项目元数据和用户历史数据被聚合。
- Scripps在经过训练的模型上运行,以生成和预测项目和用户。
- 执行KNN搜索。
- 结果被写入数据库。
- 实时推荐获取用户ID,调用数据库结果,并将其显示给用户。3
Facebook剑桥分析丑闻
数据挖掘的另一个警示性例子是Facebook剑桥分析公司的数据丑闻。2010年代,英国咨询公司剑桥分析有限公司收集了数百万Facebook用户的个人数据。这些信息后来被分析用于2016年特德·克鲁兹和唐纳德·特朗普的总统竞选。有人怀疑剑桥分析公司干扰了英国脱欧公投等其他著名事件。4
鉴于这种不恰当的数据挖掘和用户数据的滥用,脸书同意支付1亿美元,因为它在使用消费者数据方面误导了投资者。美国证券交易委员会(Securities and Exchange Commission)声称,脸书在2015年发现了这种滥用行为,但在两年多的时间里没有纠正其披露的信息。5
常见问题
数据挖掘的类型是什么?
数据挖掘主要有两种类型:预测数据挖掘和描述性数据挖掘。预测数据挖掘提取可能有助于确定结果的数据。描述数据挖掘通知用户给定的结果。
数据挖掘是如何完成的?
数据挖掘依赖于大数据和先进的计算过程,包括机器学习和其他形式的人工智能。目标是从大型和非结构化数据集中找到能够导致推断或预测的模式。
数据挖掘的另一个术语是什么?
数据挖掘也使用较少使用的术语“数据中的知识发现”或KDD。
数据挖掘在哪里使用?
数据挖掘应用程序的设计几乎可以承担任何依赖大数据的工作。金融行业的公司在市场中寻找模式。各国政府试图识别潜在的安全威胁。公司,尤其是在线和社交媒体公司,利用数据挖掘来创建针对特定用户群体的盈利广告和营销活动。
底线
现代企业有能力收集有关客户、产品、生产线、员工和店面的信息。这些随机的信息片段可能无法讲述故事,但数据挖掘技术、应用程序和工具的使用有助于将信息拼凑在一起。
数据挖掘过程的最终目标是汇编数据,分析结果,并根据数据挖掘结果执行操作策略。
- 56 次浏览
【数据分析】实时分析带来了解锁优势的挑战
QQ群
视频号
微信
微信公众号
知识星球
实时分析使组织能够更快地做出决策。然而,糟糕的数据,或者没有准备好进行实时分析的文化,可能会破坏这些好处。
实时分析工具有望提供更快的洞察力和改进的业务流程,但它们也给采用它们的组织带来了挑战。
随着2023年实时分析的使用增加,实施错误会耗费时间和金钱,导致糟糕的商业决策,并导致员工对技术的潜力失去信心。
人工智能、数据和分析网络2022年11月发布的一项全球调查显示,高级分析的首要投资领域是复杂的事件处理,52%的公司已经在投资。复杂事件处理是一组可以实时分析运动中的大量数据流的技术。另有37%的受访者表示他们正在使用流媒体分析。
增加对分析技术的投资并不能保证成功。如果每个人都不认同实时分析的含义,组织就有失去时间、金钱和士气的风险。糟糕的实施也可能导致糟糕的数据导致糟糕的决策。即使是好的数据分析实现也具有挑战性,因为实时信息可以而且应该改变业务规范。
预期不一致造成的时间和金钱损失
如果管理层和员工对实时意味着什么有不同的想法,就会发生代价高昂的错误。
实时分析软件公司Rockset的首席执行官Venkat Venkataramani表示,当有可能失去销售额或失去大客户时,必须充分理解实时分析的定义。
Venkataramani提供了一个实时分析推出出错的例子。一家先买后付的提供商遇到了问题,因为管理层认为实时意味着最新的一分钟,而实施分析项目的团队认为延迟六个小时就足够实时了。
Venkataramani说,数据团队从一个数据仓库开始。“随着规模的扩大,在这六个小时的窗口期内可能发生的潜在损失越来越大。他们已经损失了很多付款和很多利润增长。”
项目中的利益相关者没有就需求达成一致,因此没有选择正确的平台来实现。
Venkataramani说:“使用非实时构建的错误工具,要么会给你带来延迟很大的数据,比如落后六小时的旧数据,要么只会给你一个非常昂贵的解决方案,你无法获得投资回报。”。
这不是一个罕见的错误。事实上,人工智能、数据与分析网络的调查显示,44%的组织仍然缺乏企业范围的数据战略。
糟糕的商业决策源于糟糕的数据
垃圾进,垃圾出一直是计算机领域的真理。
当流程进展缓慢时,有时间发现错误并在成本过高之前进行修复。通过实时分析,纠正问题的机会窗口几乎缩小到零。
公司必须从一开始就确保数据是干净的,这并不容易。数据管道管理工具提供商远大前程2022年5月的一项调查显示,在500名IT和数据专业人士中,91%的人表示这会影响公司的业绩。
Gartner估计,一家普通公司每年的不良数据成本为1290万美元。在实时环境中,潜在的损失会加剧。
专业服务公司简柏特的首席数字官Sanjay Srivastava说:“如果你不能正确处理噪音,而且行动太快,你最终可能会做出糟糕的决定。”。
实时修复数据问题也不容易。事实上,有时数据的来源是不正确的。例如,简柏特跟踪重型机械发动机的许多物联网参数,并使用这些数据来预测维护需求。这些数据令人不安。来自物理传感器的数据可能不均匀或不稳定。只是背景噪声的随机波动随着时间的推移而平均化,以提供有意义的信息。
但在现实中,没有机会。
斯里瓦斯塔瓦说:“如果你一点一点地看,它可能会给你不一致的结果,告诉你什么时候需要修复。”。他补充道,组织必须考虑数据是什么,结论是什么,以及它对你使用它的环境是否有意义。
Gartner杰出副总裁分析师Roy Schulte表示,传统的数据质量程序和工具并不总是有效的。“你没有时间,”他说。
有一些新的工具可以帮助公司处理实时数据问题,包括其他软件解决方案和开源选项,如Apache Flink,可以在短时间内多次计算答案。例如,有人可能想知道一台特定的机器目前的性能如何。
舒尔特说:“使用Flink,你可以计算两次答案。”。“你现在就可以计算出答案,五分钟后你可以回来重新计算同一时间段。”他说,通过考虑延迟到达的数据,最终结果更准确。
失去信心、士气低落和部门间冲突
转向实时分析可能会颠覆企业的运营方式,给员工和业务部门带来压力。
根据NewVantage Partners于2023年1月发布的一项调查,94%的组织计划在2023年增加数据投资。约80%的人表示,组织的可接受性和一致性、流程的变化以及人员和技能是他们从数据中获得价值的最大障碍。
推出实时分析时要克服的第一个挑战并不总是关于数据或工具。数据集成软件提供商CData Software的高级技术宣传员Jerod Johnson表示,这关乎组织的心态。
他说:“每个人都熟悉从数周、数月甚至数年的数据中分析和寻找意义的做法。”。“如果你的组织正在实时分析数据,那么如果你所做的工作被证明是无效的,你需要有适当的流程来快速改变方向。”
这包括采用新技术并教育员工如何使用这些技术。在推出实时分析时,公司需要遵循变革管理的最佳实践,包括定期沟通,建立一个强有力的变革案例,让员工参与其中,为员工提供培训和支持,以及如何管理阻力的计划,并庆祝成功。但实时分析也需要注意行动过快的风险,包括任何潜在错误的影响。
约翰逊说:“你需要有一种接受偶尔错误分析的氛围。”。“当学会快速做出决策时,组织需要适应早期失败和快速恢复的概念。”
- 2 次浏览
【数据分析】我们如何削减约95%的分析报告成本以及我们学到了什么
QQ群
视频号
微信
微信公众号
知识星球
GovTech Edu的重点之一是为教育、文化、研究和技术部(MoECRT)开发数字产品(称为:应用程序),例如为教师提供的Merdeka Mengahal平台(PMM)和为大学利益相关者(学生、讲师、行业合作伙伴和从业者)提供的Kampus Merdeka平台。这些应用程序生成了大量数据,我们可以进一步利用这些数据进行分析和建模,以帮助MoECRT采取行动,改进数字产品和程序本身。鉴于生成数据的重要作用,我们可能会将应用程序生成的数据视为其本身的产品。为了优化下游的数据利用率,我们构建了简化的数据管道,就像您的普通管道一样。
Figure 1. Data Pipeline in General
我们使用Google BigQuery来存储数据,dbt用于我们的数据处理平台,Google Looker Studio作为我们的数据可视化平台。
为了支持我们提供仪表盘和每日报告的渠道——让我们从现在开始使用“报告”一词——我们监控数据质量和处理数据的基础设施成本。我们还为查询处理设置了每日配额限制。我们将这种成本监控和限制视为高度优先事项,因为我们必须尽可能深思熟虑,在不影响总成本的情况下为我们的数据获得最佳价值。
我们如何诊断和分析我们的成本?
随着用户对我们平台的采用呈指数级增长,我们的数据处理成本在前3个月持续增长了4倍以上(图2)。这导致每日配额限制受到更频繁的打击。一些ETL(或ELT)已停止运行,并且报告中未显示数字(或业务指标)。由于产品经理、部门负责人甚至部委的利益相关者等内部和外部利益相关者都需要这些报告,我们的数据分析师和科学家通过手动重新运行来帮助我们。然而,这种手动工作是不可扩展的,也没有给我们的人才带来任何最佳价值。
Figure 2. BigQuery Cost Growth in 3 Months
为了应对这些挑战,我们根据BigQuery审核日志-数据访问中的目标表评估了成本最高的BigQuery作业。我们通过以下3个步骤创建了一个成本监控面板:
- 通过观察模式对工作进行分类;执行者的电子邮件、作业名称、来源、目的地表等。其中一些类别包括dbt作业(ELT)、BigQuery控制台、Python和谷歌电子表格
- 创建dbt作业以每天计算BigQuery作业的成本,并将其存储在表中
- 使用此表作为源,我们制作了一个仪表板,其中包括要分析的多个可视化
我们发现dbt作业是成本最高的类别之一。
然后,从这些dbt作业中,我们根据以下标准连续选择需要处理的作业:
- 在这段时间内成本最高的人
- 使用简单的折线图查看成本趋势倾斜趋势中的工作排名会更高,下降趋势中的职位排名会更低
- 每个作业平均运行成本最高的作业,因为一旦这些作业需要更频繁地运行,成本就会显著上升
-
那些拥有最多工作的人
成本效率低下及其解决方案
在分析了有问题的dbt作业、更新其查询和验证结果(数字保持不变+成本降低)后,我们了解到在BigQuery中处理数据时可能会发现这些效率低下的问题。
处理可以每天更新的所有时间数据
想象一下,你在一个电子商务应用程序工作,你的工作是提供交易和收入的每日摘要。您可以通过查询原始订单表并将结果存储在汇总表中来实现这一点。相当简单。然后创建每天运行的查询。
SELECT order_date, SUM(1) AS transactions, SUM(total_amount) AS revenue FROM `raw.order` GROUP BY order_date ORDER BY order_date
通常,ELT是在D-1数据上运行的,这意味着你要等到第二天才能完全收集第一天的数据,然后再进行处理。因此,在第二天运行时,这就是你的结果。
╔════════════╦══════════════╦═══════════╗ ║ order_date ║ transactions ║ revenue ║ ╠════════════╬══════════════╬═══════════╣ ║ 2022-01-01 ║ 1,124 ║ 3,567,300 ║ ╚════════════╩══════════════╩═══════════╝
假设1行表示1个事务。这意味着您将在2022年1月1日处理1124行数据。
继续到第二天。
╔════════════╦══════════════╦═══════════╗ ║ order_date ║ transactions ║ revenue ║ ╠════════════╬══════════════╬═══════════╣ ║ 2022-01-01 ║ 1,124 ║ 3,567,300 ║ ║ 2022-01-02 ║ 1,549 ║ 4,938,100 ║ ╚════════════╩══════════════╩═══════════╝
2022年1月3日,您总共处理了2673行。这就是它变得有趣的地方。如果你再看一次,你已经运行了两次1月1日的数据。然而,“交易”和“收入”的结果分别为1124和3567300。这意味着您正在重新计算1124行数据,以获得相同的结果。听起来有点浪费,是吗?
想象一下,这个过程一直持续到2022年1月6日。
╔════════════╦══════════════╦═══════════╗ ║ order_date ║ transactions ║ revenue ║ ╠════════════╬══════════════╬═══════════╣ ║ 2022-01-01 ║ 1,124 ║ 3,567,300 ║ ║ 2022-01-02 ║ 1,549 ║ 4,938,100 ║ ║ 2022-01-03 ║ 1,374 ║ 4,538,900 ║ ║ 2022-01-04 ║ 862 ║ 2,551,600 ║ ║ 2022-01-05 ║ 938 ║ 3,498,500 ║ ╚════════════╩══════════════╩═══════════╝
现在,您正在处理5847行,并且已经重新计算
- 1月1日数据的4倍,
- 1月2日数据的3倍,
- 1月3日数据的2倍,以及
- 1次1月4日的数据。
随着时间的推移,这个数字将不断增加。这就是处理后的数据的样子,与此相一致的是成本。
那么我们该如何解决这个问题呢?解决方案是只对新数据(以前没有计算过的数据)运行查询,并将结果附加到结果表中,而不是完全重写。换句话说:
- 在日期2,只运行1月1日的数据,然后将结果追加到汇总表中
- 在第3天,只运行1月2日的数据,然后像第1点一样追加结果
- 等等
处理后的数据将如下所示。它要小得多——这会导致更快的流程——而且效率更高,不是吗?
我们可以通过对日常数据而不是所有时间进行计算来降低成本。我们的日常数据越大,这种方法就越能为我们省钱。
在BigQuery中,这个称为分区的概念根据表的字段将表拆分为“迷你表”。在查询中,我们可以检索这些分区,而不是一个完整的表,然后将结果存储为目标表中的新分区(或覆盖)。因此,为了充分利用分区,源和目的地都需要启用这个概念。
- 主要针对源表,因为它决定了BigQuery中查询的成本,以及
- 因为它可能会成为其他查询的源表。
我们修改查询以检索源的分区,并将其存储为分区。以下是我们用来配置目标分区的dbt脚本片段。
{{ config(
materialized = 'incremental',
partition_by = {
"field": "event_date_gmt7",
"data_type": "date",
"granularity": "day"
}
)}}
通常,此片段告诉dbt按`event_date_gmt7`字段对目标表进行分区。
同时,这是我们源代码的片段。
FROM
{{ ref('<fact_table_name>') }}
WHERE
event_date_gmt7 > '<latest_date_partition_of_destination_table>'
AND event_date_gmt7 <= DATE_SUB(CURRENT_DATE('+07:00'), INTERVAL 1 DAY)
通过在WHERE子句中使用“event_date_gmt7”,也就是这个源表的分区字段,我们已经告诉dbt只检索源表的一部分,而不是整个表。非常简单明了!
BigQuery还有另一个拆分表的概念,称为集群。简而言之,集群就像一个分区,但它不是基于一个字段,而是基于字段的组合。因此,在查询时,BigQuery将在扫描表源之前筛选分区字段和集群字段。下面是一个在表中启用集群的示例片段。
{{ config(
materialized = 'incremental',
partition_by = {
"field": "event_date_gmt7",
"data_type": "date",
"granularity": "day"
},
cluster_by = [
'user_interface',
'<column_b>',
'<column_c>',
'…'
]
)}}
这是使用它的片段。
FROM
{{ ref('<fact_table_name>') }}
WHERE
event_date_gmt7 > '<latest_date_partition_of_destination_table>'
AND event_date_gmt7 <= DATE_SUB(CURRENT_DATE('+07:00'), INTERVAL 1 DAY)
AND user_interface = 'Android'
是的,这和使用分区是一样的。您只需要在WHERE子句中声明筛选器。再说一遍,非常简单明了!
实际上,您可以在不使用分区的情况下使用集群。但如果你将两者结合起来,你可以进一步优化你的成本。您可以在谷歌提供的这个简短的实验室中学习分区和集群。
扫描整张表以获取最新分区
查看源分区的前一个代码片段,我们检索最新目的地的日期分区。其目的是只运行源表中未处理的数据。那么我们该怎么做呢?
在大多数情况下,我们将使用此查询。
SELECT MAX(<partition_field>) FROM `<source_table>`
然而,如果源表包含数百万行,我们将遍历所有这些行,并产生更多的成本。想象一下,一个表有100个分区,每个分区包含1000000行。通过使用实际的表,我们查询了100 x 1000000=100000000行。有没有更好的方法来获取最新的分区?
是的,当然,通过使用元数据表。在BigQuery中,元数据存储在INFORMATION_SCHEMA视图中,其中包含有关BigQuery对象的所有信息,包括存储在partitions视图中的表中的分区列表。此视图中的一行包含有关一个分区的信息,例如其表数据集/架构、表名称、分区ID、总行数和上次更新时间。以下是用于查询元数据的SQL代码段。
SELECT
MAX(SAFE.PARSE_DATE('%Y%m%d', partition_id))
FROM
`<project_name>.<dataset_name>.INFORMATION_SCHEMA.PARTITIONS`
WHERE
table_name = '<table_name>'
因此,通过使用前面的示例,我们只使用元数据查询100行,而不是100000000行。更快、更便宜。
在dbt中,我们将这个查询放在宏中,这样我们就可以在ELT中重用它。宏代码将如下所示
{% macro get_latest_part_date(column_name, relation) %}
{% set relation_query %}
## Get latest date from metadata
## If 'column_name' is null, return D-1
SELECT
MAX(SAFE.PARSE_DATE('%Y%m%d', partition_id))
FROM
{{ relation.database }}.{{ relation.schema }}.INFORMATION_SCHEMA.PARTITIONS
WHERE
table_name = '{{ relation.identifier }}'
{% endset %}
{% set results = run_query(relation_query) %}
{% if execute %}
{% if results.columns[0][0] != None %}
## Latest partition not null (found)
{% set results_list = results.columns[0][0] %}
{% else %}
## Default value
{% set results_list = '2021–01–01' %}
{% endif %}
{{ return(results_list) }}
{% endmacro %}
查询将如下所示。
FROM
{{ ref('<fact_table_name>') }}
WHERE
event_date_gmt7 > '{{ get_latest_part_date('event_date_gmt7', this) }}'
AND event_date_gmt7 <= DATE_SUB(CURRENT_DATE('+07:00'), INTERVAL 1 DAY)
多次查询最新分区
另一点与之前关于不使用元数据表的学习有关,这一点与之并行。我们在ELT中经常使用多个源表来生成一个新的结果表。这最初使我们为每个源调用宏。
然而,几天后,我们意识到我们的成本又上升到了最初的水平。我们发现,每次调用宏时,它都会向BigQuery发送一个查询作业来检索结果。因此,如果我们得到10个使用该宏的源表,那么BigQuery将有10个查询作业返回相同的结果。考虑到当时我们仍然使用实际的表,想象一下有10个查询扫描包含数千万行的整个表。
我们只调用这个宏一次,将其作为CTE(WITH子句中的表),然后在每个源表的FROM子句中连接该表,从而解决了这个问题。
WITH
vars AS (
-- Get latest partition of this table
SELECT
DATE("{{ get_latest_part_date('event_date_gmt7', this) }}") AS latest_partition
)
, t1 AS (
SELECT
f.*
FROM
{{ ref('<fact_table_name_1>') }} f,
vars
WHERE
event_date_gmt7 > latest_partition
AND event_date_gmt7 <= '<yesterday_date>'
)
, t2 AS (
SELECT
g.*
FROM
{{ ref('<fact_table_name_1>') }} g,
vars
WHERE
event_date_gmt7 > latest_partition
AND event_date_gmt7 <= '<yesterday_date>'
)
...
后果
结合这些经验来更新我们一些成本最高的dbt工作,我们将成本降低了约95.91%。我们还调整了Looker Studio数据源,将成本降低约98.97%。
结论
- 利用分区和集群的优势。或者数据库中提供的任何分块机制。
- 要获取最新的分区,请使用元数据而不是实际的表。只是你的表没有分区。
- 您可能使用宏不仅是为了运行查询以获取最新的分区,而且由于它会为每个调用的宏触发一个作业,请注意并将其设为“参数”。
- 请毫不犹豫地查看文档(例如,像dbt这样的ETL/ELT平台)。一开始这可能看起来很吓人,但我相信我们会了解到关于平台的一两件事(无论是什么),这可能对我们的问题有用,或者甚至在问题出现之前优化我们当前的脚本。你也可以从YouTube上学习教程或会议。
- 循序渐进地改进是可以的。这些知识,我也是一周又一周地发现的,不是一次全部发现的。追求进步而不是完美
- 最后但同样重要的是,如果您正在迁移/更改表,而不是创建一个新表,请确保您的表具有与以前的模型相同的结果,以便进行无缝更改。我们不想仅仅为了成本效益而损害我们报告的准确性。
- 5 次浏览
【数据分析】描述性、预测性和规范性:三种类型的业务分析
QQ群
视频号
微信
微信公众号
知识星球
如今,你很难找到一家不以某种形式或形式使用分析来为商业决策提供信息和衡量业绩的企业。
预计到2022年,全球在大数据分析解决方案上的支出将超过2743亿美元,这不仅仅是大公司的投资。研究表明,近70%的小企业每年在分析上花费超过1万美元,以帮助他们更好地了解客户、市场和业务流程。
绝大多数高管表示,他们的组织已经通过大数据和人工智能取得了成功。数据也会对你的底线产生重大影响,利用大数据的企业平均利润会增加8-10%。据报道,Netflix每年通过使用数据分析来改进其客户保留策略,节省了10亿美元。
那么,企业使用哪些数据分析方法来产生这些令人印象深刻的结果呢?
描述性、预测性和规范性分析
商业分析是企业使用统计方法和技术分析数据以获得见解和改进战略决策的过程。
企业可以使用三种类型的分析来推动决策;描述性分析,告诉我们已经发生了什么;预测分析,它向我们展示了可能发生的事情,最后是规定分析,它告诉我们未来应该发生什么。
虽然这些方法中的每一种在单独使用时都很有用,但当它们一起使用时会变得特别强大。
描述性分析
描述性分析是使用两种关键方法——数据聚合和数据挖掘——对历史数据进行分析,这两种方法用于揭示趋势和模式。描述性分析不用于从其发现中推断或预测未来;相反,它关注的是代表过去发生的事情。
描述性分析通常使用线图、条形图和饼图等可视化数据表示来显示,尽管它们本身提供了有用的见解,但通常是未来分析的基础。由于描述性分析使用了相当简单的分析技术,因此任何发现都应该易于更广泛的业务受众理解。
因此,描述性分析构成了许多企业日常报告的核心。年度收入报告是描述性分析的经典例子,还有库存、仓储和销售数据等其他报告,这些报告可以轻松汇总,并提供公司运营的清晰快照。另一个广泛使用的例子是社交媒体和谷歌分析工具,它们根据点击和点赞等事件的简单计数来总结某些分组。
虽然描述性数据有助于快速发现趋势和模式,但分析有其局限性。孤立地看,描述性分析可能无法给出全貌。为了获得更多的见解,你需要更深入地研究。
预测分析
预测分析是一种更先进的数据分析方法,它使用概率来评估未来可能发生的事情。与描述性分析一样,预测分析使用数据挖掘,但它也使用统计建模和机器学习技术,根据历史数据确定未来结果的可能性。为了进行预测,机器学习算法利用现有数据,并试图用尽可能好的猜测来填补缺失的数据。
这些预测可以用来解决问题和确定增长机会。例如,组织正在使用预测分析来防止欺诈,方法是寻找犯罪行为模式,通过发现交叉销售机会来优化营销活动,并通过使用过去的行为来预测哪些客户最有可能拖欠付款来降低风险。
预测分析的另一个分支是深度学习,它模仿人类的决策过程,做出更复杂的预测。例如,通过使用多个级别的社会和环境分析,深度学习被用于更准确地预测信用评分,在医学领域,它被用于对MRI扫描和X射线等数字医学图像进行排序,为医生诊断患者提供自动预测。
规定性分析
虽然预测分析向公司展示了其潜在行动的原始结果,但规定分析向公司显示了哪种选择是最好的。
规定分析领域大量借鉴了数学和计算机科学,使用了各种统计方法。
尽管与描述性和预测性分析密切相关,但规定性分析强调可操作的见解,而不是数据监控。这是通过从一系列描述性和预测性来源收集数据并将其应用于决策过程来实现的。然后,算法创建并重新创建可能的决策模式,这些模式可能以不同的方式影响组织。
规范性分析之所以特别有价值,是因为它们能够根据不同的未来情景来衡量决策的影响,然后建议实现公司目标的最佳行动方案。
使用规范分析的商业效益是巨大的。它使团队能够在做出决策之前查看最佳行动方案,从而在实现最佳结果的同时节省时间和金钱。
能够利用规范性分析的力量的企业正在以各种方式使用它们。例如,规定性分析允许医疗保健决策者通过为患者和提供者推荐最佳行动方案来优化业务结果。它们还使金融公司知道如何降低产品成本,以吸引新客户,同时保持高利润。
以数据为导向的未来
尽管在决策中使用数据分析有明显的好处,但许多组织仍然缺乏优化数据分析所需的技能。
数据分析是一门复杂的学科。目前,不到四分之一的企业将自己描述为数据驱动型企业,《福布斯》报告称,几乎所有企业都认为管理非结构化数据的需求是其组织的一个问题。
能够操纵和解释数据的商业专业人员的技能差距越来越大。
ThoughtSpot首席执行官苏迪什·奈尔(Sudhesh Nair)表示:“2021及以后的企业最理想的人选将是一个既能理解数据又能说数据的人,因为在短短几年内,数据素养将成为雇主的需求和期望。那些想取得成功的人现在正在获得这些人才。”。
- 149 次浏览
【数据分析】描述性分析:它们是什么以及相关术语
QQ群
视频号
微信
微信公众号
知识星球
什么是描述性分析?
描述性分析是指对历史数据的解释,以更好地了解企业中发生的变化。描述性分析描述了使用一系列历史数据与同一公司的其他报告期(即季度或年度)或同一行业内的其他公司进行比较。最常见的财务指标是描述性分析的产物,如同比(YOY)定价变化、环比销售额增长、用户数量或每个订户的总收入。这些衡量标准都描述了企业在一段时间内发生的事情。
关键要点
- 描述性分析是分析历史数据以更好地了解企业中发生的变化的过程。
- 通过使用一系列历史数据和基准测试,决策者可以获得绩效和趋势的整体视图,从而制定商业战略。
- 描述性分析可以帮助识别组织中的优势和劣势领域。
- 描述性分析中使用的指标示例包括同比定价变化、环比销售额增长、用户数量或每个订户的总收入。
- 描述性分析与较新的分析结合使用,如预测性和规定性分析。
描述性分析的工作原理
描述性分析采用全方位的原始数据,并对其进行分析,得出管理者、投资者和其他利益相关者可能认为有用且可理解的结论。这些数据提供了过去业绩的准确情况,以及与其他可比时期的差异。它还可以用来与同行业的其他公司进行性能比较。这些绩效指标可用于标记优势和劣势领域,为管理策略提供信息。
例如,一份显示销售额为100万美元的报告听起来可能令人印象深刻,但缺乏背景。如果这个数字意味着环比下降20%,那就有理由担心。如果同比增长40%,那么这表明销售或营销策略出现了问题。然而,需要更大的背景,包括目标增长,以获得对公司销售业绩的知情看法。
描述性分析是公司使用的商业智能中最基本的部分之一。它通常可以是特定行业的(想想发货完成时间的季节性变化),但在整个金融行业都有广泛接受的通用衡量标准。
描述性分析是绩效分析的重要组成部分,因此管理者可以根据历史数据做出明智的战略商业决策。
描述性分析告诉你什么?
公司可以使用描述性分析来获得对其表现的宝贵见解。因为它通常是一种特定于行业的工具,一家公司可以通过查看其过去的业绩,如收入和销售额的增长,来将其业绩和市场地位与竞争对手进行比较。确定当前的财务趋势也很有用,包括公司内部个人的目标。
如何使用描述性分析?
描述性分析是一种非常重要的工具,可以用于任何业务的不同部分。这是因为它让公司了解它的表现有多好,以及哪里可能存在效率低下的问题。因此,公司管理层可以确定需要改进的领域,并利用它来激励不同的团队实施变革,以持续取得成功。
有两种主要方法用于收集数据进行描述性分析。这些是数据聚合和数据挖掘。在理解数据之前,必须先收集数据,然后将其解析为可管理的信息。然后,管理层可以有意义地使用这些信息来理解业务的现状。
例如,投资资本回报率(ROIC)是一种描述性分析形式,通过获取三个数据点——净收入、股息和总资本——并将这些数据点转化为易于理解的百分比,用于将一家公司的业绩与其他公司的业绩进行比较。
描述性分析提供了有关公司运营的“发生了什么?”信息,整体诊断分析提供了“为什么会发生?”信息;预测性分析提供了关于“未来可能发生什么?”
描述性分析步骤
公司可以采取一些步骤来成功地将描述性分析纳入其商业战略。下面的列表突出显示了这些步骤以及每个步骤的描述。
- 确定要分析的指标。在开始之前,重要的是要决定公司想要制定哪些指标以及每个指标的时间框架,例如季度收入或年度营业利润。
- 识别和定位数据。此步骤需要查找生成结果所需的所有数据。这意味着要查看所有内部和外部来源,包括数据库。
- 编译数据。一旦识别并定位了所有数据,下一步就是一起准备和编译。这里的部分过程是确保它是准确的,并将所有内容格式化为单一格式。
- 数据分析。分析数据集和数字意味着使用不同的工具
一旦完成了所有这些步骤,就必须将所有数据提交给适当的利益相关者。使用适当的视觉辅助工具,如图表、图形、视频和其他工具,可以为分析师、投资者、管理层和其他人提供他们对公司方向所需的见解。
一家公司越大、越复杂,通常用来衡量其业绩的描述性分析就越多。
描述性分析的优点和缺点
优点
在公司工作流程中使用描述性分析的主要好处之一是,它以简单的方式传播信息,并为所有主要利益相关者提供理解复杂想法的方法。这通常是通过图表等易于理解的视觉效果来完成的。将该公司以前的状况与现在的状况进行并排比较并不罕见。
主要利益相关者可以看到一家公司与同行业的竞争对手相比如何。这是因为变量往往是相同的,比如生产成本、收入流和产品供应。这让一家公司能够看到自己的商业计划和模式是否有任何需要改进的地方。
缺点
虽然描述性分析有助于了解过去发生的事情,但它并不一定能为未来的预期打开一扇窗户。因此,公司不能指望它来确定市场力量、供需变化、经济波动和其他变量在未来会如何影响它们。
利益相关者可能会发现字里行间的解读很有挑战性,尤其是当显性或隐性偏见发挥作用时。例如,利益相关者可能会选择有利的指标进行分析,而忽略其他指标。这样做可能会让其他人觉得一家公司是盈利的,没有什么领域需要改变。
优点
- 分解信息,使其易于理解
- 使公司能够了解与竞争对手相比的表现
缺点
- 无法用于确定未来性能
- 利益相关者可以选择(有利的)指标进行分析
描述性分析与预测性分析、处方性分析和诊断性分析
描述性分析以易于掌握的格式提供重要信息。因此,总是需要这种类型的分析。但可能会更加强调新的分析领域,包括预测、规范和诊断分析。
这些分析使用描述性分析,并整合来自不同来源的额外数据,以对近期可能的结果进行建模。这些前瞻性分析不仅仅是提供信息,还有助于决策。这些类型的分析还可以提出行动方案,最大限度地提高积极成果,最大限度减少消极成果。
预测分析
顾名思义,预测分析试图预测未来的表现。这是通过使用统计和建模来实现的。使用当前和过去的数据来确定类似的结果在未来是否可能再次发生。
采用预测分析的公司可以通过识别和解决效率低下的问题而受益。他们还可以利用它找到更好、更有效的方式来投入他们的资源(如用品、劳动力和设备)。
处方分析
规定性分析允许公司使用技术分析重要数据,以确定他们需要做什么来实现特定结果。它考虑了某些情况和可用资源,以及过去和当前的表现,为未来制定建议。
使用规范性分析的利益相关者可能更有能力在任何时间内做出重要决策,包括他们是否需要在研发方面投入更多资金,是否应该继续提供特定的产品,或者是否需要进入新市场。
诊断分析
诊断分析涉及使用数据来理解变量之间的关系以及为什么存在某些趋势。简单地说,这是确定事情发生原因的另一种方法。这种类型的分析可以手动进行,也可以在计算机软件的帮助下进行。
与其他类型的分析不同,诊断分析并不试图了解公司的历史业绩,也不试图预测公司未来的预期。相反,它通常被关键利益相关者用来找出事件的根本原因,并在未来做出改变。
公司如何从描述性分析中获益?
描述性分析是一种试图回答“发生了什么?”问题的分析形式,因此,它需要历史数据来了解已经发生的变化。这允许公司与其他报告期或类似公司进行比较。通过采用描述性分析,公司能够更好地识别运营中的低效率,并为未来做出改变。
描述性分析和预测性分析之间的关系是什么?
描述性分析试图回答“发生了什么?”问题,而预测性分析则试图回答“会发生什么?”的问题。这意味着描述性分析使用历史数据和过去的表现来找出可以改进的地方。预测分析可以帮助公司了解这些变化将如何影响未来的业绩。因此,这两种类型的分析可以一起使用以协同工作。
什么是描述性分析的例子?
公司可以使用描述性分析来分析特定报告期内的各种指标,以帮助他们取得成功。这些可以是金融的,也可以是非金融的。一些公司选择通过社交媒体来衡量与受众的互动程度,因为它可以告诉他们某个广告活动或产品发布的效果如何。这可以通过分析点击和点赞如何导致网站流量增加,从而增加销售额和推荐来衡量。
底线
描述性分析是公司开始分析其绩效指标的一种很好的方式。这是因为它是最简单的数据分析形式之一。这是一种直接的方法,可以为管理层、投资者和分析师提供与类似指标的直接比较,例如季度收入。利用过去的表现可以帮助关键利益相关者更好地了解发生了什么,从而为未来做出更好、更明智的决策。
- 132 次浏览
【数据分析】揭开数据分析的黑暗科学神秘面纱
QQ群
视频号
微信
微信公众号
知识星球
知识和规划将数据分析从“黑科学”转变为主流商业工具。
尽管很少有人会公开承认,但对于许多 IT 领导者来说,数据分析仍然是一门黑暗科学,充满了神秘的方法和看似高深莫测的实践。 然而,尽管它的名声有些神秘,但分析一再证明它是一门经过验证的科学,是一种强大的工具,通常可以显着提高生产力、效率、销售额、利润和其他关键业务指标和目标。
田纳西大学商业分析助理教授 Michel Ballings 观察到,今天的分析革命让许多高级 IT 领导措手不及。 “直到最近,计算才变得强大到足以执行高级数据分析,”他说。 “[大多数] 高级 IT 领导者在数据分析革命之前就毕业了。”
技术咨询公司 ThoughtWorks 的首席数据科学家 David Johnston 指出,高级分析本质上是一种研究技能,大多数 IT 领导者和高管从来都不是专业研究人员。 “这些技能在学术界最为普遍,因此,大多数成功的数据科学家和分析经理都曾是学者。” 因此,许多老派的 IT 领导者对新兴的分析计划感到困惑和恐惧。
拥抱未知
企业 IT 领导者需要认识到,分析将对其稳定且结构良好的部门提出挑战。 埃森哲数字技术咨询服务董事总经理贾斯汀霍纳曼说:“大型组织内部需要的技能组合正在发生转变,以推动数据和分析支持的解决方案。” “许多传统的 IT 技能组合无法与市场上快速发展的新分析引擎、代码库和数据管理结构配合使用,这推动了对新人才的需求。”
直销公司 HackerAgency 的营销科学执行总监 Seth Garske 指出,许多 IT 主管可能发现自己不确定处理分析的最佳方式,尤其是考虑到分析与其他部门的重叠。 “虽然分析在本质上往往是技术性的,但它实际上更像是一种业务功能,类似于财务或会计,”他解释道。 “这种误解在一些组织中造成了一些非常丑陋的地盘争夺战。”
商业和技术咨询公司 West Monroe Partners 的高级分析高级经理 Dan Magestro 认为,如果 IT 领导者投入更多时间学习分析的工作原理,以及分析过程可用于帮助其组织的方式,那么 增加采用率并化解内部对角色和责任的争论。
更深入的分析知识还可以帮助 IT 领导者理解为什么这种方法常常看起来如此神秘。 “最佳形式的数据科学是一项极具创造性的努力,”约翰斯顿说。 “管理人员不一定需要了解每个分析的内部结构,就像软件项目的所有者不需要了解底层技术内部结构一样。” 约翰斯顿说,最重要的是看到创造的价值。
与解决方案通常显而易见并被全球企业广泛采用的 IT 不同,分析流程通常是独特且个性化的。 “选择最好的分析方法有时很简单,有时很艺术,”Magestro 说。 “例如,在数据中寻找因果关系通常意味着某种回归,而在大型客户数据集中寻找相似特征可能涉及聚类算法。” 在优化营销预算时,分析专家可以从无数可以达到目的的方法中进行选择。 “在这种情况下,正确使用一种方法并根据良好的假设通常比它是否是‘最佳’方法更为重要,”Magestro 说。
设定方向
对于企业分析计划是否应该集中在 IT 或独立的分析部门内,或者分散在各个业务部门,专家们意见不一。 许多人认为,IT 最适合充当分析倡导者和技术支持者,而不是作为所有企业分析计划的基础。 “没有理由将数据分析孤立在一个部门内,”约翰斯顿说。 “相反,这是一套应该鼓励在整个企业中发展的技能。”
Johnston 声称,由于数据科学是一个快速发展的领域,因此让多个团队相互协作和相互学习具有相当大的优势,即使他们之间存在一些友好的竞争。 “不同的团队会以不同的方式做事,从而更快地探索整个领域,以便更好地发现最适合自己业务环境的方法,”他指出。 “通过让人们进出不同的团队,可以进一步鼓励这种思想的交叉授粉。”
Honaman 指出,分析卓越中心 (COE) 模型——一个领导和协调整个企业分析计划的小组或团队——已被讨论多年,但与在业务部门内嵌入分析人才相比,几乎没有得到支持。 “在传统 IT 中,通常有一个集中式模型用于整合和管理运营数据,同时为企业内的分析资源提供对该数据的访问。” 然而,除了少数例外,这种方法并不能很好地满足各个业务部门独特而专业的分析需求。
Magestro 表示,集中分析的案例在两种情况下最为有力:当数据或技能协同作用广泛分布于不同的业务职能时,或者当不太成熟的业务职能可以从中央团队提供的专业知识中受益时。 “我们看到一些案例,中央分析团队可以成为功能分析增长的临时催化剂,在这种情况下,中央团队可能最适合高度专业化的需求,例如机器学习或人工智能,”他说。
发挥领导作用
无论它们在企业中的起源方式或来源如何,所有分析项目都需要强大且知识渊博的领导。 “关键是要有一位优秀的船长掌舵,”俄亥俄大学公共管理在线硕士项目领导力和公共事务教授阿尼鲁德·鲁希尔 (Anirudh Ruhil) 说。 “你还希望团队领导者拥有丰富的可靠经验,因为这最终是衡量一名优秀分析师的标准。”
究竟由谁来领导分析项目取决于企业的分析成熟度、行业和传统、领导力以及推动其战略和增长的特定业务领域,Magestro 说。 “在一些销售驱动的企业中,营销分析的高级领导者可能比任何其他领域做出更多数据驱动的决策,”他指出。 “在具有强大中央数据管理功能的公司中,IT 领导者可能最适合提升分析能力。”
对分析人才的竞争非常激烈。 “大多数公司明智地放弃了聘请拥有三位博士学位的热门数据科学家来施展魔法的想法,而是建立了由更多初级但有能力的人组成的团队,”约翰斯顿说。 他认为,如果遵循某些原则,这种战略几乎可以在任何地方取得成功。 “你必须赋予他们成功的权力,”约翰斯顿说。 “为他们提供数据、云计算和他们需要的任何工具。”
约翰斯顿还建议管理层应该对分析团队保持宽松的控制。 “一个以高效率交付的有效团队不需要一小群人对任何其他人行使权威,”他说。 “自然地,任职时间越长的人会承担稍微高一点的责任,这仅仅是因为他们更有经验,并且可能更了解如何完成手头的任务。”
管理咨询公司 Navigate 的经理 Phil Schmoyer 表示,业务部门代表应该从一开始就参与分析项目规划,从确定要跟踪的指标到审查数据可视化仪表板。 另一方面,培训业务经理和员工解释数据不应该是一个主要问题。 “如果一个分析团队表现最佳,就不需要培训人员来解释结果,”他说。 “[工具] 的设计应该让业务部门能够直观地消化信息。”
解开谜团
Honaman 建议 IT 领导者抛开他们对分析的恐惧和怀疑,转而专注于手头的挑战:让决策者掌握可操作的见解。 “营销人员、供应链从业者、财务负责人和运营主管都对分析有兴趣和投资,这在与空间相关时创造了新的复杂性和政治,”他说。 IT 的作用是以任何可能的方式帮助创建干净、可用的数据和洞察力,以推动和推动业务决策。
IT 领导者不应将分析视为难以理解的谜团,而应努力帮助数据专家获得成功所需的数据和工具。 Johnston 说:“我们经常看到,由于强加给数据科学团队的官僚限制而不是缺乏人才,导致缺乏成功。” 他指出,例如,看到组织使数据访问过于痛苦以至于不值得追求并对可用工具施加严格限制的情况并不少见。 “这些限制很容易将生产率降低三倍或更多,”约翰斯顿说。 “你想要留住的那种雄心勃勃的人不会在这样的环境中待太久,自然选择会给你留下一个由温顺和缺乏创造力的人组成的分析团队,这些人不会提供他们所期望的价值。”
- 9 次浏览
【数据分析】数据分析:它是什么,如何使用,以及4种基本技术
QQ群
视频号
微信
微信公众号
知识星球
什么是数据分析?
数据分析是分析原始数据以得出信息结论的科学。数据分析的许多技术和过程已经自动化为机械过程和算法,用于处理人类消费的原始数据。
关键要点
- 数据分析是分析原始数据以得出有关信息的结论的科学。
- 数据分析有助于企业优化绩效、提高效率、实现利润最大化,或做出更具战略指导意义的决策。
- 数据分析的技术和过程已经自动化为机械过程和算法,用于处理人类消费的原始数据。
- 数据分析的各种方法包括观察发生了什么(描述性分析)、为什么会发生什么(诊断性分析)、将要发生什么(预测性分析)或下一步应该做什么(规定性分析)。
- 数据分析依赖于各种软件工具,包括电子表格、数据可视化、报告工具、数据挖掘程序和开源语言,以实现最大的数据操作。
了解数据分析
数据分析是一个宽泛的术语,包括许多不同类型的数据分析。任何类型的信息都可以通过数据分析技术来获得可用于改进的见解。数据分析技术可以揭示趋势和指标,否则这些趋势和指标将在大量信息中丢失。然后,这些信息可以用于优化流程,以提高业务或系统的整体效率。
例如,制造公司经常记录各种机器的运行时间、停机时间和工作队列,然后分析数据,以更好地规划工作负载,使机器运行接近峰值容量。
数据分析可以做的远不止指出生产中的瓶颈。游戏公司使用数据分析为玩家设置奖励计划,使大多数玩家在游戏中保持活跃。内容公司使用许多相同的数据分析来让你点击、观看或重新组织内容,以获得另一个视图或另一次点击。
数据分析很重要,因为它可以帮助企业优化绩效。将其纳入商业模式意味着公司可以通过确定更有效的业务方式和存储大量数据来帮助降低成本。
公司还可以使用数据分析来做出更好的商业决策,并帮助分析客户趋势和满意度,这可以带来新的更好的产品和服务。
数据分析步骤
数据分析过程包括几个步骤:
- 第一步是确定数据需求或如何对数据进行分组。数据可以按年龄、人口、收入或性别进行区分。数据值可以是数字或按类别划分。
- 数据分析的第二步是收集数据的过程。这可以通过各种来源完成,如计算机、在线来源、相机、环境来源或人员。
- 数据收集后必须进行组织,以便进行分析。这可以在电子表格或其他形式的可以获取统计数据的软件上进行。
- 然后在分析之前对数据进行清理。它被擦除和检查,以确保没有重复或错误,并且它不是不完整的。这一步骤有助于在将错误提交给数据分析师进行分析之前更正任何错误。
数据分析的类型
数据分析分为四种基本类型:
- 描述性分析:描述一段时间内发生的事情。浏览量增加了吗?这个月的销售额比上个月强吗?
- 诊断分析:这更侧重于为什么会发生一些事情。它涉及更多样化的数据输入和一些假设。天气影响了啤酒销售吗?最近的营销活动影响了销售吗?
- 预测分析:这涉及到近期可能发生的事情。上一次我们度过了一个炎热的夏天,销售情况如何?有多少天气模型预测今年夏天会很热?
- 规定性分析:这表明了一个行动方案。如果用这五个天气模型的平均值来衡量炎热夏季的可能性,并且平均值超过58%,我们应该在啤酒厂增加一个夜班,并租用一个额外的储罐来增加产量,
数据分析是金融界许多质量控制系统的基础,包括一直流行的六西格玛计划。如果你没有正确地测量某个东西,无论是你的体重还是生产线上每百万个缺陷的数量,都几乎不可能优化它。
采用数据分析的行业包括旅游和酒店业,这些行业的扭亏为盈可能很快。这个行业可以收集客户数据,找出问题所在(如果有的话)以及如何解决这些问题。
医疗保健结合了大量结构化和非结构化数据的使用,并使用数据分析快速做出决策。同样,零售业使用大量数据来满足购物者不断变化的需求。零售商收集和分析的信息可以帮助他们识别趋势、推荐产品并增加利润。
数据分析技术
数据分析师可以使用多种分析方法和技术来处理数据和提取信息。一些最流行的方法包括:
- 回归分析。需要分析因变量之间的关系,以确定一个变量的变化如何影响另一个变量。
- 因子分析。需要取一个大的数据集,并将其缩小为一个较小的数据集。这种策略的目的是试图发现隐藏的趋势,否则这些趋势将更难看到。
- 队列分析。是将数据集分解为相似数据组的过程,通常是将其分解为客户人口统计。这允许数据分析师和数据分析的其他用户进一步深入研究与特定数据子集相关的数字。
- 蒙特卡罗模拟。模拟不同结果发生的概率。它们通常用于降低风险和预防损失。这些模拟包含多个值和变量,通常比其他数据分析方法具有更大的预测能力。
- 时间序列分析。跟踪一段时间内的数据,并巩固数据点的值和数据点的出现之间的关系。这种数据分析技术通常用于发现周期性趋势或预测财务状况。
数据分析工具
除了广泛的数学和统计方法来处理数字外,数据分析的技术能力也在迅速发展。数据分析师拥有广泛的软件工具来帮助获取数据、存储信息、处理数据和报告发现。
数据分析一直与电子表格和Microsoft Excel有着松散的联系。数据分析师还经常与原始编程语言交互,以转换和操作数据库。
数据分析师在报告或交流调查结果时也有帮助。Tableau和Power BI都是数据可视化和分析工具,用于编译信息、执行数据分析,并通过仪表板和报告分发结果。
其他工具也在出现,以帮助数据分析师。SAS是一个可以帮助数据挖掘的分析平台。Apache Spark是一个用于处理大型数据集的开源平台。数据分析师拥有广泛的技术能力,可以进一步提高他们为公司带来的价值。
数据分析的作用
数据分析可以通过关注模式来提高许多行业的运营、效率和绩效。实施这些技术可以给公司和企业带来竞争优势。该过程包括四个基本的分析步骤。
数据挖掘
顾名思义,这一步骤涉及从广泛的来源“挖掘”或收集数据和信息。然后将各种形式的信息重新创建为相同的格式,以便最终进行分析。这个过程可能需要相当长的时间,比任何其他步骤都要长。
数据管理
数据需要一个数据库来包含、管理并提供对通过挖掘收集的信息的访问。因此,数据分析的下一步是创建这样一个数据库来管理信息。SQL是数据分析早期用于此目的的常用工具,到2023年仍在广泛使用。这种计算语言创建于1979年,允许查询关系数据库,并更容易地分析生成的数据集。
统计分析
第三步是统计分析。它涉及将收集和存储的数据解释为模型,有望揭示可用于解释未来数据的趋势。这是通过Python等开源编程语言实现的。更具体的数据分析工具,如R,可以用于统计分析或图形建模。
数据展示
数据分析过程的结果是要共享的。最后一步是格式化数据,以便其他人可以访问和理解,尤其是公司中负责增长、分析、效率和运营的个人。拥有访问权限对股东也有好处。
数据分析的重要性和用途
数据分析是企业成功概率的重要组成部分。收集、整理、分析和呈现信息可以显著增强和造福社会,尤其是在医疗保健和犯罪预防等领域。但是,数据分析的使用对那些希望在隔壁业务中占据优势的小企业和初创公司同样有利,尽管规模较小,
为什么数据分析很重要?
在商业模式中实施数据分析意味着公司可以通过确定更有效的经营方式来帮助降低成本。公司还可以使用数据分析来做出更好的商业决策。
什么是四种类型的数据分析?
数据分析分为四种基本类型。描述性分析描述了一段时期内发生的事情。诊断分析更多地关注事情发生的原因。预测分析转向了近期可能发生的事情。最后,规范性分析提出了一个行动方案。
谁在使用数据分析?
数据分析已经被几个可以快速扭转局面的行业所采用,例如旅游和酒店业。医疗保健是另一个结合了大量结构化和非结构化数据使用的行业,数据分析可以帮助快速做出决策。零售业还使用大量数据来满足购物者不断变化的需求。
底线
在一个越来越依赖信息和收集统计数据的世界里,数据分析有助于个人和组织确保他们的数据。一组原始数字可以使用各种工具和技术进行转换,从而产生信息丰富、富有教育意义的见解,从而推动决策和深思熟虑的管理。
- 6 次浏览
【数据分析】用于洞察和可视化的数据和分析
构建从任何类型的源(包括Web和社交源)收集数据的解决方案。 借助这些解决方案,您可以使用分析引擎来存储,分析和报告数据,从而推动可操作的洞察和可视化。
数据是基础
管理数据如此具有挑战性和复杂性的原因在于,数据本身并不起作用。 数据是惰性的; 它不是自我组织甚至是自我理解。 在DIKW金字塔中,数据是感知有用性最少的基础。 信息的价值高于数据,知识的价值高于信息,智慧的价值最高。 数据需要其他东西 - 程序,机器,甚至是人 - 来提升价值链并成为信息。

IBM AI Ladder也从数据开始。当您在数据之上执行分析,机器学习或人工智能等业务辅助功能时,您将获得更高的业务价值。正如IBM总经理Rob Thomas在他的博客“数据科学更快”中所说,“没有IA(信息架构)就没有AI。”
数据本身是惰性的。数据需要软件(或人员)使数据显示为活动(或可操作)并产生积极,中立或消极的影响。
Neal Fishman,SOA中的病毒数据:企业大流行,IBM出版社
收集,组织和分析数据
今天,我们的用户可能可以访问太字节,千兆字节甚至数十亿字节的数据。但是,如果不收集,组织,管理,控制,丰富,管理,衡量和分析数据,那么这些数据不仅无用 - 它可能成为一种负担。
这些活动构成了数据和分析平台的焦点,如IBM Analytics产品的三大支柱所示:

数据作为差异化因素
您的数据需要成为公司资产。数据有能力改变您的组织,增加货币价值,并使您的员工能够完成非凡的事情。数据驱动的文化可以实现更高的业务回报。
你可以在没有太多计划的情况下建造一座狗屋,但你不能用同样的方法建造一座现代化的摩天大楼。复杂混合云拓扑中保留数据的规模需要规范,即使对于采用敏捷和适应性理念的组织也是如此。
数据可以而且应该用于推动分析见解。但是,需要哪些考虑因素和计划活动才能产生洞察力,采取行动的能力以及做出决策的勇气?尽管最大限度地提高数据实用性的规划和实施活动可能需要深入思考,但您的组织可以在短时间内以数据为中心和数据驱动。
企业需要迅速行动。您的组织必须尽快响应不断变化的需求,否则就有可能变得无关紧要。这适用于私人或公共组织,无论大小。
数据和相关分析是区分的关键,但传统方法通常是临时的,天真的,复杂的,困难的和脆弱的。这可能导致延迟,业务挑战,机会丧失以及未授权项目的增加。
使数据启用并激活
启用和激活数据有五个关键原则:
- 制定数据战略
- 开发数据架构
- 为分析开发数据拓扑
- 制定统一治理方法
- 开发一种最大化数据消费可访问性的方法
如果数据是推动者,则可以将分析视为正在启用的核心功能之一。
分析可以是一个复杂且涉及的学科,包含广泛而多样的工具,方法和技术。 IBM AI Ladder的一端是通过静态格式的数据启用的,例如预建报告;另一端是通过深度学习和先进的人工智能实现的。在这两端之间,启用方法包括诊断分析,机器学习,统计,定性分析,认知分析等。机器人,软件界面或人类可能需要在单个任务中应用多种技术,或者跨越他们在驱动洞察力,采取行动,监控和制定决策时所执行的角色。
管理开发生命周期
大多数组织需要管理软件生命周期。 上面列出的关键原则意味着需要一个单独的数据生命周期,因为任何关键原则的结果或可交付成果都不应被视为静态和不可变的。 与数据一样,您可以将分析视为具有独立于软件生命周期和数据生命周期的自己的生命周期,尽管它们都是互补的。
为了帮助实现数字化转型,您的组织应采用三个开发生命周期:
- 软件应用
- Analytics(分析)
- 数据

每个开发生命周期都代表了一个迭代工作流,敏捷开发团队可以使用它来制定更高价值的业务成果。生命周期通常是时间盒迭代,可以遵循快速失败的范例来实现有形资产。速度在业务中很重要;大多数企业都在努力快速满足新的需求。每个生命周期迭代的目标是在最大化业务价值的同时高效,熟练地解决业务速度问题。
软件/应用程序开发生命周期(SDLC)是众所周知的,它支持传统和敏捷开发。 SDLC重复整合业务需求。
分析开发生命周期(ADLC)支持IBM AI Ladder中的全部分析工作。此生命周期包含模型开发和修复,以避免漂移。由于分析的目的之一是实现行动或决策,因此ADLC依靠反馈机制来帮助增强机器模型和整体分析环境。反馈机制的一个示例是捕获关于行动或决策的积极或消极影响或结果的数据点。 ADLC迭代数据。
数据开发生命周期(DDLC)将数据管理理念置于一个有机且不断发展的循环中,更适合于不断变化的业务需求。 DDLC受SDLC和ADLC的影响。它迭代了业务需求的整合和数据的表现。
虽然这三个生命周期是独立的,但您可以将它们结合使用并建立依赖关系以帮助推动业务成果。每个生命周期都应该是敏捷的,并且应该合并到DevOps流程中以进行开发和部署。

三个生命周期的交叉点突出了统一治理的必要性。软件/应用程序和数据之间的交集突出了信息的集成和访问路径。数据和分析之间的交集突出了集成和底层数据存储。分析和软件/应用程序之间的交集突出了集成以及API或其他数据交换技术的使用,以帮助解决复杂的算法或访问要求。
使用DataFirst进行云的Garage方法
组织中的每个部门对数据和分析都有不同的需求。您如何开始数据驱动的旅程?使用DataFirst实现云的Garage方法可提供策略和专业知识,帮助您从数据中获取最大价值。此方法从利用数据和分析而非技术的业务成果开始。以协作方式定义焦点是获得早期结果的关键。您的路线图和行动计划将根据经验教训不断更新。这是一种迭代且敏捷的方法,可帮助您定义,设计和证明针对特定业务问题的解决方案。

下一步是什么?
现在您已了解数据和分析的概念和价值,了解如何在数据和分析参考架构中设计数据和分析应用程序。
原文:https://www.ibm.com/cloud/garage/architectures/dataAnalyticsArchitecture
本文:http://pub.intelligentx.net/data-and-analytics-insights-and-visualization
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 56 次浏览
【数据分析】预测建模:历史、类型、应用
QQ群
视频号
微信
微信公众号
知识星球
什么是预测建模?
预测建模使用已知结果来创建、处理和验证可用于预测未来结果的模型。它是一种用于预测分析的工具,这是一种数据挖掘技术,试图回答“未来会发生什么?”
关键要点
- 预测建模使用已知结果来创建、处理和验证可用于进行未来预测的模型。
- 回归和神经网络是两种应用最广泛的预测建模技术。
- 公司可以使用预测建模来预测事件、客户行为以及金融、经济和市场风险。
了解预测建模
通过分析历史事件,公司可以使用预测建模来增加预测事件、客户行为以及金融、经济和市场风险的概率。
快速的数字产品迁移为企业创造了大量现成的数据。公司利用大数据来改善客户与企业关系的动态。这些海量的实时数据来自社交媒体、互联网浏览历史、手机数据和云计算平台。
然而,数据通常是非结构化的,而且过于复杂,人类无法快速分析。由于数据量巨大,公司通常通过计算机软件程序使用预测建模工具。这些程序处理大量的历史数据,以评估和识别其中的模式。从那里,该模型可以提供历史记录,并评估哪些行为或事件可能再次发生或在未来发生。
财务分析师可以使用预测建模,根据建模财务数据的量化特征来估计投资结果。
预测建模的历史
只要人们有信息、数据和使用它来查看可能结果的方法,预测建模就很可能被使用。现代预测建模据说始于20世纪40年代,当时政府使用早期的计算机来分析天气数据。在接下来的几十年里,随着软件和硬件功能的增强,大量数据变得可存储,更容易访问以进行分析。
互联网及其连接允许任何有权访问的人收集、共享和分析大量数据。因此,建模已经发展到几乎涵盖商业和金融的所有方面。例如,公司在创建营销活动时使用预测模型来衡量客户的反应,财务分析师则使用它来估计股市的趋势和事件。
预测建模的类型
几种不同类型的预测建模可用于分析大多数数据集,以揭示对未来事件的见解。
分类模型
分类模型使用机器学习根据用户设置的标准将数据放入类别或类中。有几种类型的分类算法,其中一些是:
- 逻辑回归:对事件发生的估计,通常是二元分类,如是或否。
- 决策树:将一系列的是/否、如果/其他或其他二进制结果放入称为决策树的可视化中。
- 随机森林:一种使用分类和回归结合不相关决策树的算法。
- 神经网络:机器学习模型,用于审查大量数据,以寻找只有在审查了数百万个数据点后才会出现的相关性。
- 朴素贝叶斯:一个基于贝叶斯定理的建模系统,用于确定条件概率。
聚类模型
聚类是一种对数据点进行分组的技术。分析人士认为,相似组中的数据应该具有相同的特征,而不同组中的资料应该具有非常不同的性质。一些流行的聚类算法包括:
- K-Means:K-Means是一种建模技术,使用组来识别不同数据组的中心趋势。
- 均值偏移:在均值偏移建模中,算法会偏移一组的均值,从而识别“气泡”或密度函数的最大值。当在图形上绘制点时,数据似乎是围绕称为质心的中心点分组的。
- 基于密度的带噪声空间聚类(DBSCAN):DBSCAN是一种基于数据点之间建立的距离将数据点分组在一起的算法。该模型建立不同组之间的关系并识别异常值。
异常值模型
数据集总是有异常值(正常值之外的值)。例如,如果你有数字21、32、46、28、37和299,你可以看到前五个数字有些相似,但299与其他数字相差太远。因此,它被认为是一个异常值。用于识别异常值的一些算法包括:
- 隔离林:一种检测样本中少数不同数据点的算法。
- 最小协方差行列式(MCD):协方差是两个变量之间变化的关系。MCD测量数据集的平均值和协方差,以最大限度地减少异常值对数据的影响。
- 局部异常值因子(LOF):一种识别最近相邻数据点并分配分数的算法,允许将距离最远的数据点识别为异常值。
时间序列模型
在其他类型的建模之前,时间序列建模通常使用历史数据来预测事件。一些常见的时间序列模型包括:
- ARIMA:自回归综合移动平均模型使用自回归、积分(观测值之间的差异)和移动平均值来预测趋势或结果。
- 移动平均线:移动平均线使用特定时期的平均值,如50或200天,可以消除波动。
预测建模的应用
预测分析使用预测因子或已知特征来创建模型以获得输出。预测建模的使用方式有数百种,甚至数千种。例如,投资者使用它来识别股市或个股的趋势,这些趋势可能表明投资机会或决策点。
投资者使用的最常见的模型之一是投资的移动平均线,它可以平滑价格波动,帮助他们识别特定时期的趋势。此外,自回归用于将投资或指数的过去值与其未来值相关联。
预测建模还帮助投资者识别不同情景的可能结果,从而帮助他们管理风险。例如,可以操纵数据来预测如果基本情况发生变化可能发生的情况。投资者可以通过识别可能的结果来制定应对不断变化的市场的策略。
预测建模工具
预测模型也用于人工智能(AI)领域的机器学习和深度学习等神经网络。神经网络的灵感来源于人类大脑,由分层的互连节点组成,代表着人工智能的基础。神经网络的力量在于它们处理非线性数据关系的能力。他们能够在变量之间创建关系和模式,这对人类分析师来说是不可能的,或者太耗时了。
金融公司使用的其他预测建模技术包括决策树、时间序列数据挖掘和贝叶斯分析。通过预测建模措施利用大数据的公司可以更好地了解其客户如何参与其产品,并可以识别公司的潜在风险和机遇。
预测建模的优点和缺点
预测建模的优点和缺点
优点
- 易于生成可操作的见解
- 可以测试不同的场景
- 提高决策速度
缺点
- 计算可能无法解释
- 人为输入造成的偏差
- 高学习曲线
优势说明
- 易于生成可操作的见解:预测建模使您能够查看有关数据的信息,而这些信息在其他情况下可能看不到,使您能够做出更明智的决策。
- 可以测试不同的场景:可以操纵或更改数据来测试各种场景,以评估更改可能对数据和模型产生的影响。
- 提高决策速度:决策可以更快地做出,因为数百万个数据点可以更快地分析,未来的趋势或情况可以在几分钟或几小时内理论化。
缺点说明
- 计算可能是不可解释的:一旦你创建了一个预测模型,你可能就无法解释结果。
- 人为输入造成的偏差:建模中引入偏差是因为人类参与设置参数和标准。
- 高学习曲线:学习创建预测模型和/或解释结果可能是一个漫长的过程,因为你必须理解统计数据,学习术语,甚至可能学习用Python或R编写代码。
什么是预测建模算法?
算法是一组用于操作数据或执行计算的指令。预测建模算法是执行预测建模任务的指令集。
预测建模中最大的假设是什么?
预测建模中最重要的假设是,未来的数据和趋势将遵循过去的情况。
什么是医疗保健中的预测建模示例?
预测建模可以用于许多目的,尤其是在医疗保险中。例如,它可以帮助保险公司根据特定客户的健康、生活方式、年龄和其他情况计算他们的成本。
底线
预测建模是由计算机和软件根据操作员的输入对数据进行的统计分析。它用于为从中收集数据的实体生成未来可能的场景。
它可以用于收集数据的任何行业、企业或努力。重要的是要理解预测建模是基于历史数据的估计。这意味着它不是万无一失的,也不是对给定结果的保证——它最好用于权衡选择和做出决定。
- 6 次浏览
【数据分析模型】描述性 vs 预测性 vs 规范性 vs 诊断分析
我们生活在一个以数字内容为主的时代。 现代企业必须定期处理、解释和重新配置的数据量非常庞大。 为了处理大量涌入的信息,许多企业正在转向商业智能工具,例如诊断、描述性、预测性和规范性分析。 本文将深入探讨它们之间的差异,并解释每种方法何时有用,以及如何为您的业务选择正确的分析解决方案。

分析目标
随着移动设备和物联网 (IoT) 越来越流行,数据量正在迅速增加——我们每天产生大约 2.5 万亿字节,而且这个数字还在上升。在供应链系统方面尤其如此。
研究表明,高达 73% 的企业数据从未用于分析目的。这是对资源的巨大浪费,可能会直接提高您的投资回报率、减少客户损失、提高效率或您通过收集数据尝试做的任何其他事情。如果您希望您的企业对市场及其在其中的位置有一个整体的看法,那么无懈可击的分析设置是必不可少的。它可以帮助企业降低运营成本、增加销售额、扩大产品范围并拉近与客户的距离。
当您以这种方式看待分析时,就会更容易理解为什么它们在作为一个统一系统实施时最有价值。当孤立时,叙述是不完整的——数字是有用的,但不如当它们以直观的可视化形式呈现时有用,并带有关于如何应用它们的预测或建议。您错过了改进决策所需的洞察力。
在下一节中,我们将更多地讨论分析类型之间的区别以及它们为何如此重要。分析工具不只是提出自己的问题;他们使用不同的数据提取技术来寻找答案。
什么是诊断分析?
诊断分析是高级分析的一种形式,专注于基于数据分析来解释发生某事的原因。就像医生调查患者的症状一样,他们旨在了解潜在问题并确定问题发生的原因。
它的功能允许用户通过突出显示可能需要进一步研究的领域来识别异常,当趋势或数据点提出无法轻松回答或不深入挖掘的问题时,这些领域就会被精确定位。诊断分析必须解决的一些问题包括:
- 为什么这次营销活动失败了?
- 为什么在某个地区没有增加营销关注度的情况下销售额增加了?
- 为什么本月员工绩效下降?
- 以及其他单一数据源没有明显答案的问题。
诊断分析提供数据发现、向下钻取、数据挖掘和数据关联。深入研究数据允许用户识别第一步中发现的异常的潜在来源。分析师可以使用这些功能来检查数据内部和外部的模式,以得出明智的结论。概率论、过滤、回归分析和时间序列数据分析都是与诊断分析相关的有用工具,可促进这一过程。
什么是描述性分析?
当涉及到描述性分析时,线索就在名称中:它们描述了您的业务状态。这些解决方案处理大量数据并将其重新配置为易于解释的形式,例如表格、图表或图形。该信息可以由您过去制造过程中的任何统计数据、事件、趋势或特定时间范围组成。
这些类型的分析的目的是从过去中学习。一个常见的例子是分析季节性购买趋势以确定推出新产品的最佳时间。由于消费者是习惯性动物,因此查看历史数据是预测他们的反应的有效方法。
描述性分析或统计数据可以展示从总库存到几年内销售数据进展的所有内容。他们可以显示客户花费的典型金额以及该金额是否可能在某些时候增加。如果诊断分析是关于原因的,那么描述性分析可以解释是什么。
什么是预测分析?
预测性分析和描述性分析具有对立的目标,但它们密切相关。这是因为您需要有关过去的准确信息来预测未来。预测工具试图填补可用数据中的空白。如果描述性分析回答了“过去发生了什么”这个问题,那么预测分析回答了“未来会发生什么?”这个问题。
预测分析从 CRM、POS、HR 和 ERP 系统中获取历史数据,并使用它来突出显示模式。然后,使用算法、统计模型和机器学习来捕捉目标数据集之间的相关性。
最常见的商业示例是信用评分。银行使用历史信息来预测候选人是否可能跟上付款。它对制造商的工作方式大致相同,只是他们通常试图找出产品是否会销售。预测分析专注于业务的未来。
有关更多信息,请参阅我们对预测分析的更深入细分。
什么是规范性分析?
在诊断性、预测性、描述性和规范性分析中,后者是商业智能领域的最新成员。这些工具使公司能够查看潜在的决策,并根据当前和历史数据,跟踪它们以获得可能的结果。
与预测分析一样,规范分析也不会 100% 正确,因为它们与估计一起工作。但是,它们提供了“展望未来”并在做出决策之前确定决策可行性的最佳方式。
两者之间的区别在于,规范性分析提供了关于为什么可能出现特定结果的意见。然后,他们可以根据这些信息提供建议。为此,他们使用算法、机器学习和计算建模。
如果预测分析回答,“会发生什么?”然后规范性分析回答:“我们必须做些什么来实现它?”或“这一行动将如何改变结果?” Prescriptive 更多地处理试验和错误,并且具有一些假设检验性质。
不同类型的总结
所有这些类型的分析都提供了从运营信息中提取价值的更有效方法。通过数据分析,他们支持决策制定、简化客户沟通,甚至可以增加收入。
诊断分析询问现在。他们深入了解发生某事的原因并帮助用户诊断问题。描述性分析询问过去。他们想知道业务发生了什么,以及这可能如何影响未来的销售。预测分析询问未来。这些与可能发生的结果以及最有可能发生的结果有关。最后,规范性工具询问现在对未来的影响。它想知道现在最好的行动方案,以便对未来产生积极影响。换句话说,他们是决策者。

解决方案的类型
分析调查是优化 S&OP(销售运营和计划)策略的一个组成部分。毕竟,确保制造水平有利可图的唯一方法是对需求做出合乎逻辑的、明智的预测。简而言之,您需要创建一种数据驱动的文化。
然而,找到合适的分析工具并不总是那么容易。那里有很多选择,考虑到所有不同的选择,这可能是一个令人生畏的过程。对于小型企业,建议将市场分为三种主要产品类型。
这些是诊断性、预测性、描述性和规范性分析,并非所有解决方案都执行所有这些类型的分析。首先要了解的是,虽然它们可以单独使用,但最好的结果来自所有四个的凝聚力合并。如果应用得当,它们不仅可以进行合作,还可以使您的数据分析多样化。
商业智能是提供分析能力的解决方案的最大术语,通常提供所有这些类型的分析,但有时可能只提供描述性和诊断性。在更大的总括类别中,业务分析侧重于预测性和规范性分析,大数据分析处理海量数据集,嵌入式分析可以嵌入到其他软件程序中,企业报告精简套件以提供更精简的报告工具模块。
软件选择
选择正确类型的分析软件可能意味着自信的业务决策与选择中持续的不确定性之间的差异。当您选择商业智能、业务分析、嵌入式 BI、企业报告或大数据分析工具时,本指南将为您提供清晰的前进道路。
确定要求
要确定众多分析软件选项中的哪一个最适合您,您应该首先确定您需要利用哪些要求。此 BI 要求模板将帮助您理清需要哪些要求以及哪些要求是门面的,这样您就可以为您的独特业务做出最佳选择。
比较解决方案
一旦您确定了您的关键要求,您就可以根据它们满足这些要求的程度来比较解决方案。如果您只需要识别问题,那么在诊断分析方面表现出色的解决方案可能是最佳选择。如果您想要一些可以帮助您规划解决方案的东西,那么在诊断和规范方面表现良好的平台可能更合适。
该比较报告按各个功能的得分对行业领导者进行了细分。我们建议选择前五名左右,以最符合您的需求。
请求建议
为了获得准确的报价、产品演示甚至免费试用,现在是提交 RFP(征求建议书)的时候了。此 BI RFP 指南将逐步引导您完成整个流程,以便您确切知道要包含哪些内容,以确保找到最适合您业务的产品。
结论
归根结底,诊断性、描述性、预测性和规范性分析解决方案共同构建故事。 这是一个关于您的企业拥有什么、需要什么以及可以实现什么的故事。 使用此叙述作为指导,您可以做出完全由您的数据提供信息的决策。
您的企业通过哪些分析方法取得了成功? 您对实现任何类型而不是其他类型有任何提示吗? 通过下面的评论让我们知道。
本文:https://jiagoushi.pro/data-analytics-pattern-descriptive-vs-predictive-…
- 405 次浏览
【数据可视化】Apache Superset:穷人的PowerBI ,但是很强大
Apache Superset(酝酿中)是一个现代的、企业就绪的商业智能web应用程序
重要的
免责声明:Superset是由Apache孵化器赞助的Apache软件基金会(ASF)进行孵化的一项工作。所有新接受的项目都需要孵化,直到进一步的审查表明基础设施、通信和决策制定过程已经稳定下来,与其他成功的ASF项目保持一致。虽然孵化状态不一定反映代码的完整性或稳定性,但它确实表明项目还没有完全被ASF认可。
特性概述
- 丰富的数据可视化集
- 易于使用的界面探索和可视化的数据
- 创建和共享仪表板
- 与主要的身份验证提供者(数据库、OpenID、LDAP、OAuth和REMOTE_USER通过Flask AppBuilder)集成的企业级身份验证
- 一个可扩展的、高粒度的安全/权限模型,允许关于谁可以访问单个特性和数据集的复杂规则
- 一个简单的语义层,允许用户通过定义哪些字段应该显示在哪些下拉列表中以及哪些聚合和功能指标可供用户使用来控制数据源在UI中的显示方式
- 通过SQLAlchemy与大多数讲sql的RDBMS集成
- 与Druid.io的深度集成
数据库
目前支持以下RDBMS:
还应该支持具有适当的DB-API驱动程序和SQLAlchemy方言的其他数据库引擎。
截图



原文:https://superset.apache.org/index.html
本文:
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 236 次浏览
【数据架构】社会网络分析科普
社会网络分析(SNA)是利用网络和图论研究社会结构的过程。它根据节点(网络中的个体参与者、人或事物)以及连接它们的纽带、边缘或链接(关系或交互)来描述网络结构。通常通过社交网络分析可视化的社会结构包括社交媒体网络、[2]模因传播、[3]信息流通、[4]友谊熟人网络、商业网络、社交网络、协作图、亲属关系、疾病传播和性关系。这些网络通常通过社会图来表示,其中节点表示为点,纽带表示为线。这些可视化提供了一种定性评估网络的方法,通过改变节点和边缘的可视化表示来反映感兴趣的属性。[7]
社会网络分析是现代社会学中的一项重要技术。也获得了重要的在人类学、生物学、人口、传播学、经济学、地理、历史、信息科学、组织研究、政治学、社会心理学、发展研究、社会语言学和计算机科学,现在常见的作为一个消费者的工具(见系统网络体系结构(SNA)软件列表)。[8][9][10][11]
历史
社会网络分析的理论根源在于早期社会学家的工作,如乔治•西梅尔(Georg Simmel)和埃米尔•迪尔凯姆(Emile Durkheim)。自20世纪初以来,社会学家们就一直在使用“社交网络”的概念来描述从人际关系到国际关系等各个层面的社会系统成员之间的复杂关系。20世纪30年代,雅各布•莫雷诺(Jacob Moreno)和海伦•詹宁斯(Helen Jennings)引入了基本的分析方法。[12]中国英语学习网1954年,约翰·阿伦德尔·巴恩斯开始系统地使用这个词来表示联系的模式,包括公众和社会科学家传统上使用的概念:有限的群体(如部落、家庭)和社会类别(如性别、种族)。Ronald Burt、Kathleen Carley、Mark Granovetter、David Krackhardt、Edward Laumann、Anatol Rapoport、Barry Wellman、Douglas R. White和Harrison White等学者扩展了系统社交网络分析的使用。甚至在文献研究中,网络分析也被Anheier, gerand Romo,[14] Wouter De Nooy,[15] and Burgert Senekal应用。[16]事实上,社交网络分析已经在不同的学术领域得到了应用,也在反洗钱和恐怖主义等实际应用中得到了应用。
指标
色调(从红色=0到蓝色=max)表示每个节点之间的中心性。
连接
同质性:行动者与相似或不同的人建立联系的程度。相似性可以由性别、种族、年龄、职业、教育成就、地位、价值观或任何其他显著特征来定义。[17]同质性也称为配体性。
多路性:一个连接中包含的内容形式的数量。例如,两个人是朋友,也一起工作,那么他们的多重性就是2。[19]多路性与关系强度有关。
互惠:两个行动者相互之间的友谊或其他互动的回报程度
网络闭合度:关系三元组完整性的度量。一个人对网络封闭的假设(即他们的朋友也是朋友)被称为传递性。及物性是个体或情境特征需要认知闭合的结果
接近性:演员与地理位置相近的人有更多联系的倾向
分布
桥:一种个体,它的弱连接填补了一个结构上的洞,提供了两个个体或集群之间唯一的连接。当较长的路由由于消息失真或传输失败的高风险而不可行的时候,它还包括最短的路由
中心性:中心性是指一组度量指标,旨在量化网络中特定节点(或组)的“重要性”或“影响”(在各种意义上)。测量“中心性”的常用方法有:中介中心性、接近中心性、特征向量中心性、阿尔法中心性和程度中心性
密度:网络中直接连接的比例与可能的总数之比
距离:连接两个特定角色所需的最小连接数,斯坦利·米尔格拉姆(Stanley Milgram)的“小世界实验”(small world experiment)和“六度分离”(six degrees of separation)的理念使之流行起来。
结构孔:网络的两个部分之间没有连接。发现并利用结构性漏洞可以给创业者带来竞争优势。这个概念是由社会学家罗纳德·伯特提出的,有时也被称为社会资本的另一种概念。
纽带强度:由时间、情感强度、亲密和互惠(即互惠)的线性组合来定义。强联系与同质性、接近性和传递性有关,弱联系与桥梁有关。
分割
如果每个个体都与其他个体有直接联系,那么群体就被定义为“小团体”;如果直接联系的严格程度较低,则被定义为“社交圈”;如果需要精确,则被定义为结构上具有凝聚力的群体
聚类系数:度量一个节点的两个关联是关联的可能性。聚类系数越高,说明“拉帮结派”程度越高
内聚性:行动者通过内聚纽带彼此直接联系的程度。结构内聚是指如果从一个组中移除,将断开该组的成员的最小数量
网络的建模和可视化
社交网络的可视化表示对于理解网络数据和传达分析结果具有重要意义。社会网络分析产生的数据的可视化方法有很多。许多分析软件都有用于网络可视化的模块。通过在各种布局中显示节点和纽带,并将颜色、大小和其他高级属性赋予节点,可以对数据进行探索。网络的可视化表示可能是传递复杂信息的一种强有力的方法,但仅从可视化显示解释节点和图的属性时应加以注意,因为它们可能通过定量分析较好地捕捉到结构属性的错误表示
有符号图可以用来说明人类之间的好关系和坏关系。两个节点之间的正边缘表示一种积极的关系(友谊、联盟、约会),而两个节点之间的负边缘表示一种消极的关系(仇恨、愤怒)。有符号的社交网络图可以用来预测图的未来发展。在有符号的社交网络中,存在着“平衡”和“不平衡”周期的概念。平衡循环的定义是所有符号的乘积都为正的循环。根据平衡理论,平衡图代表了一组人,他们不太可能改变他们对群体中其他人的看法。不平衡图表代表了一组人,他们很可能会改变他们对群体中其他人的看法。例如,一组3个人(a、B和C),其中a和B有正的关系,B和C有正的关系,而C和a有负的关系,这是一个不平衡的循环。这一组很可能演变成一个平衡的周期,如一个B只有一个良好的关系,并与c a和B都有负面关系利用平衡和不平衡的周期的概念,签署了社交网络的进化图可以预测。[40]
特别是当使用社会网络分析作为促进变革的工具时,不同的参与性网络映射方法已被证明是有用的。在这里,参与者/面试官通过在数据收集过程中实际绘制网络图(用笔和纸或数字)来提供网络数据。纸笔网络映射方法的一个例子是* Net-map工具箱,它还包括一些参与者属性的集合(参与者的感知影响和目标)。这种方法的一个好处是,它允许研究人员在收集网络数据时收集定性数据并提出澄清问题
社交网络的潜力
这部分可能需要清理以满足Wikipedia的质量标准。具体问题是:合并后需要更仔细的清理,如果可以,请帮助改进此部分。(了解如何以及何时删除此模板消息)
社交网络潜力(Social Networking Potential, SNP)是一个数值系数,由算法[42][43]推导而来,既表示个人社交网络的规模,也表示他们影响该网络的能力。SNP系数是Bob Gerstley在2002年首次定义和使用的。一个密切相关的术语是Alpha用户,定义为具有高SNP的人。
SNP系数有两个主要功能:
- 基于个人社交网络潜力的分类,以及
- 被调查者在定量营销研究中的权重。
通过计算受访者的SNP,并针对高SNP的受访者,定量营销研究用于驱动病毒式营销策略的强度和相关性得到了增强。
变量用于计算一个人的SNP包括但不限于:参与社交活动组成员,领导角色,识别、出版/编辑/导致非电子媒体、出版/编辑/导致电子媒体(网站、博客),和过去的频率分布的信息在他们的网络。首字母缩略词“SNP”和一些最初开发出来的用于量化个人社交网络潜力的算法,在《广告研究正在发生变化》(Gerstley, 2003)白皮书中有所描述
2004年,Ahonen、Kasper和Melkko出版了第一本书[45],讨论了Alpha用户在移动通信受众中的商业使用。Ahonen & Moore在2005年出版的《社区主导品牌》(Communities Brands)一书中,首次在社交营销智能的背景下更广泛地讨论了Alpha用户。2012年,尼古拉·格列柯(Nicola Greco, UCL)在TEDx大会上展示了社交网络的潜力,并将其与用户产生的和公司应该使用的潜在能量进行了对比,她说“SNP是每个公司都应该拥有的新资产”
实际应用
参见:社会网络分析(犯罪学)
社会网络分析在广泛的应用和学科中得到了广泛的应用。一些常见的网络分析应用包括数据聚合和挖掘、网络传播建模、网络建模和采样、用户属性和行为分析、社区维护的资源支持、基于位置的交互分析、社会共享和过滤、推荐系统开发、链接预测和实体解析。在私营部门,企业使用社交网络分析来支持活动,如客户互动和分析、信息系统开发分析、[48]营销和商业智能需求(参见社交媒体分析)。一些公共部门的应用包括制定领导者参与策略,分析个人和团体参与和媒体使用,以及基于社区的问题解决。
安全应用
社交网络分析也被用于情报、反情报和执法活动。这种技术允许分析人员绘制隐蔽组织的地图,如间谍网、有组织犯罪家庭或街头帮派。美国国家安全局(NSA)利用其秘密的大规模电子监控项目,生成对恐怖分子细胞和其他被认为与国家安全有关的网络进行此类分析所需的数据。在网络分析过程中,国安局会深入观察三个节点。社交网络的初始映射完成后,通过分析来确定网络的结构,例如确定网络中的领导者。[50]这允许军方或执法部门对处于领导地位的高价值目标发动“捕获或击毙”斩首攻击,破坏网络的功能。自911恐怖袭击事件发生后不久,美国国家安全局就一直在对通话详细记录(cdr),也就是所谓的元数据进行社交网络分析
文本分析的应用
大型文本语料库可以转化为网络,然后用社会网络分析的方法进行分析。在这些网络中,节点是社会参与者,链接是动作。可以使用解析器自动提取这些网络。然后,通过使用网络理论中的工具对包含数千个节点的最终网络进行分析,以确定关键参与者、关键社区或各方,以及总体网络的鲁棒性或结构稳定性、或某些节点的中心性等一般属性。这自动化了定量叙述分析所引入的方法,即主观-动宾三胞胎是由一对由一个动作联系起来的行动者或由行动者-客体组成的对来识别的
美国大选叙事网络[55]
互联网应用
社会网络分析也被应用于理解个人、组织和网站之间的在线行为。超链接分析可用于分析网站或网页之间的连接,以检查个人在浏览网页时信息是如何流动的。组织之间的联系已经通过超链接分析来分析问题社区中的哪些组织
社交媒体互联网应用
社交网络分析已被应用于社交媒体,作为一种工具,通过个人或组织在Twitter和Facebook等社交媒体网站上的联系来了解他们之间的行为
在计算机支持的协作学习中
计算机支持协同学习(CSCL)是目前应用SNA的主要方法之一。当应用于CSCL时,SNA被用来帮助理解学习者如何在数量、频率和长度方面进行协作,以及交流的质量、主题和策略。此外,SNA可以关注网络连接的特定方面,或者整个网络作为一个整体。它使用图形表示、书面表示和数据表示来帮助检查CSCL网络中的连接。当将SNA应用于CSCL环境时,参与者之间的交互被视为一个社交网络。分析的重点是参与者之间建立的“联系”——他们如何互动和沟通——而不是每个参与者各自的行为。
关键术语
在计算机支持的协同学习中,有几个与社会网络分析研究相关的关键术语,如:密度、中心性、独立性、超度和社会图。
- 密度是指参与者之间的“联系”。密度定义为参与者拥有的连接数,除以参与者可能拥有的连接总数。例如,如果有20个人参与,每个人都有可能与19个人建立联系。密度为100%(19/19)是系统中最大的密度。密度为5%表明19种可能的连接中只有1种
- 中心关注网络中个体参与者的行为。它衡量的是个体与网络中其他个体交互的程度。一个人在网络中与他人连接得越多,他们在网络中的中心地位就越大
度内和度外变量与中心性相关。
- 度中心性以某一特定个体为焦点;所有其他个体的中心是基于他们与“在度”个体的焦点的关系
- 外度是对中心性的一种度量,它仍然关注单个个体,但分析关注个体的外向交互作用;度外中心度的度量是焦点个体与其他人交互的次数
- 社会图是在网络中定义了连接边界的可视化。例如,一个显示参与者a的出度中心点的社会图将说明参与者a在研究网络中建立的所有出度连接
独特的功能
研究人员将社会网络分析应用于计算机支持的协作学习的研究,部分原因是它提供了独特的功能。这种特殊的方法允许研究网络学习社区中的交互模式,并有助于说明参与者与组中其他成员的交互程度。使用SNA工具创建的图形提供了参与者之间的连接和用于在组内通信的策略的可视化。一些作者还认为,SNA提供了一种分析成员参与模式随时间变化的简便方法
许多研究都将SNA应用到CSCL中。研究结果包括网络的密度与教师的存在之间的相关性,[59]更重视“中心”参与者的建议,[61]网络中跨性别互动的频率较低,[62]以及教师在异步学习网络中扮演的角色相对较小。
与SNA一起使用的其他方法
虽然很多研究已经证明了社交网络分析在计算机支持的协同学习领域的价值,但是[59]的研究人员认为SNA本身不足以完全理解CSCL。交互过程的复杂性和无数的数据源使得SNA很难对CSCL进行深入的分析。[64]研究人员指出,SNA需要与其他分析方法相补充,以形成更准确的协作学习体验图景。[65]
在CSCL的研究中,许多研究将其他类型的分析与SNA相结合。这可以称为多方法方法或数据三角剖分,这将导致CSCL研究中评估可靠性的提高。
- 定性方法——定性案例研究的原则构成了将SNA方法整合到CSCL经验研究中的坚实框架。
- 民族志数据,如学生问卷、访谈和课堂非参与者观察[65]
- 案例研究:综合研究特定的CSCL情况,并将研究结果与一般方案相关联[65]
- 内容分析:提供成员之间沟通内容的信息[65]
- 定量方法——这包括对事件进行简单的描述性统计分析,以确定无法通过SNA跟踪的群体成员的特定态度,以便发现总体趋势。
- 计算机日志文件:提供学习者如何使用协作工具的自动数据[65]
- 多维缩放(MDS):绘制行动者之间的相似度图表,使更多相似的输入数据更接近[65]
- 软件工具:QUEST、SAMSA(邻接矩阵和基于社会语法的分析系统)和Nud*IST[65]
原文:https://en.wikipedia.org/wiki/Social_network_analysis
本文:https://pub.intelligentx.net/wikipedia-social-network-analysis
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 111 次浏览
【洞察力】什么是洞察力?商业洞察与洞察营销
QQ群
视频号
微信
微信公众号
知识星球
“洞察力”一词在商业环境中非常流行,尤其是在营销、广告和商业智能领域。然而,对于洞察力是什么、它的用途以及公司如何使用它,仍然存在一些困惑。
如果你在市场营销、广告、通信、商业智能或数据分析领域工作,你可能已经知道什么是洞察力。然而,尽管洞察力是公司的重要资产,但许多企业高管和经理仍然不明白什么是洞察。
什么是洞察力?
术语“洞察力”是指理解、感知或知识。这个词有多种含义,根据研究领域的不同而有所不同。例如,心理学区分三种类型的见解:智力见解、情感见解和结构见解。
除了心理学之外,洞察这个词在商业世界中也很常见,尤其是在营销、沟通、品牌、市场研究和商业智能方面。
在这个领域,这个词的营销内涵并没有偏离其原意太远,因为洞察力基本上就是知识。然而,这不仅仅是任何一种知识或什么,在商业环境之外,我们可以通过知识来理解。
在商业中,洞察力是指增加价值并有助于创造或改进某些东西的知识。当一家公司拥有有价值的信息,使公司能够产生情报,了解正在发生的事情,为什么以及如何解决、扭转或改进某件事时,它就会有洞察力。
当我们发现能够解决商业问题的知识时,我们也会谈论见解。例如,在市场营销和广告中,尤其是在数据驱动的市场营销中,通常将洞察称为有价值的信息,这些信息提供了有关客户的关键知识——客户情报——或者将营销活动的发展称为洞察。
当然,真知灼见来自研究,如今主要来自数据分析。然而,数据并不是一种洞察力。然而,从数据中,我们可以通过数据分析、情境化、丰富化等方式获得见解。只有将数据转化为见解,公司才能进行数据驱动的转型过程。
要使数据成为洞察力,它必须至少满足以下要求:
- 提供对业务活动有用且适用的情报。
- 在决策过程中提供帮助。
- 推动策略或行动。
- 帮助解决问题、避免问题或改善业务的某些方面。
如果你想了解更多关于数据、信息和见解之间的区别,你可以阅读这篇文章:“信息和见解的区别是什么”。
为什么见解有用?
在商业世界中,当涉及到定义战略和推动旨在通过数据促进业务的行动时,见解是至关重要的。
营销洞察主要来自客户数据,用于创建活动、内容和客户体验,以更好地满足消费者的需求并提供价值。洞察也是内容个性化的基础,用于执行客户参与行动,如创建买家角色和其他类型的客户细分,优化客户体验或采取以客户为中心的战略。
除了营销之外,洞察力对任何业务领域都很有用,甚至有助于优化公司自身的业务活动、运营和工作流程,以及战略和行动计划。
5商业和营销见解的好例子
以下是10个伟大的营销或广告活动的例子,它们都是从洞察力中产生的,并证明知识是绝妙想法的引擎。
1.雀巢
2016年,雀巢对圣诞节期间负责烹饪的人如何庆祝圣诞节进行了一项调查。这项研究揭示了一些见解,比如64%的圣诞节期间做饭的人是女性,四分之一的主人吃冷饭,100%的主人认为客人没有意识到为每个人做饭的努力。雀巢随后将这些见解应用到自己的广告活动中,从而向所有人致敬:
2.宜家
为了跟上圣诞节的主题,宜家在2018年推出了一个让任何人都无动于衷的地方。这家瑞典品牌设法将其品牌与吸引所有受众的信息联系起来,解决了当前的社会问题,而这个问题也很容易与该品牌的产品联系起来。
3.乐高
20世纪90年代初,乐高在经历了多年的发展后,经历了一个停滞的阶段。尽管乐高多次试图通过扩大产品范围来振兴品牌,但在1998年,乐高在很长一段时间内首次出现财务亏损。
21世纪初,乐高试图通过彻底改变其产品系列,提供创新和不同的产品来克服这一打击。然而,他们的努力被证明是失败的,因为这些新作品并没有吸引那些相信乐高已经失去了本质的公众。
2004年至2006年间,该品牌进行了一次设计思维过程,以扭转这种局面。这一过程很长,结合了不同的创新过程,最终获得了必要的见解,制定了一个分为3个阶段的战略恢复计划,使公司取得了成功。
4.百达翡丽
2019年,男士手表品牌百达翡丽对其1996年首次推出的传奇“世代”运动的概念、平面设计和渠道进行了彻底改造。
百达翡丽明白时代在变,品牌必须适应文化和社会潮流。对此,该公司进行了一项研究,重点是找出当今“新人”的主要特征。该品牌收集了改变其活动所需的见解,该活动现在专注于“现代父亲身份”或父亲身份的新角色。
5.Spotify
Spotify在其最近的活动中成功地利用了社交媒体的力量,该活动基于对全球和个人收听率最高的播放列表的分析。
Spotify成功地将平台的用户转变为自己的广告商,为每个用户提供了一份最受欢迎的艺术家年度个性化报告,可以在社交媒体上轻松分享。
简言之,洞察力是为公司提供知识和智力的有价值信息,对公司任何领域的创建或改进或解决问题都很有用。
在数据时代,数据分析会产生真知灼见。数据分析更进一步,现在辅以人工智能、深度学习或机器学习,旨在寻找更多和/或更好的见解。
- 23 次浏览
数据分析(DA) --target
QQ群
视频号
微信
微信公众号
知识星球
什么是数据分析(DA)?
数据分析(DA)是检查数据集以发现趋势并对其包含的信息得出结论的过程。越来越多的数据分析是在专业系统和软件的帮助下完成的。数据分析技术和技术被广泛用于商业行业,使组织能够做出更明智的商业决策。科学家和研究人员还使用分析工具来验证或反驳科学模型、理论和假设。
作为一个术语,数据分析主要指各种应用程序,从基本的商业智能(BI)、报告和在线分析处理(OLAP)到各种形式的高级分析。从这个意义上说,它在本质上类似于业务分析,这是分析数据方法的另一个总括术语。不同之处在于,后者面向商业用途,而数据分析则有更广泛的关注点。然而,这个术语的宽泛观点并不普遍:在某些情况下,人们使用数据分析专门指高级分析,将BI视为一个单独的类别。
数据分析计划可以帮助企业增加收入、提高运营效率、优化营销活动并加强客户服务工作。分析还使组织能够对新兴市场趋势做出快速反应,并获得相对于商业竞争对手的竞争优势。根据应用程序的不同,分析的数据可以包括历史记录,也可以包括为实时分析而处理的新信息。此外,它可以来自内部系统和外部数据源的混合。
数据分析应用程序的类型
在高水平上,数据分析方法包括探索性数据分析(exploratory data analysis)和验证性数据分析(confirmatory data analysis )。EDA旨在发现数据中的模式和关系,而CDA则应用统计技术来确定关于数据集的假设是真是假。EDA经常被比作侦探工作,而CDA则类似于法官或陪审团在法庭审判中的工作——统计学家John W.Tukey在1977年出版的《探索性数据分析》一书中首次提出了这一区别。
数据分析也可以分为定量数据分析和定性数据分析。前者涉及对具有可量化变量的数值数据的分析。这些变量可以进行比较或统计测量。定性方法更具解释性——它侧重于理解非数字数据的内容,如文本、图像、音频和视频,以及常见短语、主题和观点。
在应用程序级别,BI和报告为业务主管和公司员工提供了有关关键性能指标、业务运营、客户等的可操作信息。过去,数据查询和报告通常由IT领域的BI开发人员为最终用户创建。现在,越来越多的组织使用自助BI工具,让高管、业务分析师和运营人员可以运行自己的临时查询并自己构建报告。
高级类型的数据分析包括数据挖掘,它涉及对大型数据集进行排序,以确定趋势、模式和关系。另一种是预测分析,旨在预测客户行为、设备故障和其他未来业务场景和事件。机器学习也可以用于数据分析,通过运行自动化算法,比数据科学家通过传统分析建模更快地处理数据集。大数据分析将数据挖掘、预测分析和机器学习工具应用于可以包括结构化、非结构化和半结构化数据的数据集。文本挖掘提供了一种分析文档、电子邮件和其他基于文本的内容的方法。
数据分析计划支持多种业务用途。例如,银行和信用卡公司分析提款和消费模式,以防止欺诈和身份盗窃。电子商务公司和营销服务提供商根据导航和页面浏览模式,使用点击流分析来识别可能购买特定产品或服务的网站访问者。医疗保健组织挖掘患者数据,以评估癌症和其他疾病治疗的有效性。
移动网络运营商检查客户数据以预测客户流失。公司参与客户关系管理分析,为营销活动划分客户,并为呼叫中心工作人员提供有关来电者的最新信息。
数据分析过程内部
数据分析应用程序不仅仅涉及分析数据,尤其是在高级分析项目中。所需的大部分工作都是在前期进行的,包括收集、整合和准备数据,然后开发、测试和修订分析模型,以确保它们产生准确的结果。除了数据科学家和其他数据分析师之外,分析团队通常还包括数据工程师,他们创建数据管道并帮助准备用于分析的数据集。
分析过程从数据收集开始。数据科学家确定特定分析应用程序所需的信息,然后自己或与数据工程师和IT人员合作,将其组装起来以供使用。来自不同源系统的数据可能需要通过数据集成例程进行组合,转换为通用格式并加载到分析系统中,如Hadoop集群、NoSQL数据库或数据仓库。
在其他情况下,收集过程可能包括从流入Hadoop的数据流中提取相关子集。然后将数据移动到系统中的一个单独分区,以便在不影响整个数据集的情况下对其进行分析。
一旦所需的数据到位,下一步就是发现并解决可能影响分析应用程序准确性的数据质量问题。这包括运行数据分析和数据清理任务,以确保数据集中的信息一致,并消除错误和重复条目。进行额外的数据准备工作,以操纵和组织数据,用于计划的分析用途。然后应用数据治理策略,以确保数据符合公司标准并得到正确使用。
从这里开始,数据科学家使用预测建模工具或其他分析软件和编程语言(如Python、Scala、R和SQL)构建分析模型。通常,模型最初针对部分数据集运行,以测试其准确性;然后根据需要对其进行修订和再次测试。这个过程被称为训练模型,直到它按预期运行。最后,模型在生产模式下针对完整的数据集运行,这可以一次性完成,以满足特定的信息需求,也可以在数据更新时持续进行。
在某些情况下,可以将分析应用程序设置为自动触发业务操作。一个例子是金融服务公司的股票交易;当股票达到一定价格时,触发器可以激活,在没有人参与的情况下买卖股票。否则,数据分析过程的最后一步是将分析模型生成的结果传达给企业高管和其他最终用户。图表和其他信息图的设计可以使调查结果更容易理解。数据可视化通常包含在BI仪表板应用程序中,这些应用程序在单个屏幕上显示数据,并且可以在新信息可用时实时更新。
数据分析与数据科学
随着自动化的发展,数据科学家将更多地关注业务需求、战略监督和深度学习。在BI中工作的数据分析师将更多地关注模型创建和其他日常任务。一般来说,数据科学家专注于产生广泛的见解,而数据分析师则专注于回答具体问题。在技术技能方面,未来的数据科学家需要更多地关注机器学习操作过程,也称为MLOps。
- 15 次浏览