架构质量
QQ群
视频号

微信

微信公众号

知识星球
- 163 次浏览
【内容重用】内容重用——是生产力的助推器还是恶性循环?
QQ群
视频号
微信
微信公众号
知识星球
单源发布是一项强大的必备功能,通常是任何专业帮助创作解决方案的三大竞争优势之一,这是有充分理由的。单一来源的可重复使用内容使您能够:
- 在整个文档中保持风格、术语、详细程度等方面的一致性。
- 避免在用户界面或工作流发生更改时进行多次更新。
- 减少审查和编辑工作量。
- 降低本地化成本。
- 自动化日常工作——重复复制相同的内容会增加日常工作,并重复您的工作。
虽然我们并不反对单源发布的好处,但在这篇文章中,我们想提醒您注意它的陷阱,以便您得到预警,并可以明智地重用内容。
在JetBrains,我们经常重复使用内容。如果您熟悉我们的IDE,您就会知道它们是建立在IntelliJ平台之上的,这意味着有很多共享内容在不同的过滤器和条件下进入多个文档实例。
这里有一个简化的方案,让您了解如何在不同的文档实例之间重用整篇文章和较小的内容块:
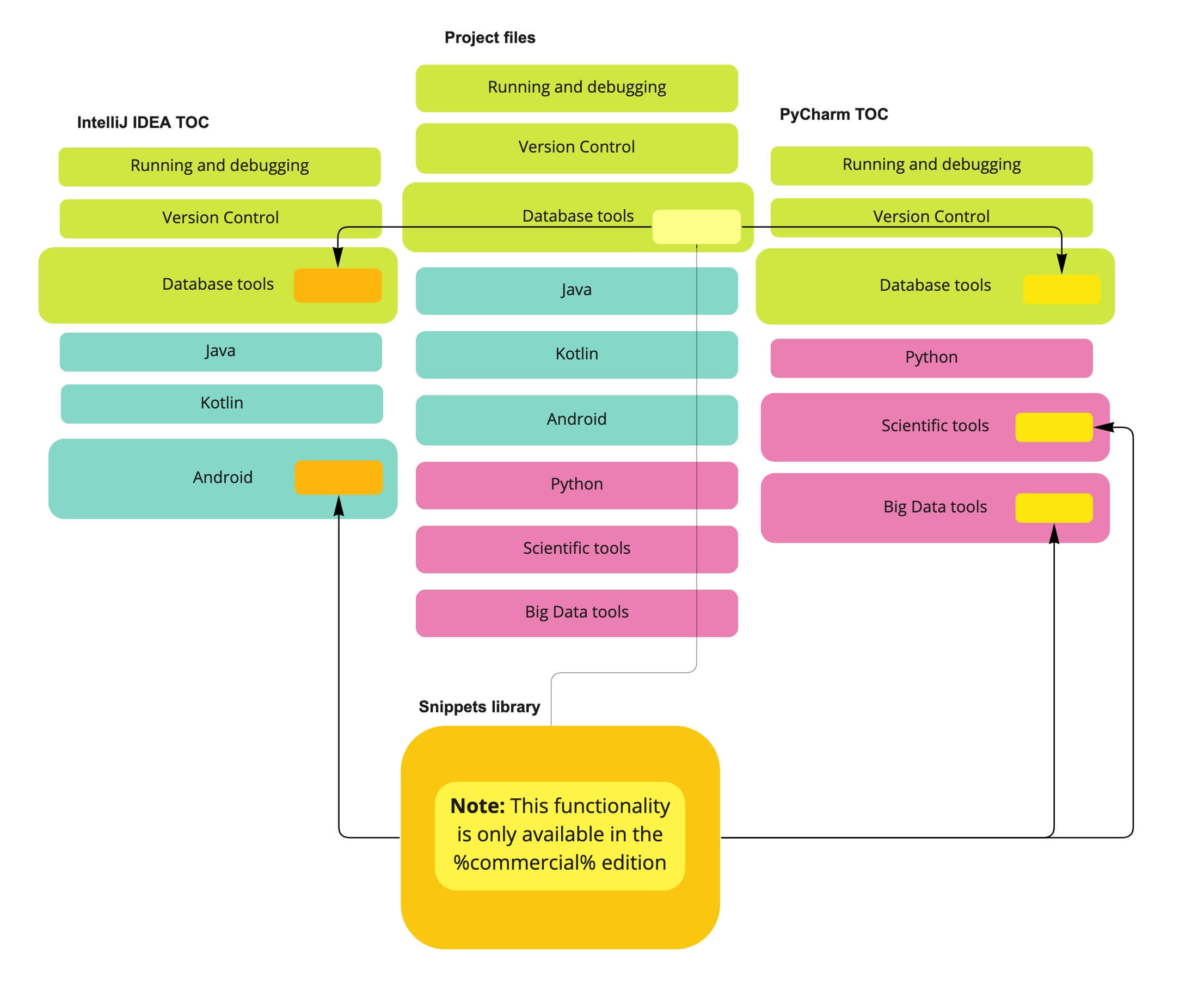
我们有21个在线帮助实例是从同一组源文件构建的,大约有20多名技术作者为这个项目做出了贡献,所以我们对单个源文件了如指掌,以前也曾陷入过它的每一个陷阱。

在这篇文章中,我们将看看其中的一些陷阱,我将其命名如下:
- 滥用重复使用
- 源代码缩减
- 重复使用的滥用
- 流量蚕食
1.滥用重复使用
具有单源功能的工具允许您在条件和筛选器下包含重复使用的内容,从而为您提供了很大的灵活性。有时候灵活性太大了,真的。
让我们看一个内容重用的例子,其中包含了过滤器是合理的条件。这里使用过滤器是因为编程语言有不同的组件。例如,在Java中,您将搜索方法的用法,而在C++中,这将被称为函数,在数据库工具中,您可以搜索表、列或键的用法。
所以这里的过滤器是合法的。
<tip-of-the-day id="FindUsages"> <p> You can view the list of all usages of a <for product="ij,py,ws,ps,rm">method</for> <for product="cl">function</for> <for product="db">table, column, or key</for> across the whole project, and quickly navigate to the selected item. </p> </tip-of-the-day>
现在我们来看另一个例子:
<tip-of-the-day id="ChangeSorting" product="ij,py,ws"> <p product="ij"> You can sort completion suggestions by relevance or alphabetically. </p> <p product="py"> By default, completion suggestions are sorted by relevance, but you can sort them alphabetically bу selecting the <control>Sort by Name</control> option. </p> <p product="ws"> To choose how you want to sort completion suggestions - by name or relevance - toggle the <control>Sort by Name</control> checkbox. </p> </tip-of-the-day>
你能猜出这里出了什么问题吗?这里的三段内容完全相同。唯一不同的是措辞和细节水平。除了标题之外,实际上这里什么都没有重复使用。
🪴 根本原因
发生这样的事情有几个原因:
- 作家们认为他们可以想出比原作更好的措辞,但他们不愿意用自己的变体取代同行的作品。
- 作者会受到用户对细节水平不满意的反馈的影响,并添加多余的信息作为对反馈的反应。
⚖️ 权衡得失
你还记得为重复使用而烦恼的原因吗?让我们对照这个例子来衡量一下:

如何避免
以下是我们在作家团队中实施的一些策略,以帮助我们防止类似的事情发生:
- 我们开发了一个内部风格指南。在许多情况下,这有助于我们避免重复使用的滥用,因为在提供多少细节、语调等方面达成了一致,所以这些东西不是作家个人品味的问题。
- 我们已经根据我们的风格约定进行了自动检查,以便在编辑器中突出显示违反风格的行为,并提示作者重新措辞。根据您使用的编辑器,有不同的方法来实现此类检查。如果你使用的是JetBrains IDE,你可能想看看Grazie Professional插件,它支持Vale语法,并内置了一些流行的风格指南。
- 在我们的团队中,我们达成了“为自己改进——为每个人改进”的原则。你不需要害羞地为每个人改进一段文本,而不是将类似的块相乘。
- 我们还致力于实现一个语法检查器,该检查器可以检测非精确重复,并建议将它们提取到库中,以便重用。我们已经准备好使用这种linter的MVP,但我们也在研究不同的方法,这些方法可能涉及ElasticSearch、机器学习等技术。
2.源代码缩减
有时你想编辑一个页面并打开源文件,而你看到的只是几个屏幕长的网页后面的几行。你发现多个包含被包裹在一起,过滤器和变量被声明为天知道在哪里,你需要一段时间才能弄清楚你在网页上看到的文本实际上是什么。
以下是我最近在波特兰撰写文档会议上的演讲中的一个代码缩减示例:
🪴 根本原因
由于我们公司生产开发人员工具,我们作为作者与开发人员密切合作,为开发人员写作。我们通常倾向于采用开发人员的方法,甚至在IDE中编写文档。因此,我们有时会被源代码的美丽和简洁所折服,它被简化为一行代码,让你像嵌套的玩偶一样揭开它背后的内容层。
⚖️ 权衡得失
现在,让我们回顾一下我们的好处列表,并对照它们测试这个例子。

💡 如何避免
老实说,这不是我们JetBrains的冠军,但作为一个团队,你需要在重用所有可能重用的东西和保持代码可读性和可搜索性之间找到平衡。我们建议您尽量坚持以下原则:
- 仅仅因为你可以并不意味着你应该这样做。
- 有时,与其选择错误的抽象,不如选择一些重复,并忍受低于100%的重用。否则,您可能会创建僵化且难以维护和重用的源代码,从而使您的生活变得复杂。而你为减少它所做的投资永远无法收回。
3.重复使用的滥用
有时,你会意识到自己每周都会写几次相同的短语(比如设置页面的路径)。人们很自然地会想,如果你经常重复自己,你一定做错了什么,重复使用它是有意义的。
下面是一个告诉如何在IDE中配置某些内容的过程。

让我们看看第一步背后的源代码:
<include src="PREF_CHUNKS.xml" include-id="step_open_settings_page">
<var name="page_path"
value="Build, Execution, Deployment | %language% Profiler"/>
</include>
<chunk id="step_open_settings_page">
<step>
<include src="PREF_CHUNKS.hml" include-ide="open_settings_page"/>
</step>
</chunk>
<chunk id="open_settings_page">
Press <shortcut key="ShowSettings"/> to open the IDE settings and select
<control>%page_path%</control>.
</chunk>
要重用这里可能重用的所有内容,您需要引入变量并将可重用的代码段封装到另一个代码段中。所以,最后,在这个小句子后面有10行代码。我在问自己——这真的值得吗?
🪴 根本原因
在软件开发中,有一个原理叫做“DRY”。早在1999年,一本名为《务实的程序员》的书中就提出了这一观点。这里的“DRY”代表“Don't Repeat Yourself”,它旨在减少软件模式的重复,并用抽象来代替它,以避免冗余。
就像在编程中一样,这一原则经常被技术编写人员误解,他们试图重复使用任何可能重复使用的东西,并将多个可重复使用的片段包装在一起,从而创建复杂的标记结构,其中更改一个元素会破坏其他依赖元素的逻辑。
⚖️ 权衡得失

如何避免
我们能做些什么?
- 请记住,“DRY”原则并不总是有效的。如果你努力实现完美的重用,你最终可能会实现一个错综复杂的依赖球,你的队友很难理解和维护代码。
- 告诉告诉你,“DRY”原则的反义词是“WET原则,它代表“We Enjoy Typing”或“Write Every Time”,甚至“Waste Everyone’s Time”。然而,我建议相反的应该是20世纪60年代在美国海军引入的“KISS”原则,即“保持简单,愚蠢”。这表明,如果大多数系统保持简单而不是变得复杂,那么它们的工作效果最好。
- 想想其他方法来实现你的目标。在这个例子中,作者的最终目标是自动完成键入相同短语的常规任务。就像在编程语言中一样,通常有多种方法可以实现相同的目标。在这种情况下,您可以创建一个模板或一个完成模式,并为其分配一个热键组合,这样您就可以通过几次按键粘贴所需的文本。
这不是对每个人来说都更容易吗?
4.流量蚕食
在前面的四节中,我们讨论了如果内容作者不权衡内容重用的收益和可能的损失,他们可能会陷入困境。这一点影响到我们的客户——阅读技术文档的人。
当你把受众拉向多个方向时,网络内容就会被蚕食。
当您重用内容并将相同的内容块发布到网络上的多个输出时,就会发生这种情况。像谷歌这样的搜索引擎只是忽略了一些网页,因为相同的内容已经存在于不同的页面上,并且在搜索结果中排名更高。
这是一个搜索查询的例子。
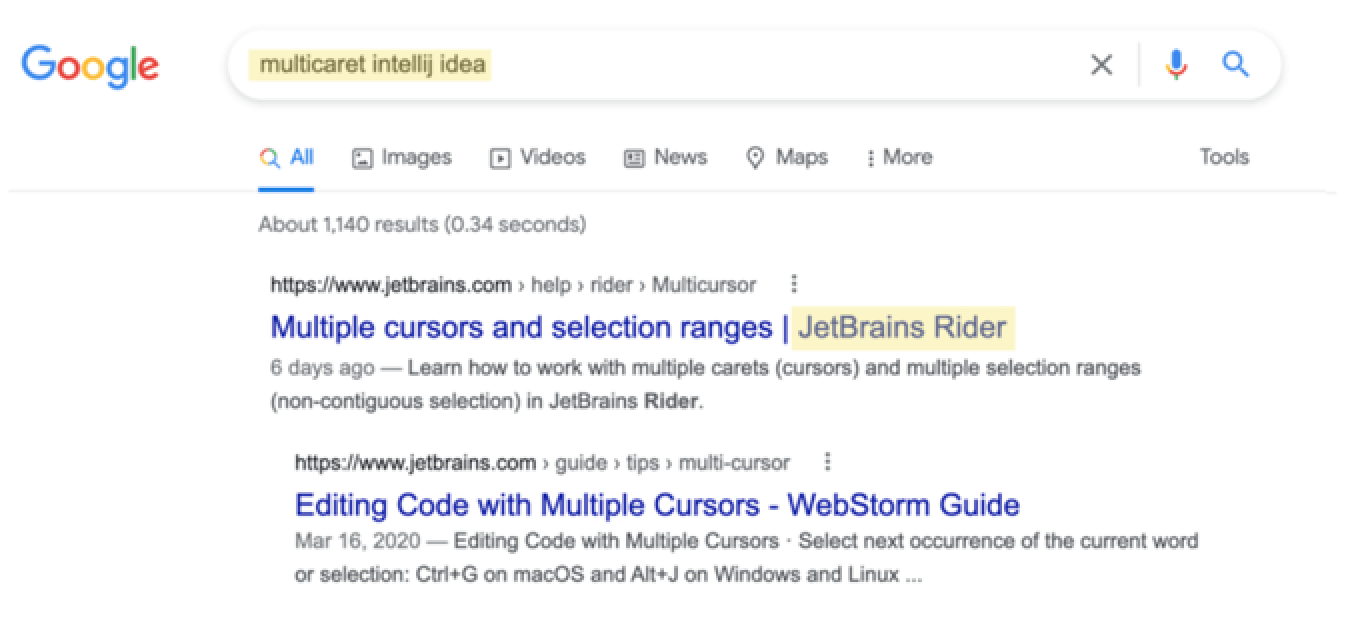
排名第一的是关于多个光标的相关文章,只在JetBrains Rider(一种不同的JetBrains产品)中,而不是IntelliJ IDEA中。
本文的内容来源单一,出于某种原因,谷歌认为Rider文档中的页面更具相关性。
🪴 根本原因
我们的SEO专家帮助我们确定了这个问题的一些原因(尽管列表可能不完整):
- 如果内容发布得更早,则索引也会更早。因此,如果JetBrains Rider在IntelliJ IDEA发布前几周发布,那么谷歌爬虫很可能在IntelliJ IDEA文档发布前就已经为本文编制了索引。
- 页面上的内容越少,索引就越好。有时,我们团队中的文档作者会重复使用一些零碎的东西,但整个部分的架构是不同的。这正是JetBrains Rider的情况——多个插入符号的信息被放在一个独立的帮助主题中,而在IntelliJ IDEA中,它是一篇更大文章中的一章,因此包含关键字的标题级别较低。
- SEO专家还告诉我们,更多的流量和来自其他来源的页面链接也会带来更好的排名,因此JetBrains Rider文档可能在其他文章中包含更多对该部分的引用。
💡 如何避免
SEO专家告诉我们,只有当你的内容是独一无二的,你才能避免流量被蚕食。既然我们已经了解了这种现象,我们应该完全停止重复使用内容吗?显然不是。单一来源内容的收益仍然很大。
所以我的第一条建议是要意识到这个问题。预先警告就是预先准备。只要记住,在网络上发布内容后,你的工作还没有完成。写得好的文档具有巨大的营销潜力,所以你总是需要尽你所能确保它有效、可发现和可访问,并在需要时采取行动。
当涉及到行动时,您可以执行以下操作:
- 如果您重用的是内容片段而不是整篇文章,则可以将包含更多关键字的元数据嵌入到源中,以帮助搜索引擎区分不同的目标输出。
- 安排更新,以确保包含可重复使用的新内容的不同文档实例不会以多周的间隔发布。
- 就最佳文章长度达成一致,这样相同的内容就不会出现在不同文档交付物的不同嵌套级别上。
- 考虑使用其他方法来区分不同类型的内容。例如,使用选项卡。
让我给你举个例子:
在这里,您可以创建三篇独立的文章,告诉用户如何在不同的操作系统上安装IntelliJ IDEA,每一篇文章都包含一些对重用内容的引用。然而,这实际上会用几乎相同的内容将受众拉向不同的方向,搜索引擎可能会将访问量最大的页面排名更高,这取决于哪种操作系统在IntelliJ IDEA用户中更受欢迎。
相反,您可以将这些类型的内容分成选项卡,以确保读者能够在同一页面上登录,并能够快速导航到他们需要的说明。
关键点
让我们总结一下JetBrains在经历了大约十年的内容重用陷阱后得出的结论。
- 每当你决定重用某些内容时,一定要权衡利弊。确保你让你的生活(或你同事的生活)变得更轻松,并且这是值得的。
- 在暗示复杂逻辑的可重用内容块之间创建依赖关系时要小心。旨在创建独立的可重用块,其逻辑不会因父片段的微小更改或对一堆相互覆盖的过滤器的修改而中断。在重用内容和保持源代码可读性和可维护性之间取得平衡。
- 记住,仅仅因为你能做到并不意味着你应该做到。不要误解“DRY”原则。有时,为了更简单的解决方案而牺牲完美的重用是明智的。
- 问问自己,您正试图通过内容重用来解决哪个问题。也许你会发现你的问题还有其他更简单的解决方案。想想我们的例子,我们建议通过在同一篇文章中创建模板、配置完成模式或在选项卡之间拆分类似内容来自动化日常工作。
- 请记住,当内容发布到网络上时,您的工作还没有完成。在您进行任何重大更改或发布任何新内容后,请始终检查它是否可被发现。归根结底,如果你的内容没有到达你的读者手中,那么它是否有用并不重要。
我们希望这些提示能帮助您负责任地重复使用内容!
- 12 次浏览
【可重用性】重复使用的失信承诺
QQ群
视频号
微信
微信公众号
知识星球
重用是IT的圣杯:每当一个新的架构范式来到IT小镇时,“重用”就是为什么要采用该范式的核心论点之一。商业销售宣传通常是这样的:“切换到将花费一些前期资金,但由于它能够重复使用,它很快就会得到回报”。
我不知道你的经历,但我从未真正看到它以承诺的方式发挥作用。无论你看面向对象、CORBA、基于组件的体系结构、EJB、SOA,你都能想到:重用的实现程度比承诺的要小得多,这意味着承诺的业务案例从未实现。此外,往往在一段时间后出现了非常脆弱和紧密耦合的系统,这些系统很难更改和操作,即业务案例开始变成相反的情况。但幸运的是,在这个时候,通常下一个圣杯范式出现了,周期又开始了。
简而言之:基于任何架构范式的重用从来没有像承诺的那样奏效,承诺总是被打破。
今天呢?目前,微服务是当今的典范,当然,重复使用是伴随它而来的商业案例承诺。这次行吗?我们终于找到了承诺已久的银弹了吗?
我不知道你对此的看法,但我相信,如果我们在微服务方法中推动重用,我们将再次面临一个完全混乱的架构,包括一个非常糟糕的商业案例。
这就引出了一个问题:为什么重复使用的承诺被打破了?
重用承诺被打破的原因有几个。以下是我可能不完整的观察结果:
首先,良好的可重用性是昂贵的。Fred Brooks多年前为可重用组件创造了“9规则”(这里的“组件”仅指重用的基本构建块,没有附加额外的语义)。根据他的观察,与仅为简单使用而设计的组件相比,设计一个可以正确重复使用的组件所花费的精力大约是其三倍。这与这样一个事实有很大关系,即很难在组件中隔离正确的责任,然后设计一个好的API来向其他人提供功能。想出这样一个组件需要大量的脑力和反复试验。
布鲁克斯还观察到,要使组件做好重复使用的准备,还需要另外三个因素,即所需的测试、硬化和文档。最后,他指出这两个因素是独立的,即它们不相加,而是相乘。这3乘3得出了“9法则”。
你可能会说Fred Brooks对他的言论过于悲观,我们无法将70年代初的软件开发(当他发表言论时)与今天的软件开发进行比较。你可能是对的。事情已经发生了变化,可能会变得更好(尽管我还没有看到任何证据)。因此,也许9的因素在今天太高了,也许把一个简单的项目结果变成一个可重用的组件只需要5倍的努力,即为正确的责任封装、良好的API、额外的测试、文档和强化而付出额外的努力。
这意味着,为了摊销投资,您需要对一个可重复使用的组件进行至少5次的重复使用,并且您需要更高的重复使用系数来证明典型的重复使用商业案例的合理性,该案例声称您不仅可以摊销投资,而且可以随着时间的推移节省大量资金。
但是,如果你查看很少发布的SOA计划的重用数量(有趣的事实:如果你在网上搜索,你会发现大量的页面谈论重用对SOA有多重要,以及衡量重用有多重要。但你几乎找不到任何页面显示SOA计划实现的真实重用数量),你会意识到,一项服务的典型平均使用率是一点(1.x)。换句话说:大多数服务只使用过一次,少数服务(通常不到20%)使用过多次。让我们回顾一下:服务的创建成本是可重复使用的成本的五倍,平均使用次数略多于一次。这就是商业案例…
理解商业案例已经破裂是一回事。但更重要的是要认识到,重用比预期的要少得多,因此重用对任何架构范式来说都比通常声称的要重要得多。
在那句话之后,你经常会发现那些黑白相间的人会立即喊道:“所以,你告诉我们,我们根本不应该重复使用,每个人都应该重新开始写自己的字符串库!”——当然,这是胡说八道。但是,像所有极端一样,将一种说法扭曲到其绝对极端是没有意义的,这并不能证明这种说法本身是没有道理的。
关于重用的要点是,大多数可以经常重用的东西都已经实现了,因此投入精力使其可重用是有意义的。这些库通常是编程语言生态系统的一部分,无论它们是语言本身的一部分还是作为第三方库提供。就投资成本与重复使用率而言,更高级别的可重复使用组件,尤其是公司特定的业务组件,很少值得付出努力。
即使您可能拥有值得封装在可重用组件中的IT资产,也不需要新的体系结构范式:每种编程语言、每种通信协议都提供了定义接口的方法。这就是实现封装所需要的全部内容,封装是重用的基本构建块。一切都在那里,一直都在那里——不需要什么新的东西。
但我们面临着一个困境:我们想获得一种新的、闪亮的银弹式架构范式,这种范式风靡一时,因此做出了重复使用的承诺——现在我们必须实现。这通常是如何实现的?首先,我们承诺将重复使用作为我们商业案例的一部分。因此,我们在设计整个应用程序时都考虑到了重用。重复使用成为设计的驱动因素,组件必须相互重复使用,无论这是否有意义。我们承诺重复使用。因此,无论成本如何,都必须进行重复使用。
实现这一点时,我们通常会陷入一堆紧密耦合的组件中,这些组件以奇怪的方式相互使用。我们尤其没有花时间了解如何最好地设计组件,哪些边界和API会随着时间的推移而出现,哪些想法有效,哪些无效。Fred Brooks描述道,正如我们承诺的那样,重复使用将降低成本,组件需要便宜且可立即重复使用,而不需要付出努力,使其真正可重复使用。
除了其他不良影响外,这还导致了一种非常恶劣的过早优化:我们试图猜测一个组件可能以何种方式被重新使用,但由于在最初设计时我们通常对它没有真正的想法,我们只是第一次猜测并将其抛向世界。因为我们对潜在用户一无所知,所以我们只创建了一个“通用”组件,在其API中提供其内部概念。这样,我们最终得到的基本上与可重复使用的组件完全相反。
为什么我们最终会得到与可重复使用组件相反的结果?这至少有两个原因:
- 首先,由于我们不知道组件需要提供哪些可变性点来满足其客户的实际需求,我们通常会实现太多的可变性点,从而大大增加组件及其接口协议的意外复杂性。换句话说:组件变得比所需的更难使用,更难理解,整个系统的复杂性将高于所需。
- 其次,“通用”的、由提供者驱动的API往往会在提供者和客户端之间建立紧密的耦合,因为在设计时,由于您没有任何关于使用模式和客户端需求的经验,您只需要通过API将组件提供的一切具体化。这样,API是由实现驱动的,而不是由客户端驱动的,这会增加两个不良影响:
- 首先,客户端与组件的实现紧密耦合(由于在设计时缺少替代方案,通过API将其外部化),通常需要比客户端所需的更细粒度的组件访问协议。
- 其次,在客户端开始使用组件后,很难更改组件的实现,因为该实现是通过API外部化的。
- 这样,我们最终会得到一个过于复杂、紧密耦合、脆弱且难以改变的系统景观——这与我们想要实现的目标相反。即使我们最终能够根据实际客户需求制定出更好的责任封装和访问协议,我们也很难改变我们最初创建的过于复杂和高度依赖的系统。这一切都是因为我们从一个基于重用的商业案例开始,以掌握新的闪亮范式。
这不仅仅是理论。基本上,这些年来我看到的每一个考虑到重复使用的系统都和我刚才描述的一样。有时(尤其是在SOA计划中),情况甚至更糟,因为设计者选择了“分层体系结构”。
分层架构模式在一个组件内经常被打破,但在定义上是松散耦合的组件之间(因此顺便说一句,需要尽可能地自我依赖),它非常接近于可以想象到的最糟糕的设计:极度紧密耦合的组件、过长的调用链(通常跨越流程边界)、非常高的结构复杂性,由于每一个请求都涉及到许多组件,因此在运行时非常脆弱,极难更改——简而言之:从架构的角度来看,我们想要实现的目标近乎噩梦。
毕竟:我们能从中学到什么?
- 首先:永远不要把架构决策建立在重用的基础上。它永远不会起作用,你通常会在与你想去的地方完全相反的地方结束。
- 您不需要任何特殊的体系结构范式来进行重用。重复使用所需的一切都已准备就绪,包括电池。
- 再次使用出现。不要计划。设计一个好的可重复使用的组件需要大量的工作、试错和与真实客户的实际经验,该组件封装了正确的责任,并通过一个良好的客户端驱动和易于理解的API提供。
- 重复使用是昂贵的。要使一个组件可重复使用,需要付出很多努力。根据经验,它的成本大约是使组件可用的成本的5倍。因此,请确保付出的努力是值得的,也就是说,在使组件可重复使用之前,该组件的使用频率足够高。
- 最后一点:不要通过构建琐碎的组件或分层组件来进行廉价的重复使用。你最终会陷入一个你从未想过的地狱。
我们如何才能做得更好?
和往常一样,我没有一个完美的计划(可能根本没有完美的计划)。我的建议是选择可替换性,而不是重复使用。可替换性朝着正确的方向发展:您考虑如何将职责分开,使其具有可替换性,这会给您带来松散的耦合。您考虑将客户端与实现分离,以保持其可替换性,从而提供客户端驱动的API。
而且,如果您可能在一段时间后意识到,一个组件往往会被多次使用,那么您就要付出额外的努力,使其在额外的测试、文档和强化方面真正可重复使用。因此,我想在学习内容中再增加一行:
努力寻找可替换性,而不是重复使用。它会引导你走上正确的道路。
有最后的话吗?嗯,是的:别误会我的意思。重复使用本身并不坏。重复使用可能非常有用。例如,我非常感激,因为我不必像90年代初使用C和C++那样,在每个新项目中从头开始构建自己的字符串库。今天,在大多数编程语言中,创建HTTP客户端或服务器几乎是一件轻而易举的事,这也很好。这只是可能有一百万个重用效果很好的例子中的两个。
只是不要用重复使用来证明你的新架构玩具是合理的。它不会起作用。从不为什么?再次使用此帖子来了解…😉
- 9 次浏览
可扩展性设计
- 51 次浏览
【可扩展性】谷歌可扩展和弹性应用的模式
本文档介绍了一些用于创建具有弹性和可扩展性的应用程序的模式和实践,这是许多现代架构练习的两个基本目标。设计良好的应用程序会随着需求的增加和减少而上下扩展,并且具有足够的弹性以承受服务中断。构建和运行满足这些要求的应用程序需要仔细规划和设计。
可扩展性:调整容量以满足需求
可扩展性是衡量系统通过在系统中添加或删除资源来处理不同数量的工作的能力。例如,一个可扩展的 Web 应用程序可以很好地与一个或多个用户一起工作,并且可以优雅地处理流量的高峰和低谷。
调整应用程序消耗的资源的灵活性是迁移到云的关键业务驱动力。通过适当的设计,您可以通过移除未充分利用的资源来降低成本,而不会影响性能或用户体验。通过添加更多资源,您同样可以在高流量期间保持良好的用户体验。这样,您的应用程序可以只消耗满足需求所需的资源。
Google Cloud 提供的产品和功能可帮助您构建可扩展的高效应用:
- Compute Engine 虚拟机和 Google Kubernetes Engine (GKE) 集群与自动扩缩器集成,可让您根据定义的指标增加或缩减资源消耗。
- Google Cloud 的无服务器平台提供托管计算、数据库和其他服务,可从零请求量快速扩展到高请求量,您只需为使用量付费。
- BigQuery、Cloud Spanner 和 Cloud Bigtable 等数据库产品可以跨海量数据提供一致的性能。
- Cloud Monitoring 提供跨应用和基础架构的指标,帮助您做出以数据为依据的扩展决策。
弹性:设计以承受失败
弹性应用程序是在系统组件出现故障的情况下仍能继续运行的应用程序。弹性需要在架构的各个级别进行规划。它会影响您布局基础架构和网络的方式以及设计应用程序和数据存储的方式。复原力也延伸到人和文化。
构建和运行弹性应用程序很困难。对于可能包含多层基础架构、网络和服务的分布式应用程序尤其如此。错误和中断时有发生,提高应用程序的弹性是一个持续的过程。通过仔细规划,您可以提高应用程序抵御故障的能力。通过适当的流程和组织文化,您还可以从失败中吸取教训,以进一步提高应用程序的弹性。
Google Cloud 提供工具和服务来帮助您构建高度可用且具有弹性的应用:
- Google Cloud 服务可在全球各地的区域和地区使用,使您能够部署您的应用以最好地满足您的可用性目标。
- Compute Engine 实例组和 GKE 集群可以跨区域中的可用地区分布和管理。
- Compute Engine 区域永久性磁盘在区域中跨地区同步复制。
- Google Cloud 提供了一系列负载平衡选项来管理您的应用流量,包括可以将流量引导到离您的用户最近的健康区域的全局负载平衡。
- Google Cloud 的无服务器平台包括提供内置冗余和负载平衡的托管计算和数据库产品。
- Google Cloud 通过原生工具和与流行开源技术的集成来支持 CI/CD,以帮助自动构建和部署您的应用。
- Cloud Monitoring 提供跨应用和基础架构的指标,帮助您就应用的性能和运行状况做出以数据为依据的决策。
驱动因素和制约因素
提高应用程序的可扩展性和弹性有不同的要求和动机。也可能存在限制您实现可扩展性和弹性目标的能力的限制。这些要求和约束的相对重要性取决于应用程序的类型、用户的个人资料以及组织的规模和成熟度。
驱动力
为了帮助您优先考虑您的需求,请考虑来自组织不同部分的驱动因素。
业务驱动力
业务方面的常见驱动因素包括:
- 优化成本和资源消耗。
- 最大限度地减少应用程序停机时间。
- 确保在高使用率期间能够满足用户需求。
- 提高服务质量和可用性。
- 确保在任何中断期间保持用户体验和信任。
- 提高灵活性和敏捷性以应对不断变化的市场需求。
发展驱动力
开发方面的常见驱动因素包括:
- 最大限度地减少调查故障所花费的时间。
- 增加花在开发新功能上的时间。
- 通过自动化最大限度地减少重复劳动。
- 使用最新的行业模式和实践构建应用程序。
运营驱动力
从运营方面考虑的要求包括:
- 减少需要人工干预的故障频率。
- 增加从故障中自动恢复的能力。
- 通过自动化最大限度地减少重复劳动。
- 将任何特定组件故障的影响降至最低。
约束
约束可能会限制您提高应用程序的可扩展性和弹性的能力。确保您的设计决策不会引入或促成这些约束:
- 对难以扩展的硬件或软件的依赖。
- 对在高可用性配置中难以操作的硬件或软件的依赖。
- 应用程序之间的依赖关系。
- 许可限制。
- 您的开发和运营团队缺乏技能或经验。
- 组织对自动化的抵制。
模式和实践
本文档的其余部分定义了模式和实践,以帮助您构建弹性和可扩展的应用程序。这些模式涉及应用程序生命周期的所有部分,包括基础架构设计、应用程序架构、存储选择、部署流程和组织文化。
模式中的三个主题很明显:
- 自动化。构建可扩展且有弹性的应用程序需要自动化。自动化您的基础架构配置、测试和应用程序部署可提高一致性和速度,并最大限度地减少人为错误。
- 松耦合。将您的系统视为松散耦合的独立组件的集合,可以提供灵活性和弹性。独立性涵盖了您如何物理分配您的资源以及您如何构建您的应用程序和设计您的存储。
- 数据驱动设计。收集指标以了解您的应用程序的行为至关重要。关于何时扩展您的应用程序或特定服务是否不健康的决定需要基于数据。指标和日志应该是核心功能。
自动化您的基础架构配置
通过自动化创建不可变的基础架构,以提高环境的一致性并提高部署的成功率。
将您的基础架构视为代码
基础架构即代码 (IaC) 是一种鼓励您以处理应用程序代码的方式处理基础架构供应和配置的技术。您的供应和配置逻辑存储在源代码控制中,因此可以发现并且可以进行版本控制和审核。因为它位于代码存储库中,所以您可以利用持续集成和持续部署 (CI/CD) 管道,从而可以自动测试和部署对配置的任何更改。
通过从基础架构配置中删除手动步骤,IaC 可以最大限度地减少人为错误并提高应用程序和环境的一致性和可重复性。通过这种方式,采用 IaC 可以提高应用程序的弹性。
Cloud Deployment Manager 可让您使用灵活的模板自动创建和管理 Google Cloud 资源。或者,Config Connector 允许您使用 Kubernetes 技术和工作流来管理您的资源。 Google Cloud 还内置了对流行的第三方 IaC 工具的支持,包括 Terraform、Chef 和 Puppet。
创建不可变的基础设施
不可变基础设施是一种建立在基础设施即代码优势之上的哲学。不可变的基础架构要求资源在部署后永远不会被修改。如果需要更新虚拟机、Kubernetes 集群或防火墙规则,您可以更新源存储库中资源的配置。测试并验证更改后,您可以使用新配置完全重新部署资源。换句话说,不是调整资源,而是重新创建它们。
创建不可变的基础架构会导致更可预测的部署和回滚。它还缓解了可变基础架构中常见的问题,例如配置漂移和雪花服务器。通过这种方式,采用不可变的基础架构可以进一步提高环境的一致性和可靠性。
高可用性设计
可用性是衡量服务可用时间的比例。可用性通常用作整体服务运行状况的关键指标。高可用性架构旨在最大限度地提高服务可用性,通常通过冗余部署组件。简单来说,实现高可用性通常涉及分配计算资源、负载平衡和复制数据。
物理分配资源
Google Cloud 服务可在全球各地使用。这些位置被划分为区域和区域。您在这些区域和专区部署应用程序的方式会影响应用程序的可用性、延迟和其他属性。如需了解详情,请参阅 Compute Engine 区域选择的最佳做法。
冗余是系统组件的复制,以提高该系统的整体可用性。在 Google Cloud 中,冗余通常是通过将您的应用或服务部署到多个区域甚至多个区域来实现的。如果一个服务存在于多个专区或地区,它可以更好地承受特定专区或地区的服务中断。尽管 Google Cloud 尽一切努力防止此类中断,但某些事件是不可预测的,最好做好准备。
借助 Compute Engine 托管实例组,您可以将虚拟机实例分布在一个区域中的多个地区,并将这些实例作为一个逻辑单元进行管理。 Google Cloud 还提供区域永久性磁盘,以自动将您的数据复制到一个区域中的两个地区。
同样,您可以通过创建区域集群来提高部署在 GKE 上的应用的可用性和弹性。区域集群将 GKE 控制平面组件、节点和 Pod 分布在一个区域内的多个区域中。由于您的控制平面组件是分布式的,因此即使在涉及一个或多个(但不是全部)区域的中断期间,您也可以继续访问集群的控制平面。
支持托管服务
您可以使用托管服务将应用程序堆栈的一部分作为服务来使用,而不是独立安装、支持和操作应用程序堆栈的所有部分。例如,您可以使用 Cloud SQL 提供的 MySQL 数据库,而不是在虚拟机 (VM) 上安装和管理 MySQL 数据库。然后,您可以获得可用性服务水平协议 (SLA),并可以依靠 GCP 来管理数据复制、备份和底层基础架构。通过使用托管服务,您可以减少管理基础架构的时间,而将更多时间用于提高应用程序的可靠性。
许多 Google Cloud 托管计算、数据库和存储服务都提供内置冗余,这可以帮助您实现可用性目标。其中许多服务提供区域模型,这意味着运行您的应用程序的基础设施位于特定区域并由 Google 管理,以便在该区域内的所有区域中冗余可用。如果某个区域不可用,您的应用程序或数据会自动从该区域的另一个区域提供。
某些数据库和存储服务还提供多区域可用性,这意味着运行您的应用程序的基础架构位于多个区域。多区域服务可以承受整个区域的丢失,但通常以更高的延迟为代价。
每一层的负载均衡
负载平衡允许您在资源组之间分配流量。当您分配流量时,您有助于确保单个资源不会在其他资源闲置时变得超载。大多数负载均衡器还提供健康检查功能,以帮助确保流量不会路由到不健康或不可用的资源。
Google Cloud 提供了多种负载平衡选择。如果您的应用在 Compute Engine 或 GKE 上运行,您可以根据流量的类型、来源和其他方面选择最合适的负载平衡器类型。有关更多信息,请参阅负载平衡概述和 GKE 网络概述。
或者,某些 Google Cloud 托管服务(例如 App Engine 和 Cloud Run)会自动对流量进行负载平衡。
通常的做法是对从外部来源(例如来自 Web 或移动客户端)接收到的请求进行负载平衡。但是,在应用程序的不同服务或层之间使用负载平衡器也可以提高弹性和灵活性。为此,Google Cloud 提供了内部第 4 层和第 7 层负载平衡。
下图显示了一个外部负载均衡器,它在两个区域 us-central1 和 asia-east1 之间分配全球流量。它还显示了将流量从 Web 层分配到每个区域内的内部层的内部负载平衡。

监控您的基础架构和应用程序
在决定如何提高应用程序的弹性和可扩展性之前,您需要了解其行为。访问有关应用程序性能和运行状况的一组全面的相关指标和时间序列可以帮助您在潜在问题导致中断之前发现它们。如果确实发生了中断,它们还可以帮助您诊断和解决中断。 Google SRE 书中的监控分布式系统一章很好地概述了一些监控方法。
除了提供对应用程序运行状况的洞察之外,指标还可用于控制服务的自动缩放行为。
Cloud Monitoring 是 Google Cloud 的集成监控工具。 Cloud Monitoring 提取事件、指标和元数据,并通过仪表板和警报提供见解。大多数 Google Cloud 服务会自动将指标发送到 Cloud Monitoring,而且 Google Cloud 还支持许多第三方来源。 Cloud Monitoring 还可以用作流行的开源监控工具的后端,提供一个“单一窗格”来观察您的应用。
各级监控
收集架构中不同级别或层级的指标可提供应用程序运行状况和行为的整体图景。
基础设施监控
基础设施级别的监控为您的应用程序提供基线运行状况和性能。这种监控方法可以捕获 CPU 负载、内存使用情况和写入磁盘的字节数等信息。这些指标可以指示机器过载或未按预期运行。
除了自动收集的指标之外,Cloud Monitoring 还提供了一个代理,可以安装该代理以从 Compute Engine 虚拟机(包括在这些机器上运行的第三方应用)收集更详细的信息。
应用监控
我们建议您捕获应用级指标。例如,您可能想要测量执行特定查询需要多长时间,或者执行相关的服务调用序列需要多长时间。您自己定义这些应用级指标。它们捕获内置 Stackdriver Monitoring 指标无法捕获的信息。应用程序级别的指标可以捕获更紧密地反映关键工作流的聚合条件,并且它们可以揭示低级别基础设施指标无法揭示的问题。
我们还建议使用 OpenCensus 来捕获您的应用级指标。 OpenCensus 是开源的,提供灵活的 API,并且可以配置为将指标导出到 Cloud Monitoring 后端。
服务监控
对于分布式和微服务驱动的应用程序,监控应用程序中不同服务和组件之间的交互非常重要。这些指标可以帮助您诊断问题,例如错误数量增加或服务之间的延迟。
Istio 是一个开源工具,可提供对微服务网络的洞察和操作控制。 Istio 为所有服务通信生成详细的遥测数据,并且可以将其配置为将指标发送到 Cloud Monitoring。
端到端监控
端到端监控,也称为黑盒监控,以用户看到的方式测试外部可见行为。这种类型的监控检查用户是否能够在您定义的阈值内完成关键操作。这种粗粒度监控可以发现细粒度监控可能无法发现的错误或延迟,并揭示用户感知的可用性。
暴露您的应用程序的健康状况
高度可用的系统必须有某种方法来确定系统的哪些部分是健康的并且运行正常。如果某些资源看起来不健康,系统可以将请求发送到其他地方。通常,健康检查涉及从端点提取数据以确定服务的状态或健康状况。
健康检查是负载均衡器的主要职责。当您创建与一组虚拟机实例关联的负载均衡器时,您还定义了运行状况检查。运行状况检查定义负载均衡器如何与虚拟机通信以评估特定实例是否应继续接收流量。负载均衡器健康检查也可用于自动修复实例组,以便重新创建不健康的机器。如果您在 GKE 上运行并通过入口资源对外部流量进行负载平衡,GKE 会自动为负载平衡器创建适当的运行状况检查。
Kubernetes 内置了对 liveness 和 readiness 探针的支持。这些探针帮助 Kubernetes 编排器决定如何管理集群中的 Pod 和请求。如果您的应用程序部署在 Kubernetes 上,最好通过适当的端点将应用程序的运行状况暴露给这些探测器。
建立关键指标
监控和健康检查为您提供有关应用行为和状态的指标。下一步是分析这些指标,以确定哪些指标最具描述性或影响力。关键指标会有所不同,具体取决于应用程序部署的平台以及应用程序正在执行的工作。
您不可能只找到一个指标来指示是否扩展您的应用程序,或者某个特定服务是否不健康。通常它是多种因素的组合,它们共同表明了一组特定的条件。借助 Stackdriver Monitoring,您可以创建自定义指标来帮助捕捉这些情况。谷歌 SRE 书提倡监控面向用户的系统的四个黄金信号:延迟、流量、错误和饱和度。
还要考虑您对异常值的容忍度。使用平均值或中值来衡量健康或绩效可能不是最佳选择,因为这些衡量标准可以隐藏广泛的不平衡。因此,考虑度量分布很重要;第 99 个百分位可能比平均值提供更多信息。
定义服务水平目标 (SLO)
您可以使用监控系统收集的指标来定义服务级别目标 (SLO)。 SLO 为您的服务指定性能或可靠性的目标级别。 SLO 是 SRE 实践的关键支柱,在 SRE 手册的服务水平目标章节以及 SRE 工作手册的实施 SLO 章节中进行了详细描述。
您可以使用服务监控根据 Stackdriver Monitoring 中的指标定义 SLO。您可以针对 SLO 创建警报策略,让您知道您是否有违反 SLO 的危险。
存储指标
监控系统中的指标在短期内有助于实时健康检查或调查最近的问题。 Cloud Monitoring 会将您的指标保留数周,以最好地满足这些用例。
但是,存储监控指标以进行长期分析也很有价值。访问历史记录可以帮助您采用数据驱动的方法来优化您的应用程序架构。您可以使用在中断期间和之后收集的数据来识别应用程序中的瓶颈和相互依赖关系。您还可以使用这些数据来帮助创建和验证有意义的测试。
历史数据还可以帮助验证您的应用是否在关键时期支持业务目标。例如,这些数据可以帮助您分析您的应用程序在过去几个季度甚至几年的高流量促销活动中如何扩展。
如需详细了解如何导出和存储指标,请参阅 Stackdriver Monitoring 指标导出解决方案。
确定缩放配置文件
您希望您的应用程序在不过度配置资源的情况下满足其用户体验和性能目标。
下图显示了应用程序扩展配置文件的简化表示。该应用程序维护资源的基线水平,并使用自动缩放来响应需求变化。

平衡成本和用户体验
决定是否扩展您的应用程序从根本上说是平衡成本与用户体验。确定您可接受的最低性能水平,以及可能在哪里设置上限。这些阈值因应用程序而异,也可能在单个应用程序内的不同组件或服务中有所不同。
例如,面向消费者的 Web 或移动应用程序可能具有严格的延迟目标。研究表明,即使是很小的延迟也会对用户对您的应用的看法产生负面影响,从而导致转化率降低和注册量减少。因此,确保您的应用具有足够的服务能力以快速响应用户请求非常重要。在这种情况下,运行更多 Web 服务器的更高成本可能是合理的。
对于非业务关键型内部应用程序的成本性能比可能会有所不同,因为用户可能更能容忍小的延迟。因此,您的扩展配置文件可能不那么激进。在这种情况下,保持低成本可能比优化用户体验更重要。
设置基线资源
扩展配置文件的另一个关键组成部分是确定适当的最小资源集。
Compute Engine 虚拟机或 GKE 集群通常需要时间来扩展,因为需要创建和初始化新节点。因此,即使没有流量,也可能需要维护最少的资源集。同样,基线资源的范围受应用程序类型和流量配置文件的影响。
相反,App Engine、Cloud Functions 和 Cloud Run 等无服务器技术旨在扩展至零,并且即使在冷启动的情况下也能快速启动和扩展。根据应用程序的类型和流量配置文件,这些技术可以为您的应用程序的某些部分提供效率。
配置自动缩放
自动缩放可帮助您自动缩放应用消耗的计算资源。通常,当超出某些指标或满足条件时会发生自动缩放。例如,如果对 Web 层的请求延迟开始超过某个值,您可能希望自动添加更多机器以增加服务容量。
许多 Google Cloud 计算产品都具有自动扩缩功能。 Cloud Run、Cloud Functions 和 App Engine 等无服务器托管服务旨在快速扩展。这些服务通常提供配置选项来限制或影响自动缩放行为,但通常,大部分自动缩放行为对操作员是隐藏的。
Compute Engine 和 GKE 提供了更多选项来控制扩展行为。借助 Compute Engine,您可以根据各种输入进行扩展,包括 Cloud Monitoring 自定义指标和负载平衡器服务容量。您可以设置缩放行为的最小和最大限制,并且可以定义具有多个信号的自动缩放策略来处理不同的场景。与 GKE 一样,您可以配置集群自动扩缩器以根据工作负载或 pod 指标或集群外部指标添加或删除节点。
我们建议您根据关键应用指标、成本配置文件以及定义的最低所需资源级别配置自动缩放行为。
最小化启动时间
为了使扩展有效,它必须足够快地发生以处理不断增加的负载。在添加计算或服务容量时尤其如此。
使用预烘焙的镜像
如果您的应用在 Compute Engine 虚拟机上运行,您可能需要安装软件并配置实例以运行您的应用。虽然您可以使用启动脚本来配置新实例,但更有效的方法是创建自定义映像。自定义映像是您使用特定于应用程序的软件和配置设置的启动磁盘。
有关管理映像的更多信息,请参阅映像管理最佳实践文章。
创建映像后,您可以定义实例模板。实例模板结合了启动磁盘映像、机器类型和其他实例属性。然后,您可以使用实例模板创建单个 VM 实例或托管实例组。实例模板是保存 VM 实例配置的便捷方式,以便您以后可以使用它来创建相同的新 VM 实例。
虽然创建自定义映像和实例模板可以提高您的部署速度,但也可能会增加维护成本,因为映像可能需要更频繁地更新。有关更多信息,请参阅平衡映像配置和部署速度文档。
容器化您的应用
构建自定义 VM 实例的另一种方法是将您的应用程序容器化。容器是一个轻量级的、独立的、可执行的软件包,包括运行应用程序所需的一切:代码、运行时、系统工具、系统库和设置。这些特性使容器化应用程序比虚拟机更便携、更易于部署和更易于大规模维护。容器通常也可以快速启动,这使得它们适用于可扩展和有弹性的应用程序。
Google Cloud 提供了多种服务来运行您的应用容器。 Cloud Run 提供了一个无服务器的托管计算平台来托管您的无状态容器。 App Engine 柔性环境将您的容器托管在托管平台即服务 (PaaS) 中。 GKE 提供托管 Kubernetes 环境来托管和编排您的容器化应用程序。当您需要完全控制容器环境时,您还可以在 Compute Engine 上运行应用容器。
优化您的应用程序以实现快速启动
除了确保您的基础架构和应用程序可以尽可能高效地部署之外,确保您的应用程序快速上线也很重要。
适合您的应用的优化因应用的特性和执行平台而异。执行以下操作很重要:
- 通过分析启动时调用的应用程序的关键部分来查找并消除瓶颈。
- 通过实施延迟初始化(尤其是昂贵资源)等技术来减少初始启动时间。
- 最小化可能需要在启动时加载的应用程序依赖项。
喜欢模块化架构
您可以通过选择使组件能够独立部署、管理和扩展的架构来提高应用程序的灵活性。这种模式还可以通过消除单点故障来提高弹性。
将您的应用分解为独立的服务
如果您将应用程序设计为一组松散耦合的独立服务,则可以提高应用程序的灵活性。如果你采用松耦合的设计,它可以让你的服务独立发布和部署。除了许多其他好处之外,这种方法还使这些服务能够使用不同的技术堆栈并由不同的团队管理。这种松散耦合的方法是微服务和 SOA 等架构模式的关键主题。
当您考虑如何围绕服务划定界限时,可用性和可扩展性要求是关键维度。例如,如果给定组件的可用性要求或扩展配置文件与您的其他组件不同,则它可能是独立服务的良好候选者。
有关更多信息,请参阅将单体应用程序迁移到微服务。
以无状态为目标
无状态应用程序或服务不保留任何本地持久数据或状态。无状态模型确保您可以独立于先前的请求处理每个请求或与服务的交互。该模型促进了可扩展性和可恢复性,因为这意味着服务可以增长、缩小或重新启动,而不会丢失处理任何正在进行的进程或请求所需的数据。当您使用自动扩缩器时,无状态尤其重要,因为托管服务的实例、节点或 Pod 可能会被意外创建和销毁。
您的所有服务可能都不可能是无状态的。在这种情况下,需要明确说明需要状态的服务。通过确保无状态服务和有状态服务的清晰分离,您可以确保无状态服务的轻松可扩展性,同时为有状态服务采用更深思熟虑的方法。
管理服务之间的通信
分布式微服务架构的一个挑战是管理服务之间的通信。随着服务网络的增长,服务的相互依赖性也可能会增长。您不希望一个服务的故障导致其他服务的故障,有时称为级联故障。
您可以通过采用断路器模式、指数退避和优雅降级等技术来帮助减少过载服务或故障服务的流量。这些模式通过给过载的服务一个恢复的机会,或者通过优雅地处理错误状态来增加你的应用程序的弹性。有关更多信息,请参阅 Google SRE 书中的解决级联故障章节。
使用服务网格可以帮助您管理分布式服务的流量。服务网格是将服务链接在一起的软件,有助于将业务逻辑与网络分离。服务网格通常提供弹性功能,例如请求重试、故障转移和断路器。
使用适当的数据库和存储技术
某些数据库和存储类型难以扩展并具有弹性。确保您的数据库选择不会限制您的应用程序的可用性和可扩展性。
评估您的数据库需求
将您的应用程序设计为一组独立服务的模式也扩展到您的数据库和存储。为应用程序的不同部分选择不同类型的存储可能是合适的,这会导致异构存储。
传统应用程序通常专门使用关系数据库运行。关系数据库提供有用的功能,例如事务、强一致性、参照完整性和跨表的复杂查询。这些功能使关系数据库成为许多常见应用程序功能的不错选择。但是,关系数据库也有一些限制。它们通常难以扩展,并且需要在高可用性配置中进行仔细管理。关系数据库可能不是满足所有数据库需求的最佳选择。
非关系型数据库,通常称为 NoSQL 数据库,采用不同的方法。尽管细节因产品而异,但 NoSQL 数据库通常会牺牲关系数据库的某些功能,以提高可用性和更容易的可扩展性。根据 CAP 定理,NoSQL 数据库通常选择可用性而不是一致性。
NoSQL 数据库是否合适通常归结为所需的一致性程度。如果您的特定服务的数据模型不需要 RDBMS 的所有功能,并且可以设计为最终一致,那么选择 NoSQL 数据库可能会提供更高的可用性和可扩展性。
除了一系列关系数据库和 NoSQL 数据库之外,Google Cloud 还提供 Cloud Spanner,这是一个高度一致、高度可用且全球分布式的数据库,支持 SQL。有关在 GCP 上选择适当数据库的信息,请参阅 GCP 数据库。
实现缓存
缓存的主要目的是通过减少访问底层较慢存储层的需要来提高数据检索性能。
缓存通过减少对基于磁盘的存储的依赖来支持改进的可扩展性。由于可以从内存中处理请求,因此减少了到存储层的请求延迟,通常允许您的服务处理更多请求。此外,缓存可以减少应用程序下游服务(尤其是数据库)的负载,从而允许与该下游服务交互的其他组件也可以更轻松地扩展或完全扩展。
缓存还可以通过支持优雅降级等技术来提高弹性。如果底层存储层过载或不可用,缓存可以继续处理请求。即使从缓存返回的数据可能不完整或不是最新的,这在某些情况下也是可以接受的。
Memorystore for Redis 提供由 Redis 内存数据存储提供支持的完全托管服务。 Memorystore for Redis 为频繁访问的数据提供低延迟访问和高吞吐量。它可以部署在提供跨区域复制和自动故障转移的高可用性配置中。
现代化您的开发流程和文化
DevOps 可以被视为广泛的流程、文化和工具集合,通过打破开发、运营和相关团队之间的孤岛,提高应用程序和功能的敏捷性并缩短上市时间。 DevOps 技术旨在提高软件的质量和可靠性。
DevOps 的详细讨论超出了本文的范围,但与提高应用程序的可靠性和弹性相关的一些关键方面将在以下部分中讨论。有关更多详细信息,请参阅 Google Cloud DevOps 页面。
可测试性设计
自动化测试是现代软件交付实践的关键组成部分。执行一组全面的单元、集成和系统测试的能力对于验证您的应用程序是否按预期运行以及是否可以进入部署周期的下一阶段至关重要。可测试性是您的应用程序的关键设计标准。
我们建议您在大部分测试中使用单元测试,因为它们执行速度快且通常易于维护。我们还建议您自动化更高级别的集成和系统测试。如果您采用基础架构即代码技术,这些测试将大大简化,因为可以按需创建专用的测试环境和资源,然后在测试完成后将其拆除。
随着测试覆盖的代码库百分比的增加,您可以减少不确定性以及每次代码更改可能导致的可靠性下降。足够的测试覆盖率意味着您可以在可靠性低于可接受的水平之前进行更多更改。
自动化测试是持续集成的一个组成部分。对每个代码提交执行一组强大的自动化测试可以提供有关更改的快速反馈,从而提高软件的质量和可靠性。谷歌云原生工具(如 Cloud Build)和第三方工具(如 Jenkins)可以帮助您实施持续集成。
自动化您的部署
持续集成和全面的测试自动化让您对软件的稳定性充满信心。当它们到位时,您的下一步就是自动部署您的应用程序。部署自动化的级别取决于组织的成熟度。
选择适当的部署策略对于最大程度地降低与部署新软件相关的风险至关重要。通过正确的策略,您可以逐渐增加新版本向更多受众的曝光,并在此过程中验证行为。如果出现问题,您还可以为回滚设置明确的规定。
有关自动化部署的示例,请参阅使用 Spinnaker 在 GKE 上自动化 Canary 分析。
采用 SRE 实践来处理失败
对于大规模运行的分布式应用程序,一个或多个组件出现某种程度的故障是很常见的。如果您采用本文档中介绍的模式,您的应用程序可以更好地处理由有缺陷的软件版本、虚拟机意外终止甚至影响整个区域的基础架构中断造成的中断。
但是,即使经过精心设计的应用程序,您也不可避免地会遇到需要人工干预的意外事件。如果您采用结构化流程来管理这些事件,您可以大大减少它们的影响并更快地解决它们。此外,如果您检查事件的原因和响应,您可以帮助保护您的应用免受未来类似事件的影响。
管理事件和执行无可指责的事后分析的强大流程是 SRE 的关键原则。尽管实施 Google SRE 的完整实践对您的组织来说可能不切实际,但如果您采用最起码的指导方针,您就可以提高应用的弹性。 SRE 书中的附录包含一些可以帮助您塑造流程的模板。
验证和审查您的架构
随着您的应用程序的发展,用户行为、流量配置文件甚至业务优先级都会发生变化。同样,您的应用程序所依赖的其他服务或基础设施也可以发展。因此,定期测试和验证应用程序的弹性和可扩展性非常重要。
测试你的应变能力
测试您的应用程序是否以您期望的方式响应故障至关重要。最重要的主题是避免失败的最好方法是引入失败并从中吸取教训。
模拟和引入故障很复杂。除了验证您的应用程序或服务的行为之外,您还必须确保生成预期的警报,并生成适当的指标。我们建议采用结构化方法,在这种方法中引入简单的故障,然后逐步升级。
例如,您可能会进行如下操作,在每个阶段验证和记录行为:
- 引入间歇性故障。
- 阻止访问服务的依赖项。
- 阻止所有网络通信。
- 终止主机。
有关详细信息,请参阅 Google Cloud Next 2019 中的破解您的系统以使其牢不可破的视频。
如果您使用像 Istio 这样的服务网格来管理您的应用程序服务,您可以在应用程序层注入故障而不是杀死 pod 或机器,或者您可以在 TCP 层注入损坏的数据包。您可以引入延迟来模拟网络延迟或过载的上游系统。您还可以引入中止,它模仿上游系统中的故障。
测试你的缩放行为
我们建议您使用自动化的非功能测试来验证您的应用程序是否按预期扩展。这种验证通常与性能或负载测试相结合。您可以使用 hey 等简单工具将负载发送到 Web 应用程序。有关显示如何针对 REST 端点进行负载测试的更详细示例,请参阅使用 Google Kubernetes Engine 进行分布式负载测试。
一种常见的方法是确保关键指标保持在不同负载的预期水平内。例如,如果您正在测试 Web 层的可伸缩性,您可能会针对大量用户请求测量平均请求延迟。同样,对于后端处理功能,您可以测量任务量突然增加时的平均任务处理时间。
此外,您希望您的测试能够衡量为处理测试负载而创建的资源数量是否在预期范围内。例如,您的测试可能会验证为处理某些后端任务而创建的 VM 数量不超过某个值。
测试边缘情况也很重要。当达到最大扩展限制时,您的应用或服务的行为是什么?如果您的服务正在缩小然后负载突然再次增加,会发生什么行为?有关这些主题的讨论,请参阅旺季生产准备的负载测试部分。
永远做架构
技术世界发展迅速,云计算尤其如此。新产品和功能频繁发布,新模式出现,用户和内部利益相关者的需求不断增长。
正如云原生架构博客文章所定义的原则,始终在寻找改进、简化和改进应用程序架构的方法。软件系统是有生命的东西,需要适应以反映您不断变化的优先事项。
原文:https://cloud.google.com/architecture/scalable-and-resilient-apps
- 62 次浏览
可维护性设计
- 27 次浏览
可观察性工程
- 22 次浏览
可靠性工程
- 42 次浏览
【可用性设计】 GCP 面向规模和高可用性的设计
Google Cloud 架构框架中的这份文档提供了用于构建服务的设计原则,以便它们能够容忍故障并根据客户需求进行扩展。当对服务的需求很高或发生维护事件时,可靠的服务会继续响应客户的请求。以下可靠性设计原则和最佳实践应该是您的系统架构和部署计划的一部分。
创建冗余以提高可用性
具有高可靠性需求的系统必须没有单点故障,并且它们的资源必须跨多个故障域进行复制。故障域是可以独立发生故障的资源池,例如 VM 实例、专区或区域。当您跨故障域进行复制时,您可以获得比单个实例更高的聚合级别的可用性。有关更多信息,请参阅区域和可用区。
作为可能成为系统架构一部分的冗余的具体示例,为了将 DNS 注册中的故障隔离到各个区域,请为同一网络上的实例使用区域 DNS 名称以相互访问。
设计具有故障转移功能的多区域架构以实现高可用性
通过将应用程序架构为使用分布在多个区域的资源池,并在区域之间进行数据复制、负载平衡和自动故障转移,使您的应用程序对区域故障具有弹性。运行应用程序堆栈每一层的区域副本,并消除架构中的所有跨区域依赖关系。
跨区域复制数据以进行灾难恢复
将数据复制或存档到远程区域,以便在发生区域中断或数据丢失时进行灾难恢复。使用复制时,恢复更快,因为远程区域的存储系统已经拥有几乎是最新的数据,除了可能由于复制延迟而丢失少量数据。当您使用定期存档而不是连续复制时,灾难恢复涉及从新区域中的备份或存档中恢复数据。与激活持续更新的数据库副本相比,此过程通常会导致更长的服务停机时间,并且由于连续备份操作之间的时间间隔,可能会导致更多的数据丢失。无论使用哪种方法,都必须在新区域中重新部署和启动整个应用程序堆栈,并且在这种情况下服务将不可用。
有关灾难恢复概念和技术的详细讨论,请参阅为云基础架构中断构建灾难恢复。
设计多区域架构以应对区域中断
如果您的服务即使在整个区域发生故障的极少数情况下也需要持续运行,请将其设计为使用分布在不同区域的计算资源池。运行应用程序堆栈每一层的区域副本。
在区域出现故障时使用跨区域的数据复制和自动故障转移。一些 Google Cloud 服务具有多区域变体,例如 BigQuery 和 Cloud Spanner。为了应对区域故障,请尽可能在您的设计中使用这些多区域服务。有关区域和服务可用性的更多信息,请参阅 Google Cloud 位置。
确保不存在跨区域依赖关系,以便区域级故障的影响范围仅限于该区域。
消除区域单点故障,例如在无法访问时可能导致全局中断的单区域主数据库。请注意,多区域架构通常成本更高,因此在采用此方法之前请考虑业务需求与成本。
有关跨故障域实施冗余的进一步指导,请参阅调查文件云应用程序的部署原型 (PDF)。
消除可扩展性瓶颈
识别不能超出单个 VM 或单个区域的资源限制的系统组件。一些应用程序垂直扩展,您可以在单个 VM 实例上添加更多 CPU 内核、内存或网络带宽来处理负载的增加。这些应用程序的可扩展性受到严格限制,您必须经常手动配置它们以应对增长。
如果可能,重新设计这些组件以水平扩展,例如跨 VM 或区域进行分片或分区。要处理流量或使用量的增长,您需要添加更多分片。使用可以自动添加的标准 VM 类型来处理每个分片负载的增加。有关更多信息,请参阅可扩展和弹性应用程序的模式。
如果您无法重新设计应用程序,您可以将由您管理的组件替换为完全托管的云服务,这些云服务旨在水平扩展而无需用户操作。
过载时优雅地降低服务水平
设计您的服务以容忍过载。服务应该检测过载并向用户返回质量较低的响应或部分丢弃流量,而不是在过载下完全失败。
例如,服务可以使用静态网页响应用户请求,并暂时禁用处理成本更高的动态行为。此行为在从 Compute Engine 到 Cloud Storage 的热故障转移模式中有详细说明。或者,该服务可以允许只读操作并暂时禁用数据更新。
当服务降级时,应通知操作员纠正错误情况。
防止和缓解流量高峰
不要跨客户端同步请求。在同一时刻发送流量的客户端过多会导致流量峰值,从而可能导致级联故障。
在服务器端实施峰值缓解策略,例如节流、排队、减载或断路、优雅降级和优先处理关键请求。
客户端的缓解策略包括客户端限制和带抖动的指数退避。
清理和验证输入
为防止导致服务中断或安全漏洞的错误、随机或恶意输入,请清理和验证 API 和操作工具的输入参数。例如,Apigee 和 Google Cloud Armor 可以帮助防止注入攻击。
定期使用模糊测试,其中测试工具故意调用具有随机、空或太大输入的 API。在隔离的测试环境中进行这些测试。
操作工具应在更改推出之前自动验证配置更改,并在验证失败时拒绝更改。
以保留功能的方式进行故障保护
如果由于问题而出现故障,则系统组件应以允许整个系统继续运行的方式发生故障。这些问题可能是软件错误、错误的输入或配置、计划外的实例中断或人为错误。您的服务流程有助于确定您是否应该过度宽容或过于简单化,而不是过度限制。
考虑以下示例场景以及如何响应失败:
- 对于配置错误或空配置的防火墙组件,通常最好在操作员修复错误时失败打开并允许未经授权的网络流量在短时间内通过。此行为使服务保持可用,而不是失败关闭并阻止 100% 的流量。该服务必须依赖于应用程序堆栈中更深层次的身份验证和授权检查,以在所有流量通过时保护敏感区域。
- 但是,控制对用户数据的访问的权限服务器组件最好关闭失败并阻止所有访问。当配置损坏时,此行为会导致服务中断,但可以避免在打开失败时泄露机密用户数据的风险。
在这两种情况下,故障都应该引发高优先级警报,以便操作员可以修复错误情况。服务组件应该在失败打开方面犯错,除非它给业务带来极大风险。
将 API 调用和操作命令设计为可重试
API 和操作工具必须尽可能使调用重试安全。许多错误情况的一种自然方法是重试前一个操作,但您可能不知道第一次尝试是否成功。
您的系统架构应该使操作具有幂等性——如果您连续两次或多次对一个对象执行相同的操作,它应该产生与单次调用相同的结果。非幂等动作需要更复杂的代码来避免系统状态的损坏。
识别和管理服务依赖项
服务设计者和所有者必须维护对其他系统组件的完整依赖列表。服务设计还必须包括从依赖失败中恢复,或者如果完全恢复不可行,则优雅降级。考虑到系统使用的云服务的依赖关系和外部依赖关系,例如第三方服务 API,认识到每个系统依赖关系都有非零故障率。
当您设置可靠性目标时,请认识到服务的 SLO 在数学上受到其所有关键依赖项的 SLO 的约束。您不能比依赖项之一的最低 SLO 更可靠。有关详细信息,请参阅服务可用性的计算。
启动依赖
服务启动时的行为与其稳态行为不同。启动依赖项可能与稳态运行时依赖项有很大不同。
例如,在启动时,服务可能需要从它很少再次调用的用户元数据服务加载用户或帐户信息。当许多服务副本在崩溃或例行维护后重新启动时,副本会急剧增加启动依赖项的负载,尤其是当缓存为空且需要重新填充时。
在负载下测试服务启动,并相应地提供启动依赖项。考虑通过保存从关键启动依赖项中检索到的数据的副本来优雅降级的设计。此行为允许您的服务使用可能过时的数据重新启动,而不是在关键依赖项出现中断时无法启动。您的服务可以稍后在可行的情况下加载新数据以恢复正常操作。
在新环境中引导服务时,启动依赖项也很重要。使用分层架构设计您的应用程序堆栈,层之间没有循环依赖关系。循环依赖似乎是可以容忍的,因为它们不会阻止对单个应用程序的增量更改。但是,在灾难导致整个服务堆栈瘫痪后,循环依赖可能会导致难以或不可能重新启动。
最小化关键依赖
最小化您的服务的关键依赖项的数量,即其他组件的故障将不可避免地导致您的服务中断。为了使您的服务对它所依赖的其他组件的故障或缓慢具有更强的弹性,请考虑以下示例设计技术和原则,以将关键依赖项转换为非关键依赖项:
- 增加关键依赖项中的冗余级别。添加更多副本可以降低整个组件不可用的可能性。
- 对其他服务使用异步请求而不是阻塞响应,或者使用发布/订阅消息将请求与响应分离。
- 缓存来自其他服务的响应以从短期不可用的依赖项中恢复。
为了减少服务中的故障或缓慢对依赖它的其他组件的危害,请考虑以下示例设计技术和原则:
- 使用优先请求队列,并为用户等待响应的请求提供更高的优先级。
- 从缓存中提供响应以减少延迟和负载。
- 以保留功能的方式进行故障保护。
- 当流量过载时优雅地降级。
- 确保每次更改都可以回滚
如果没有明确定义的方法来撤消对服务的某些类型的更改,请更改服务的设计以支持回滚。定期测试回滚过程。每个组件或微服务的 API 都必须进行版本控制,并具有向后兼容性,这样前几代客户端才能随着 API 的发展继续正常工作。此设计原则对于允许逐步推出 API 更改以及在必要时快速回滚至关重要。
为移动应用程序实施回滚可能代价高昂。 Firebase Remote Config 是一项 Google Cloud 服务,可让功能回滚变得更容易。
您不能轻易回滚数据库架构更改,因此请分多个阶段执行它们。设计每个阶段以允许应用程序的最新版本和先前版本的安全模式读取和更新请求。如果最新版本出现问题,这种设计方法可以让您安全地回滚。
建议
要将架构框架中的指南应用于您自己的环境,请遵循以下建议:
- 在客户端应用程序的错误重试逻辑中使用随机化实现指数退避。
- 实施具有自动故障转移的多区域架构以实现高可用性。
- 使用负载平衡在分片和区域之间分配用户请求。
- 设计应用程序以在过载情况下优雅降级。 提供部分响应或提供有限的功能,而不是完全失败。
- 为容量规划建立数据驱动的流程,并使用负载测试和流量预测来确定何时配置资源。
- 建立灾难恢复程序并定期对其进行测试。
原文:https://cloud.google.com/architecture/framework/reliability/design-scal…
- 35 次浏览
【可靠性】建立可靠性文化
可靠性文化如何帮助团队构建更可靠的系统和流程。
当我们考虑可靠性时,我们通常会从系统的角度来考虑可靠性。现实情况是,可靠性始于人。通过鼓励站点可靠性工程师 (SRE)、事件响应人员、应用程序开发人员和其他团队成员主动考虑可靠性,我们可以更好地准备识别和修复故障模式。
在本节中,我们将解释什么是可靠性文化,如何培养和发展可靠性文化,以及它如何帮助提高我们的流程和系统的可靠性。
什么是可靠性文化?
可靠性文化是组织的每个成员都朝着最大化其服务、流程和人员可用性的共同目标而努力的文化。团队成员专注于提高其服务的可用性和性能,降低停机风险,并尽快响应事件以减少停机时间。
传统上,软件工程团队对待可靠性的方式与对待测试的方式相同:作为开发生命周期中的一个不同阶段。这导致可靠性成为质量保证 (QA) 和运营团队的唯一责任。随着系统变得越来越复杂和开发速度加快,可靠性不仅成为测试人员和运营团队之间的共同责任,而且成为构建应用程序的开发人员、领导这些团队的工程经理、解决客户痛点的产品经理,甚至是高管之间的共同责任负责预算和启动公司范围内的计划。所有这些团队都必须在使组织的服务更可靠的目标上保持一致,以便更好地为客户服务,我们将这种组织范围内的关注称为“可靠性文化”。
但是为什么我们需要一个专注于可靠性的整个文化呢?难道我们不能编写更多的自动化测试用例,或者将一个工具插入我们的 CI/CD 管道来为我们测试我们的应用程序吗?一方面,可靠性受到软件开发生命周期 (SDLC) 的所有阶段的影响,从设计一直到部署。在 SDLC 后期修复缺陷和故障模式的成本更高,特别是如果它们最终导致生产事故。
其次,现代应用程序和系统更加复杂,并且具有更多相互关联的部分。虽然传统测试擅长测试单个组件,但它不足以全面测试整个系统。提高可靠性意味着测试和加强这些复杂的相互作用,以防止一个组件的故障导致整个系统瘫痪。
最后,组织倾向于优先考虑其他计划而不是可靠性,例如缩短开发周期和快速发布新功能。这并不是因为可靠性不重要,而是因为它不是许多团队的首要任务。如果没有来自组织的强烈激励,提高可靠性的努力和举措就不太可能保持势头。更快的功能开发甚至可以通过使系统更不可靠来阻碍可靠性工作。
是什么推动了可靠性文化?
可靠性文化最终集中在一个目标上:提供最佳的客户体验。这种对客户的独特关注指导可靠性的所有其他方面,从开发更具弹性的应用程序和系统,到培训 SRE 以更有效地响应事件。当客户满意度和可靠性之间存在明显的相关性时,组织就会更有动力投入所需的时间、精力和预算,以使系统和流程更加可靠。它还将可靠性工作与公司的核心使命直接联系起来,进一步巩固了它作为一项重要实践的地位。
[“为什么我们需要可靠”的答案]只有一个词:信任!信任是我们能提供的最重要的东西。为了使我们的平台可行,我们的客户必须相信我们将可用,为了让我们赢得客户的信任,我们必须可靠。
如何发展和培养可靠性文化
建立可靠性文化所需的时间和精力与组织的规模成正比。即使在个人习惯于快速转向的初创公司中,确保每个人都在同一个目标上保持一致也是一项挑战。在建立可靠性文化时,我们需要考虑我们的目标。
从你的使命宣言开始
提高可靠性的主要目标是保持我们的系统和服务可用。频繁的中断会导致收入损失、客户信任度下降,以及用于响应事件而不是改进我们的产品或服务的工程时间。但是,尽管这是所有组织的一个重要目标,但它并不总是组织文化的一个引人注目的驱动力。那是什么?
这个问题的答案应该与组织的使命宣言密切相关。如果我们没有使命宣言或目标,我们应该从关注客户开始。我们如何提供最佳的客户体验,以及如何将其转化为我们组织的日常工作?
这个问题应该是整个组织的头等大事,尤其是在产品团队、工程团队、客户支持团队和执行团队中。每个团队都应该意识到他们的角色和职责如何为客户体验做出贡献。例如,如果工程师编写的代码优化不佳,这可能会导致性能下降和延迟增加,从而导致客户放弃产品。通过围绕客户构建可靠性,我们可以更轻松地开始思考不同团队如何影响可靠性目标。
为了让团队保持一致,我们应该经常重复我们的使命宣言。在会议、员工入职和规划新计划时突出显示它。如果对我们的可靠性目标或目标产生疑问,我们应该始终将它们与客户联系起来。
识别并响应回击
组织变革通常会遇到一些阻力。您可能会听到以下论点:可靠性测试太复杂,需要花费宝贵的时间进行功能开发,或者您已经忙于事件管理。虽然投资可靠性确实需要前期投资,但它带来的好处大大超过了成本。这些包括:
- 减少影响客户的事件和中断,从而带来更好的客户体验。
- 更少的待命事件和紧急页面,减轻工程师的压力。
- 降低了高严重性错误进入生产的风险,使工程师能够专注于功能开发和其他增值任务。
在开发生命周期的早期提高可靠性
团队通常直到软件开发生命周期 (SDLC) 后期才考虑可靠性。传统上,工程团队将可靠性测试的责任留给了 QA。随着现代应用程序的复杂性和快速发展,这个过程不再是可扩展的或完全有效的。它不仅会为生产设置障碍并减慢发布周期,而且无法找到现代系统中存在的意外且独特的故障模式。
解决方案是向左移动,以便在整个 SDLC 中进行可靠性测试,而不仅仅是在最后。在规划新功能或新服务时,我们早在需求收集阶段就开始规划我们想要提供的客户体验。产品经理在开发开始之前设定对服务质量的期望,SRE 和应用程序开发人员定义指标来衡量和跟踪对这些要求的合规性,然后我们不断测试我们在整个开发过程中满足这些要求的能力。
通过及早优先考虑可靠性,对提高可靠性的关注自然会影响到参与开发过程的每个团队。这使我们能够尽早开始发现和解决缺陷,鼓励良好的开发实践,并降低问题进入生产的风险。这也有经济利益,因为稍后在 SDLC 中修复错误的成本更高。
采用支持可靠性文化的实践
文化是重要的一步,但我们也需要工具来帮助我们将文化付诸实践。在可靠性方面,我们需要一种方法来确保我们的响应团队准备好处理事件,我们的系统对技术故障具有弹性,并且我们对可靠性实践的关注能够为业务带来明确的投资回报 (ROI)。我们这样做的方式是使用混沌工程。
混沌工程是故意将故障注入系统,观察系统如何响应,使用这些观察来提高其可靠性,并验证我们的弹性机制是否有效的实践。虽然“系统”通常指的是技术系统(尤其是分布式系统),但我们也可以使用混沌工程来验证组织系统和流程。这包括事件管理和响应、灾难恢复和故障排除流程。
Chaos Engineering 可帮助团队主动测试可靠性威胁,并在开发过程的早期解决它们,从而降低事件或中断的风险。这包括测试事件响应计划、验证系统是否可以故障转移到冗余或备份系统,以及许多其他场景。
使用 GameDays 和 FireDrills 练习失败
采用可靠性文化的最大挑战之一是保持这种做法。可靠性不是一次就能实现的:它必须定期维护和验证。做到这一点的最佳方法是使用混沌工程定期主动地测试系统和流程。事实上,持续运行混沌实验的团队比从未进行过实验或运行临时实验的团队具有更高的可用性水平。
混沌工程如何帮助建立可靠性文化?答案是帮助团队测试他们对系统的假设,积极寻找提高可靠性的方法,并确保系统能够适应生产条件。这样做的一个常见策略是使用 GameDays,这是故意计划的事件,拥有应用程序或服务的工程师团队(以及其他利益相关者,如团队领导和产品经理)聚在一起对服务进行混沌实验.团队运行实验,观察服务以了解它如何响应,并利用他们的见解来提高服务的弹性。然后,他们将实验自动化,将其添加到他们的实验库中,然后连续运行这些实验以验证他们的系统是否保持弹性。
一个典型的 GameDay 运行时间为 2-4 小时,涉及以下团队成员:
- 一位领导 GameDay 并决定何时运行或中止实验的成员(“所有者”)。
- 执行实验的一名成员(“协调员”)。
- 一名计划实验、定义假设(实验旨在测试什么)并记录结果的成员(“报告者”)。
- 收集数据(通常来自监控或可观察性工具)并将实验效果与其数据相关联的一名或多名成员(“观察员”)。
为了帮助建立可靠性实践,请定期运行 GameDays。具有高可用性的团队倾向于每周、每月或每季度运行一次实验。一般来说,运行更频繁的 GameDays 可以帮助您更快地实现可靠性目标,因此请考虑安排每周或每两周的 GameDays。
一旦您的团队能够轻松运行计划内的事件,请考虑添加计划外事件。这些被称为 FireDrills。与 GameDay 一样,FireDrill 涉及使用混沌工程来模拟系统上的故障。不同之处在于响应 FireDrill 的团队不知道这是一次演习。这使他们以更现实的方式做出反应,就好像这是一个真实的事件,但保留了在必要时停止和回滚事件的能力。
FireDrills 可以有效地帮助团队:
- 测量响应时间和平均解决时间 (MTTR)。
- 确保运行手册是最新的。
- 练习事件响应程序并建立肌肉记忆。
- 测试监控仪表板、警报和待命/寻呼系统。
我们建议每周或每两周运行一次 FireDrills,但前提是您的团队已经练习过运行 GameDays。指定能够协调 FireDrill 的领导者,最好是了解被攻击系统的工程团队领导者。这可确保在发生意外情况或需要取消 FireDrill 时始终有人能够快速响应。
从错误中学习
事件会发生,这很好。没有一个系统是完美的。当出现问题时,采取纠正措施并尽快解决根本原因。然后,一旦您的系统正常运行,请对您的响应进行深入调查和评估(称为事后分析)。调查问题的原因、团队为解决问题所采取的步骤、有助于解决问题的指标和其他可观察性数据,以及团队为防止问题再次发生而采取的措施。
失败没关系:混乱即将发生,我们应该寻找失败只是为了学习。那些不舒服的地方是我们学到最多的地方。
事故对工程师来说是一段情绪紧张的时期,尤其是当他们觉得自己是造成事故的人时。进行事后分析时,不要专注于指责。相反,应首先关注使事件发生的过程。这被称为无可指责的事后分析。例如,如果团队成员将不良代码推到生产环境中,那么解决方案可能是更可控的部署管道、更彻底的自动化测试或更严格的同行评审。 “互相指责”只会阻止工程师分享他们的经验和见解,因为他们害怕受到惩罚或报复。
事件是学习和成长的机会。当您解决事件的根本原因时,请使用混沌工程来验证您的修复是否有效。自动化此过程以确保您的系统对故障保持弹性。不仅要在您自己的中断中练习,还要从其他团队和组织经历和记录的事件中练习。
总结一下……
- 可靠性文化是组织的每个成员都在朝着提高组织可靠性的共同目标而努力的文化。
- 可靠性始于客户。如果没有明确的、以客户为中心的使命宣言,可靠性计划就不太可能成功。
- 构建可靠系统的责任由所有团队共同承担,而不仅仅是工程或 QA。
- 文化确保可靠性不仅仅是一次性的举措,而是一个持续的过程和组织的一个组成部分。
- GameDay 是留给团队运行一个或多个混沌实验并专注于技术成果的一段时间。
- FireDrill 是一种训练团队的做法,让他们对故意制造的事件做出反应。
- 通过采用工具来实践可靠性(例如混沌工程工具)并将它们集成到您的日常工作流程中,培养一种可靠性文化。
- 始终愿意从您和其他人的事件中学习。
Additional resources
- Twilio 如何建立可靠性文化
- 让开发者成为开发者:抽象合规性 + 可靠性以加速 JPMC 的云部署
- 在Charter Communications 扩大企业弹性文化
- 创造混沌文化:混沌工程不仅仅是工具,更是文化
- 如何建立高严重性事件管理程序
- 使用我们的 Confluence 模板为您的组织轻松创建混沌工程 wiki
- 43 次浏览
【可靠性工程】GCP 可靠性核心原则
Google Cloud Architecture Framework 中的这份文档解释了在云平台上运行可靠服务的一些核心原则。这些原则有助于您在阅读架构框架的其他部分时达成共识,这些部分向您展示了一些 Google Cloud 产品和功能如何支持可靠的服务。
关键术语
在架构框架可靠性类别中,使用了以下术语。这些术语提供了对如何运行可靠服务的关键理解。
服务水平指示器 (SLI)
服务水平指标 (SLI) 是对正在提供的服务水平的某些方面进行仔细定义的定量测量。它是一个指标,而不是一个目标。
服务水平目标 (SLO)
服务级别目标 (SLO) 指定服务可靠性的目标级别。 SLO 是 SLI 的目标值。当 SLI 等于或优于该值时,该服务被认为是“足够可靠”。由于 SLO 是制定有关可靠性的数据驱动决策的关键,因此它们是站点可靠性工程 (SRE) 实践的焦点。
错误预算
错误预算计算为 100% – SLO 在一段时间内。错误预算会告诉您,您的系统在特定时间窗口内是否比所需的可靠性更高或更低,以及在此期间允许停机多少分钟。
例如,如果您的可用性 SLO 为 99.9%,则 30 天期间的错误预算为 (1 - 0.999) ✕ 30 天 ✕ 24 小时 ✕ 60 分钟 = 43.2 分钟。每当系统不可用时,系统的错误预算就会被消耗或烧毁。使用前面的示例,如果系统在过去 30 天内有 10 分钟的停机时间,并且在 43.2 分钟的全部预算未使用的情况下开始了 30 天的周期,则剩余的错误预算将减少到 33.2 分钟。
我们建议在计算总错误预算和错误预算消耗率时使用 30 天的滚动窗口。
服务水平协议 (SLA)
服务水平协议 (SLA) 是与您的用户签订的明示或隐含合同,其中包括您遇到或错过合同中引用的 SLO 时的后果。
核心原则
Google 的可靠性方法基于以下核心原则。
可靠性是您的首要功能
新产品功能有时是您短期内的首要任务。但是,从长远来看,可靠性是您的首要产品功能,因为如果产品速度太慢或长时间不可用,您的用户可能会离开,从而使其他产品功能变得无关紧要。
可靠性由用户定义
对于面向用户的工作负载,衡量用户体验。用户必须对您的服务执行方式感到满意。例如,衡量用户请求的成功率,而不仅仅是 CPU 使用率等服务器指标。
对于批处理和流式工作负载,您可能需要衡量数据吞吐量的关键性能指标 (KPI),例如每个时间窗口扫描的行数,而不是服务器指标,例如磁盘使用情况。吞吐量 KPI 有助于确保按时完成用户所需的每日或季度报告。
100% 的可靠性是错误的目标
你的系统应该足够可靠,让用户满意,但又不能过于可靠,以至于投资不合理。定义设置所需可靠性阈值的 SLO,然后使用错误预算来管理适当的变化率。
仅当该产品或应用程序的 SLO 证明成本合理时,才将该框架中的设计和操作原则应用于产品。
可靠性与快速创新相辅相成
使用错误预算在系统稳定性和开发人员敏捷性之间取得平衡。以下指南可帮助您确定何时快速或慢速移动:
- 当有足够的错误预算可用时,您可以快速创新并改进产品或添加产品功能。
- 当错误预算减少时,放慢速度并专注于可靠性功能。
设计和操作原则
为了最大限度地提高系统可靠性,以下设计和操作原则适用。在架构框架可靠性类别的其余部分中详细讨论了这些原则中的每一个。
定义您的可靠性目标
架构框架的这一部分涵盖的最佳实践包括以下内容:
- 选择适当的 SLI。
- 根据用户体验设置 SLO。
- 迭代改进 SLO。
- 使用严格的内部 SLO。
- 使用错误预算来管理开发速度。
有关详细信息,请参阅在架构框架可靠性类别中定义您的可靠性目标。
在您的基础架构和应用程序中构建可观察性
架构框架的这一部分涵盖了以下设计原则:
- 检测您的代码以最大限度地提高可观察性。
有关更多信息,请参阅架构框架可靠性类别中的在基础架构和应用程序中构建可观察性。
为规模和高可用性而设计
架构框架的这一部分涵盖了以下设计原则:
- 创建冗余以提高可用性。
- 跨区域复制数据以进行灾难恢复。
- 设计多区域架构以应对区域中断。
- 消除可扩展性瓶颈。
- 过载时优雅地降低服务级别。
- 防止和缓解流量高峰。
- 清理和验证输入。
- 以保留系统功能的方式进行故障保护。
- 将 API 调用和操作命令设计为可重试。
- 识别和管理系统依赖项。
- 最小化关键依赖。
- 确保每次更改都可以回滚。
有关详细信息,请参阅架构框架可靠性类别中的规模和高可用性设计。
创建可靠的操作流程和工具
架构框架的这一部分涵盖了以下操作原则:
- 为应用程序和服务选择好的名称。
- 通过金丝雀测试程序实施渐进式部署。
- 分散流量以进行定时促销和发布。
- 自动化构建、测试和部署过程。
- 防止操作员错误。
- 测试故障恢复程序。
- 进行灾难恢复测试。
- 练习混沌工程。
有关详细信息,请参阅架构框架可靠性类别中的创建可靠的操作流程和工具。
建立有效的警报
架构框架的这一部分涵盖了以下操作原则:
- 优化警报延迟。
- 警惕症状,而不是原因。
- 警惕异常值,而不是平均值。
有关详细信息,请参阅架构框架可靠性类别中的构建高效警报。
建立协作事件管理流程
架构框架的这一部分涵盖了以下操作原则:
- 分配明确的服务所有权。
- 通过精心调整的警报缩短检测时间 (TTD)。
- 通过事件管理计划和培训缩短缓解时间 (TTM)。
- 设计仪表板布局和内容以最小化 TTM。
- 记录已知中断情况的诊断程序和缓解措施。
- 使用无可指责的事后分析从中断中学习并防止再次发生。
有关详细信息,请参阅架构框架可靠性类别中的构建协作事件管理流程。
原文:https://cloud.google.com/architecture/framework/reliability/principles
- 47 次浏览
【可靠性工程】GCP 定义您的可靠性目标
Google Cloud 架构框架中的这份文档提供了最佳做法,用于定义适当的方法来衡量您的服务的客户体验,以便您可以运行可靠的服务。您将了解如何迭代您定义的服务级别目标 (SLO),并使用错误预算来了解如果发布其他更新,可靠性可能会受到影响。
选择合适的 SLI
选择适当的服务水平指标 (SLI) 以充分了解您的服务执行情况非常重要。例如,如果您的应用程序具有多租户架构,这是由多个独立客户使用的典型 SaaS 应用程序,请在每个租户级别捕获 SLI。如果您的 SLI 仅在全局聚合级别进行测量,您可能会错过应用程序中影响单个重要客户或少数客户的关键问题。相反,将您的应用程序设计为在每个用户请求中包含一个租户标识符,然后将该标识符传播到堆栈的每一层。此标识符允许您的监控系统在请求路径上的每一层或微服务的每个租户级别汇总统计信息。
您运行的服务类型还决定了要监控的 SLI,如以下示例所示。
服务系统
以下 SLI 在提供数据的系统中是典型的:
- 可用性告诉您服务可用的时间比例。它通常根据格式良好的请求成功的比例来定义,例如 99%。
- 延迟告诉您可以以多快的速度满足一定百分比的请求。它通常以第 50 位以外的百分位来定义,例如“300 毫秒时的第 99 个百分位”。
- 质量告诉你某个反应有多好。质量的定义通常是特定于服务的,并表示对请求的响应内容与理想响应内容的差异程度。响应质量可以是二元的(好或坏)或以 0% 到 100% 的范围表示。
数据处理系统
以下 SLI 在处理数据的系统中是典型的:
- 覆盖率告诉您已处理的数据比例,例如 99.9%。
- 正确性告诉您被认为正确的输出数据的比例,例如 99.99%。
- 新鲜度告诉您源数据或聚合输出数据的新鲜程度。通常,更新越近越好,例如 20 分钟。
- 吞吐量告诉您正在处理多少数据,例如 500 MiB/秒甚至每秒 1000 个请求 (RPS)。
存储系统
以下 SLI 在存储数据的系统中是典型的:
- 持久性告诉您写入系统的数据在未来被检索到的可能性有多大,例如 99.9999%。任何永久性数据丢失事件都会降低持久性指标。
- 吞吐量和延迟也是存储系统的常见 SLI。
根据用户体验选择 SLI 并设置 SLO
本架构框架部分的核心原则之一是可靠性由用户定义。尽可能靠近用户测量可靠性指标,例如以下选项:
- 如果可能,请检测移动或 Web 客户端。
- 例如,使用 Firebase 性能监控来深入了解您的 iOS、Android 和 Web 应用程序的性能特征。
- 如果这不可能,请检测负载平衡器。
- 例如,将 Cloud Monitoring 用于外部 HTTP(S) 负载平衡器日志记录和监控。
- 衡量服务器的可靠性应该是最后的选择。
- 例如,使用 Stackdriver Monitoring 监控 Compute Engine 实例。
将您的 SLO 设置得足够高,以使几乎所有用户都对您的服务感到满意,而不是更高。由于网络连接或其他短暂的客户端问题,您的客户可能不会注意到应用程序中的短暂可靠性问题,从而允许您降低 SLO。
对于正常运行时间和其他重要指标,目标是低于 100% 但接近它。服务所有者应客观地评估使大多数用户满意的最低服务性能和可用性水平,而不仅仅是根据外部合同水平设定目标。
您更改的速率会影响系统的可靠性。但是,频繁进行小幅更改的能力可以帮助您更快、更优质地交付功能。根据客户体验调整的可实现的可靠性目标有助于定义客户可以容忍的最大变化速度和范围(功能速度)。
如果您无法衡量客户体验并围绕它定义目标,您可以运行竞争基准分析。如果没有可比的竞争,衡量客户体验,即使你还不能定义目标。例如,衡量系统可用性或对客户进行有意义且成功的交易的比率。您可以将此数据与业务指标或 KPI 相关联,例如零售订单量或客户支持电话和工单的数量及其严重性。在一段时间内,您可以使用此类关联练习来达到合理的客户满意度阈值。此阈值是您的 SLO。
有关如何选择正确的 SLI 和定义 SLO 的更多信息,请参阅定义 SLO。
迭代改进 SLO
SLO 不应一成不变。每季度或至少每年重新访问 SLO,并确认它们继续准确反映用户的幸福感并与服务中断密切相关。确保它们涵盖当前的业务需求和新的关键用户旅程。在这些定期审查之后,根据需要修改和增加您的 SLO。
使用严格的内部 SLO
拥有比外部 SLA 更严格的内部 SLO 是一种很好的做法。由于违反 SLA 往往需要签发财务信用或客户退款,因此您希望在问题产生财务影响之前解决问题。
我们建议您将这些更严格的内部 SLO 与无可指责的事后分析流程和事件审查一起使用。有关更多信息,请参阅架构中心可靠性类别中的构建协作事件管理流程。
使用错误预算来管理开发速度
错误预算会告诉您您的系统在某个时间窗口内是否比所需的可靠性更高或更低。错误预算按 100% 计算——一段时间内的 SLO,例如 30 天。
当您的错误预算中有剩余容量时,您可以继续快速启动改进或新功能。当错误预算接近于零时,冻结或减慢服务更改并投入工程资源以提高可靠性功能。
Google Cloud 的运营套件包括 SLO 监控,以最大程度地减少设置 SLO 和错误预算的工作量。操作套件包括一个图形用户界面,可帮助您手动配置 SLO,一个用于编程设置 SLO 的 API,以及用于跟踪错误预算消耗率的内置仪表板。有关详细信息,请参阅如何创建 SLO。
建议
要将架构框架中的指南应用到您自己的环境中,请遵循以下建议:
- 定义和衡量以客户为中心的 SLI,例如服务的可用性或延迟。
- 定义比外部 SLA 更严格的以客户为中心的错误预算。包括违规后果,例如生产冻结。
- 设置延迟 SLI 以捕获异常值,例如第 90 或第 99 个百分位数,以检测最慢的响应。
- 至少每年检查一次 SLO,并确认它们与用户满意度和服务中断密切相关。
原文:https://cloud.google.com/architecture/framework/reliability/define-goals
- 88 次浏览
【可靠性工程】Microsoft 可靠性模式
可用性
可用性以正常运行时间的百分比来衡量,并定义了系统正常运行和工作的时间比例。 可用性受系统错误、基础设施问题、恶意攻击和系统负载的影响。 云应用程序通常为用户提供服务水平协议 (SLA),这意味着必须设计和实施应用程序以最大限度地提高可用性。
| Pattern | Summary |
|---|---|
| Deployment Stamps | 部署应用程序组件的多个独立副本,包括数据存储 |
| Geodes | 将后端服务部署到一组地理节点中,每个节点都可以为任何区域的任何客户端请求提供服务。 |
| Health Endpoint Monitoring | 在外部工具可以通过暴露的端点定期访问的应用程序中实施功能检查。 |
| Queue-Based Load Leveling | 使用队列作为任务和它调用的服务之间的缓冲区,以平滑间歇性重负载。 |
| Throttling | 控制应用程序实例、单个租户或整个服务对资源的消耗。 |
为了缓解来自恶意分布式拒绝服务 (DDoS) 攻击的可用性风险,请实施本机 Azure DDoS 保护标准服务或第三方功能。
高可用性
Azure 基础架构由地理、区域和可用区组成,它们限制了故障的爆炸半径,从而限制了对客户应用程序和数据的潜在影响。 Azure 可用区构造旨在提供软件和网络解决方案,以防止数据中心故障并为我们的客户提供更高的高可用性 (HA)。 借助 HA 架构,可以在高弹性、低延迟和成本之间取得平衡。
| Pattern | Summary |
|---|---|
| Deployment Stamps | 部署应用程序组件的多个独立副本,包括数据存储。 |
| Geodes | 将后端服务部署到一组地理节点中,每个节点都可以为任何区域的任何客户端请求提供服务。 |
| Health Endpoint Monitoring | 在外部工具可以通过暴露的端点定期访问的应用程序中实施功能检查。 |
| Bulkhead | 将应用程序的元素隔离到池中,以便如果一个失败,其他元素将继续运行。 |
| Circuit Breaker | 处理连接到远程服务或资源时可能需要不同时间才能修复的故障。 |
弹性
弹性是系统从疏忽和恶意故障中优雅地处理和恢复的能力。
云托管的性质,其中应用程序通常是多租户的、使用共享平台服务、竞争资源和带宽、通过 Internet 通信以及在商品硬件上运行,这意味着出现瞬时和更永久故障的可能性增加 . 互联网的连接性以及攻击的复杂性和数量的增加增加了安全中断的可能性。
检测故障并快速有效地恢复是保持弹性的必要条件。
| Pattern | Summary |
|---|---|
| Bulkhead | 将应用程序的元素隔离到池中,以便在其中一个失败时,其他元素将继续运行。 |
| Circuit Breaker | 处理连接到远程服务或资源时可能需要花费可变时间来修复的故障。 |
| Compensating Transaction | 撤消由一系列步骤执行的工作,这些步骤共同定义了最终一致的操作。 |
| Health Endpoint Monitoring | 在外部工具可以定期通过公开端点访问的应用程序中实现功能检查。 |
| Leader Election | 通过选择一个实例作为负责管理其他实例的负责人,协调分布式应用程序中协作任务实例集合执行的操作。 |
| Queue-Based Load Leveling | 使用队列作为任务和它调用的服务之间的缓冲区,以平滑间歇性重载。 |
| Retry | 通过透明地重试以前失败的操作,使应用程序在尝试连接到服务或网络资源时能够处理预期的临时故障。 |
| Scheduler Agent Supervisor | 跨一组分布式服务和其他远程资源协调一组操作。 |
- 28 次浏览
【可靠性架构】可靠性架构第1部分:概念
可靠性
本故事的目标是提供可靠性的最佳实践来管理您的云环境。尽管它引用了AWS和Cloud,但这些原则同样适用于其他云提供商和内部环境。
本故事将分为三个部分。
- 第1部分-描述各种术语和最佳实践的概念
- 第2部分-云的弹性和可用性设计模式
- 第3部分—实现特定SLA的高可用性体系结构
本故事集中在第1部分
AWS于2015年发布了良好架构框架,并描述了良好架构原则的五大支柱,即
- 可靠性
- 安全
- 性能效率
- 成本优化
- 卓越运营
本故事侧重于可靠性支柱,提供了可靠性的要点,以供快速参考,并基于AWS白皮书和Microsoft云设计模式。
可靠性集中在以下方面
- 能够从基础设施/服务故障中恢复
- 快速获取需求资源以满足需求的能力
- 缓解配置和瞬态网络问题
可用性
可用性=正常运行时间/总时间,表示为正常运行时间的百分比,例如99.99%。简而言之,以9的数量表示,例如99.999表示为五个9
作为快速参考,99%的可用性意味着每年3天15小时的停机时间,99.999%意味着每年5分钟的停机时间。要计算特定值,请使用链接https://uptime.is/99.9或结账https://en.wikipedia.org/wiki/High_availability
如果存在相关性,则可用性是系统可用性和从属系统可用性的乘积。例如,如果系统A具有99.9%,系统B具有99.9%,并且A依赖于B,则聚合系统的可用性为99.9*99.9=99.8%
如果系统存在冗余,则正常运行时间计算为100减去组件故障率的乘积。例如,如果可用性为99.9,则故障率为0.1%,由此产生的可用性为100减去(0.1*0.1)=999.99%,这表明由于冗余而增加了可用性。
有时可能不知道依赖项的可用性。如果我们知道平均故障间隔时间(MTBF)和平均恢复时间(MTTR),那么可用性=MTBF/(MTBF+MTTR)。例如,MTBF为150天,MTTR为1小时,则可用性为99.97%。使用链接对此进行更深入的了解。
实现最高级别的可用性意味着部署/容量添加/回滚等方面的系统成本和复杂性更高。即使没有使用所有功能,也通常会为已建立的系统支付更高可用性的费用。必须考虑成本,小心制定正确的可用性目标。
弹性网络设计-关键指南
- 在设计VPC和子网CIDR块时,考虑到所有对等可能性、本地重叠、Lambdas/ELB所需的IP数量等,考虑到未来的情况。
- 为VPN连接和直连使用冗余
- 利用AWS Shield、WAF、Route 53等AWS服务防止DDoS攻击
高可用性应用程序设计
为“五个9”或更高的HA进行设计需要极端的考虑。许多服务提供商和软件库的设计并不是为了提供这样的数量,这需要添加多个服务提供商,避免单点故障和定制开发,以及操作的极端自动化和彻底的故障测试。
应用程序必须处理的一些中断类型如下
- 硬件故障
- 部署失败
- 增加的负载
- 意外的输入错误
- 凭据/证书过期
- 依赖项失败
- 电力等基础设施故障
所有这些故障都必须得到处理,恢复必须自动化。这意味着实现HA的工作不是微不足道的,并导致了可用性目标需求的细化。这可能是因为某些交易必须比其他交易更可靠,高峰时间、地理差异等。。
了解可用性需求
整个系统不需要设计为高可用性。例如,实时操作可能比批处理更重要,非高峰时间可能对可用性有容忍度,数据平面与控制平面,例如,现有EC2的健康状况和操作可能比能够启动新实例更重要,等等。
应用程序可用性设计
通过利用经验证的实践,可以显著提高应用程序可用性。以下原则指导HA的应用程序设计
- 故障隔离区:通过利用AWS可用区和区域,可以将影响降低到特定区域。跨区域利用复制技术可降低数据丢失的风险
- 冗余:避免单点故障是关键。构建对单个断层带故障具有弹性的软件非常重要
- MicroServices:通过使用MicroServices架构构建,我们可以区分不同组件之间的可用性需求。架构中存在权衡,请查看https://martinfowler.com/articles/microservice-trade-offs.html
- 面向恢复的计算:减少恢复影响时间至关重要。恢复程序基于影响而不是发生的问题类型。在某些情况下,如EC2,终止它并让ASG生成一个新实例可能比试图确定确切的问题并修复要好。定期测试恢复路径对于始终评估程序的有效性至关重要
- 分布式系统最佳实践:分布式系统的一些最佳实践包括:节流(速率限制)、在返回故障之前重试一定次数、在特定条件下快速失败、确保处理一次的Idemptency令牌、保持服务始终以恒定工作预热、检查依赖性可用性的断路器、,静态稳定性,以确保系统在故障期间工作更少,而不是使系统进一步过载
可用性的操作注意事项
规划应用程序整个生命周期中使用的自动化或人工工作流非常重要。测试是输送管道的重要组成部分。除了单元和功能测试外,性能测试、持续负载测试和故障注入测试也很重要。操作准备审查,必须评估测试、监控的完整性,并能够根据SLA审计应用程序性能
自动化部署
使用高级部署技术,如
- 金丝雀:通过监控影响,逐步引入更改并向前和向后移动
- 蓝-绿:立即建立一个并行的新堆栈和交换流量(并根据需要快速回滚)
- 功能切换-使用配置选项通过根据需要打开/关闭来部署新功能
- 故障隔离区部署:使用故障隔离区隔离部署并围绕区域故障规划容量
测试
测试必须符合可用性目标。单元测试、负载测试、性能测试、故障测试和外部依赖性测试是必要的。
监控和警报
监控需要有效检测故障并发出警报。您最不希望的是客户在您之前知道问题。监控和警报系统应与主要服务分离,服务中断不应影响监控和警报。
监测分为五个阶段
产生
确定需要监控的服务、定义度量、创建阈值和相应警报。几乎所有AWS服务都提供大量监控和日志信息供用户使用。例如Amazon ECS和AWS Lambda流日志到CloudWatch日志,VPC流日志可以在VPC中的任何或所有ENI上启用
聚合
Amazon CloudWatch和S3是主要的聚合层。一些服务(如ASG和ELB)提供开箱即用的度量,其他流服务(如VPC流日志/CloudTrail事件数据)被转发到CloudWatch日志,这些日志可以被过滤以提取度量。这可以提供触发警报的时间序列数据。
实时处理和报警
警报可以与多个用户的SNS集成,或发送到SQS进行第三方集成,或使用AWS Lambda立即采取行动。
存储和分析
CloudWatch日志可以将日志发送到AmazonS3,EMR可以用于进一步了解数据。Splunk/Logstash等第三方工具可用于聚合/处理/存储和分析。数据保留要求是关键,旧数据可以移动到AmazonGlacier进行长期存档。
作战准备审查(ORR)
ORR对于确保应用程序可用于生产非常重要。团队需要有一份初始ORR检查表,必须重复以验证准确性。一个团队的ORR必须结合从其他应用中吸取的经验教训。
审计
审核监控方面以验证可用性目标至关重要。根本原因分析需要发现发生了什么。AWS提供以下服务以跟踪事件期间的服务状态
- CloudWatch日志:存储日志并检查
- AWS配置:随时查找基础设施的状态
- AWS CloudTrail:查找由谁调用了哪些AWS API
请继续关注第2部分—高可用性体系结构,以实现特定的SLA
工具书类
- 54 次浏览
【可靠性架构】可靠性架构第2部分:云的弹性和可用性设计模式
提到https://en.wikipedia.org/wiki/Software_design_pattern详细概述了什么是设计模式,并参考了几种软件设计模式。本故事旨在回顾与云环境中的弹性和可用性相关的一些流行设计模式。
本故事的参考来自以下链接,所有图片均由各自的内容所有者提供。
- https://docs.microsoft.com/en-us/azure/architecture/patterns/
- http://en.clouddesignpattern.org/index.php/Main_Page
可用性模式
可用性表示系统运行和工作的时间。它可能会受到系统维护、软件更新、基础架构问题、恶意攻击、系统负载和与第三方提供商的依赖关系的影响。可用性通常通过SLA和9来衡量。例如,“五个9”意味着99.999%的可用性,这意味着系统在一年内可以停机约5分钟。检查https://uptime.is/查找特定SLA的可用性
运行状况终结点监视
在云中,应用程序可能会受到几个因素的影响,如延迟、提供商问题、攻击者和应用程序问题。有必要定期监视应用程序是否正常工作。
解决方案大纲
- 创建运行状况检查终结点
- 端点必须进行有用的健康检查,包括存储、数据库和第三方依赖关系等子系统
- 使用状态代码内容返回应用程序可用性
- 以适当的时间间隔监控终点,以及距离客户较近的地点的延迟
- 保护端点以防止攻击
有关完整概述,请参阅Microsoft链接
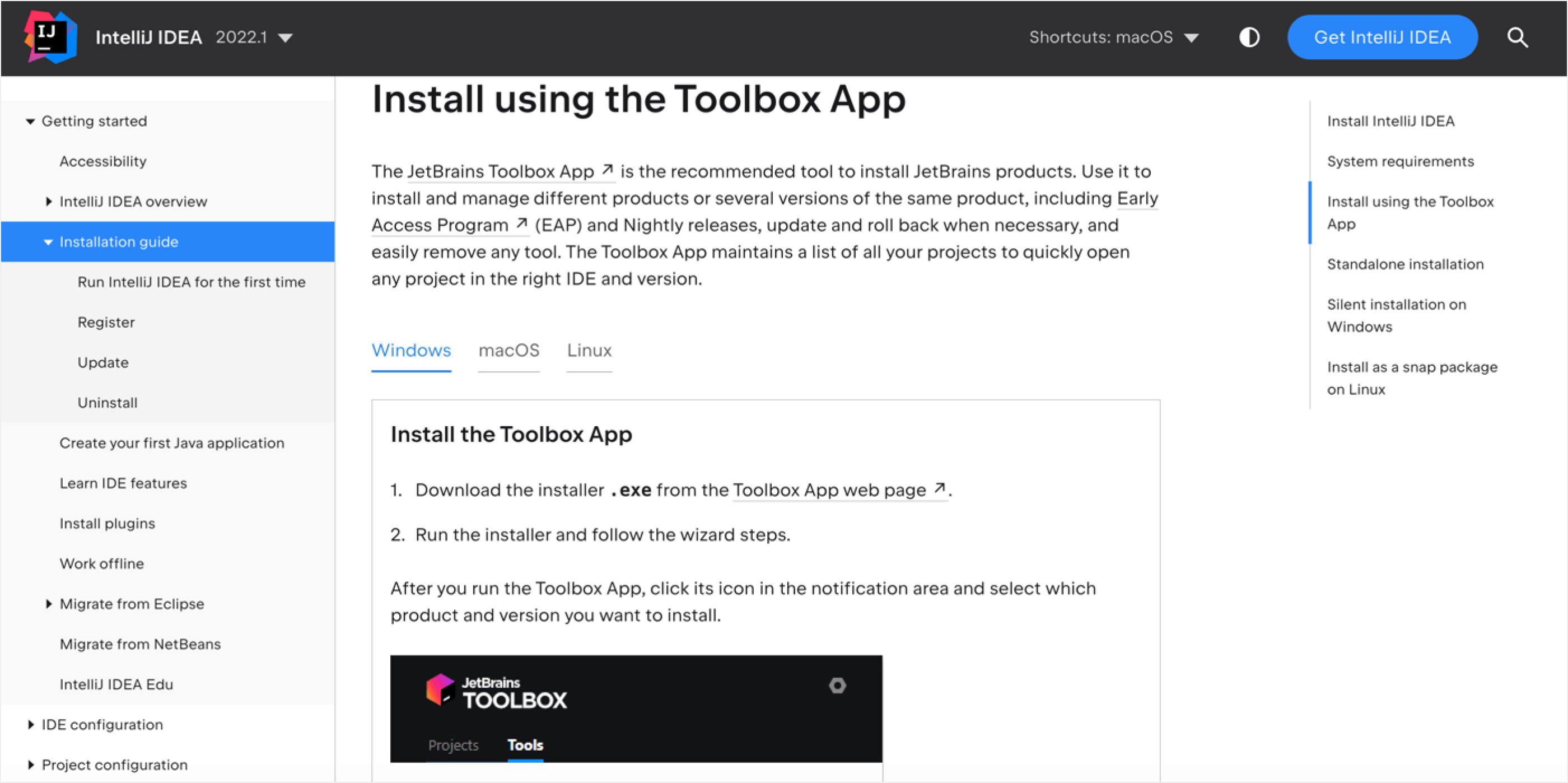
下图描述了AWS特定实现中的相同模式。这解释了健康检查应该有多深,而不是前面的静态页面。
有关详细信息,请参阅链接。
Other references
- http://microservices.io/patterns/observability/health-check-api.html
- https://docs.aws.amazon.com/elasticloadbalancing/latest/application/target-group-health-checks.html
- https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/health-checks-creating.html
基于队列的负载调配
重载/频繁请求可能会使服务过载,从而影响可用性。通过对此类请求进行排队并异步处理,将有助于提高系统的稳定性。

解决方案大纲
- 在任务和服务之间引入队列
- 任务放置在队列中
- 服务以所需的速度处理任务。在一些高级实现中,服务可能会根据队列大小自动缩放。
- 如果需要响应,服务必须提供适当的实现,但是,这种模式不适合低延迟响应需求
有关完整概述,请参阅链接
其他参考资料
- https://msdn.microsoft.com/library/dn589781.aspx
- http://soapatterns.org/design_patterns/asynchronous_queuing
节流
限制服务或其组件或客户端使用的资源数量,以便即使在极端负载期间,服务也能继续运行,满足SLA要求
解决方案大纲
- 设置单个用户访问的限制,监控指标并在超过限制时拒绝
- 禁用或降级不重要的服务,以便关键服务能够正常工作,例如,视频通话只能在带宽问题期间切换到音频
- 确定某些用户的优先级,并使用负载均衡来满足高影响客户的需求
有关完整概述,请查看链接
其他参考资料
弹性模式
弹性是系统从故障中优雅地恢复的能力。检测故障并快速高效地恢复是关键。
隔板(Bulk Head)
隔离应用程序组件,使其中一个组件的故障不会影响其他组件。隔板表示船舶的分段隔板。如果一个隔板受损,水只会在该隔板中,从而避免船舶沉没
解决方案大纲
- 将服务实例划分为多个组并单独分配资源,以便故障不会消耗此池之外的资源
- 根据业务和技术需求定义分区,例如,高优先级客户可能获得更多资源
- 利用Polly/Histrix等框架,并使用Containers等技术提供隔离。例如,容器可以为CPU/内存消耗设置硬限制,以便容器的故障不会耗尽资源。
有关完整概述,请参阅链接
其他资源
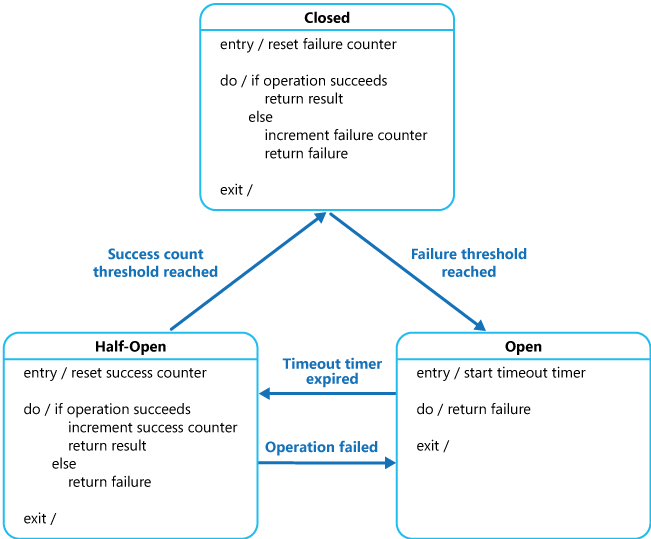
断路器
当一个服务被认为已经失败,并且如果它继续运行可能会对其他应用程序产生负面影响时,它应该抛出异常,并且可以稍后在问题似乎已修复时恢复,可以恢复该服务
解决方案大纲
下图显示了使用状态机实现断路器
有关完整概述,请查看链接
其他参考文献
- http://microservices.io/patterns/reliability/circuit-breaker.html
- https://spring.io/guides/gs/circuit-breaker/
补偿事务处理
在分布式系统中,强一致性并不总是最佳的。最终的一致性会产生更好的性能和组件集成。当发生故障时,必须撤消前面的步骤。
解决方案大纲
- 补偿事务将记录工作流的所有步骤,并在出现故障时开始撤消操作
下图描述了一个具有顺序步骤的示例用例。
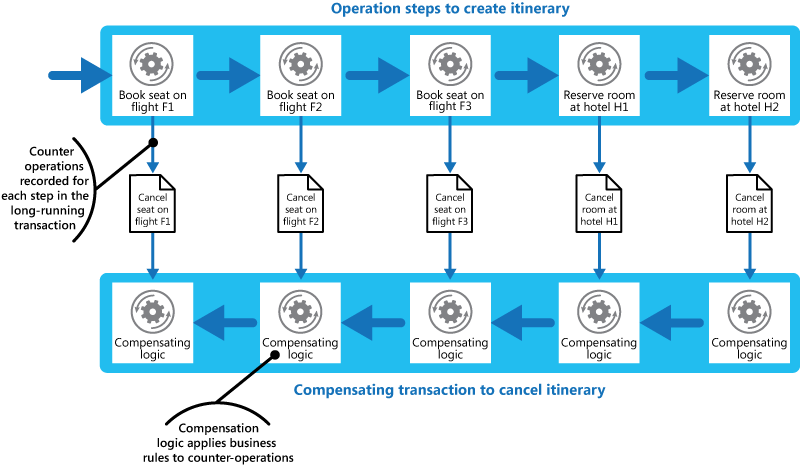
补偿事务不必撤消完全相同的顺序,可以执行并行调用。
有关详细概述,请查看链接
其他参考文献
领导人选举
协调多个类似实例执行的操作。例如,多个实例可能正在执行类似的任务,可能需要协调,也可能避免对共享资源的争用。在其他一些情况下,可能需要汇总几个类似实例的工作结果。
解决方案大纲
单个任务实例应被选为领导者。这将与其他从属实例协调操作。由于所有事例都是相似的,并且是同行的,因此必须有一个强有力的领导人选举过程
领导人选举过程可以使用以下几种策略
- 选择排名最低的实例或进程ID
- 获取Mutex-当领导者断开连接或失败时,应小心释放Mutex
- 实现常见的领导人选举算法,如Bully或Ring
此外,利用任何第三方解决方案,如Zookeeper,避免开发复杂的内部解决方案
有关详细概述,请查看链接
其他参考文献
重试
通过重试失败的操作来启用应用程序处理瞬时故障,以提高应用程序的稳定性
解决方案大纲
各种方法包括
- 如果故障被视为非瞬时故障且不太可能修复,则取消
- 如果故障看似异常,则立即重试,并且立即重试可能会成功
- 如果故障看起来是临时问题,并且可能在短时间间隔后修复,例如API速率限制问题,请在延迟后重试。
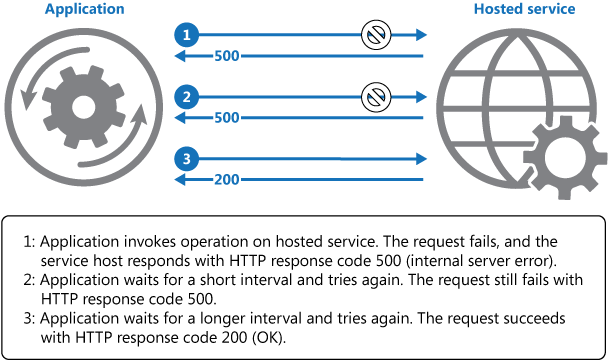
重试尝试应谨慎,不应使已加载的应用程序紧张。此外,请考虑要重试的操作的安全性(Idemptent)
有关完整参考,请查看链接
其他参考文献
调度程序代理主管
协调更大的操作。当事情失败时,尝试恢复,例如使用重试模式并成功,但如果系统无法恢复,则撤消工作,以使整个操作以一致的方式失败或成功。
解决方案大纲
解决方案涉及3个参与者
- 调度器-安排工作流中各个步骤的执行并协调操作。调度器还记录每个步骤的状态。调度器与代理通信以执行步骤。调度器/代理通信通常使用队列/消息传递平台异步进行
- 代理-通过一个步骤封装调用远程服务引用的逻辑。每个步骤可能使用不同的代理
- 主管-监视调度程序执行的任务中的每个步骤。在发生故障时,它请求由代理执行或由调度程序协调的适当恢复
下图显示了一个典型的实现
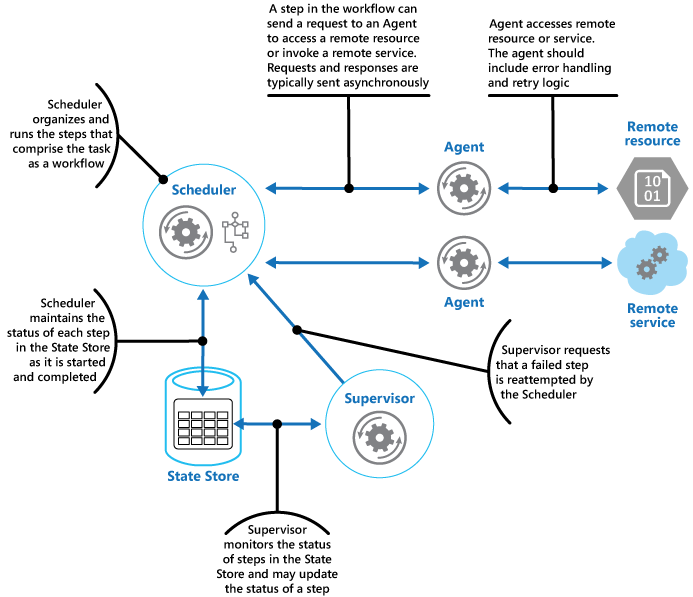
有关完整参考,请查看链接
其他参考文献
- Microsoft Azure Scheduler
- Process Manager pattern
- Cloud Architecture: The Scheduler-Agent-Supervisor Pattern
AWS特定模式
以下部分描述了一些显示特定AWS实现的模式。其中一些比较简单,但值得一看。
多服务器模式
在这种方法中,您可以在负载平衡器后面配置其他服务器,以提高数据中心/可用性区域内的可用性
您需要注意共享数据和粘性会话。利用其他数据访问模式解决此类问题
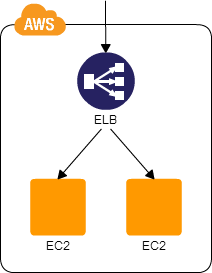
有关详细概述,请查看链接
多数据中心模式
这扩展了多服务器模式,通过在多个数据中心/可用性区域中创建服务器来解决数据中心故障
数据共享问题仍然如前一节所述。
有关完整概述,请查看链接
浮动IP模式
在这种情况下,应用程序会为服务器分配一个浮动IP,在发生故障时,该IP可以重新分配给另一个工作服务器。虽然这个想法是原始的,并且依赖于弹性IP特性,但是可以扩展该模式以实现高级架构。
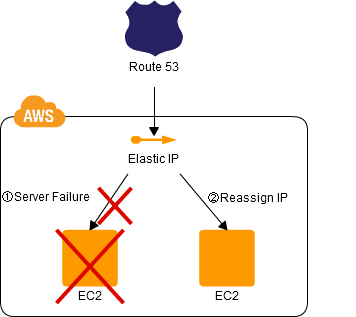
有关完整概述,请查看链接
- 44 次浏览
【可靠性架构】可靠性架构第3部分:高可用性体系结构
可用性目标场景
在本节中,我们将回顾一个示例应用程序,并阐述部署架构如何因不同的可用性目标而变化。示例应用程序是一个典型的web应用程序,它具有反向代理、S3中的静态内容、应用程序服务器和SQL数据库。无论我们在容器还是虚拟机中部署它们,可用性设计都保持不变。
服务选择
我们将使用EC2进行计算,使用Amazon RDS进行关系数据库,并利用Multi-AZ部署。将使用路由53进行DNS,使用ELB分配负载,使用S3进行备份和静态内容。
99%(2个9)方案
应用特点
- 根据可用性图表,这些应用程序每年的停机时间约为3天15小时。
- 这些应用程序通常对业务有帮助,如果不可用,可能会带来不便(不是关键任务)。
- 大多数内部系统都属于这一类别,并具有实验性的客户功能。
部署设计
- 单个区域
- 一个可用区域
- 单个实例
- 将备份数据发送到S3进行恢复,对对象启用版本控制,对备份禁用删除,存档/删除旧数据的生命周期策略
- Cloudformation将基础设施定义为一个代码,并将用于在出现故障时加快整个基础设施的重建。
- 故障期间,使用DNS更改,将流量路由到静态网站
- 部署管道计划有基本单元/黑盒/白盒测试
- 软件更新是手动的,需要停机
- 监控查找主页的200 OK状态
可用性计算
在这种设计中,每次故障恢复大约需要70分钟。每次部署/软件更新需要4小时。估计大约有4次故障和6次其他更改,可用性达到99%。
99.9%(3个9)方案
应用特点
- 根据可用性图表,这些应用程序每年的停机时间约为8小时45分钟。
- 这些应用程序的高可用性很重要,但可以承受短暂的不可用时间。
- 例如,关键的内部应用程序和低收入的面向客户的应用程序。
部署设计
- 我们将利用利用多个可用区域的AWS服务。(ELB/ASG/RDS MultiAZ)
- 负载平衡器将配置应用程序健康检查,该检查实际上描述了每个实例中应用程序的健康状况
- ASG将替换运行状况检查失败的实例,RDS将故障转移到第二个AZ以处理主要AZ故障
- 应用程序将分为不同的层(反向代理/应用程序服务器),以提高可用性。应用程序恢复模式将确保在AZ故障切换期间短暂的数据库不可用不会影响应用程序可用性
- 使用就地方法自动更新软件,并在出现故障时记录回滚过程
- 每2-4周按固定计划交付软件
- 监控将检查主页上的200 OK状态、web服务器的更换、数据库故障切换和S3中的静态内容可用性
- 将汇总日志以进行根本原因分析
- 存在用于恢复和报告的Runbook
- 行动手册适用于常见的数据库相关问题、安全相关事件、失败部署以及根本原因分析。
可用性计算
假设2次故障需要人工干预,每次事故60分钟,则影响将为2小时。假设自动软件更新需要每次停机15分钟,并且需要10个这样的实例,我们将需要150分钟的停机时间。这为我们提供了99.9%的可用性
99.99%(4个9)方案
应用特点
- 根据可用性图表,这些应用程序的停机时间约为52分钟/年。
- 这些应用程序必须具有高可用性,能够容忍部件故障,并且能够吸收故障而无需获取部件故障。
- 例如电子商务应用程序和b2b web服务。
- 我们应该通过在一个区域内保持静态稳定来进行设计。这意味着我们需要能够容忍一个AZ的丢失,而不需要提供新的容量或更改DNS等。。
部署设计
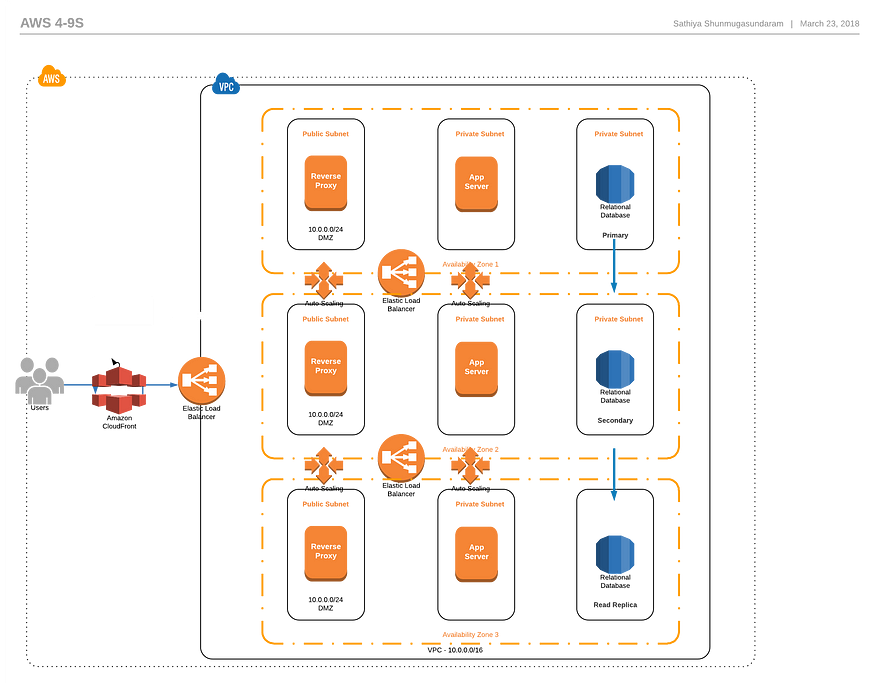
- 在3个AZ中部署应用程序,每个AZ的容量为50%
- 对于可以缓存的内容,请添加CloudFront以减少系统负载
- 在所有层中实施软件/应用程序恢复模式
- 设计主内容的读可用性而非写可用性
- 利用故障隔离区部署策略
- 部署管道还必须包括性能、负载和故障注入测试
- 如果不满足KPI,部署应完全自动化并自动回滚
- 监控应报告成功情况,并在出现问题时发出警报
- 必须存在未发现问题和安全事件的行动手册
- 使用游戏日测试失败程序
可用性计算
假设2次故障需要人工干预,每次事故15分钟,则影响将为30分钟。自动软件更新不需要停机。这为我们提供了99.99%的可用性
多区域部署
使用多个地理区域将以增加支出为代价对恢复时间提供更大的控制。区域提供了非常强的隔离边界。
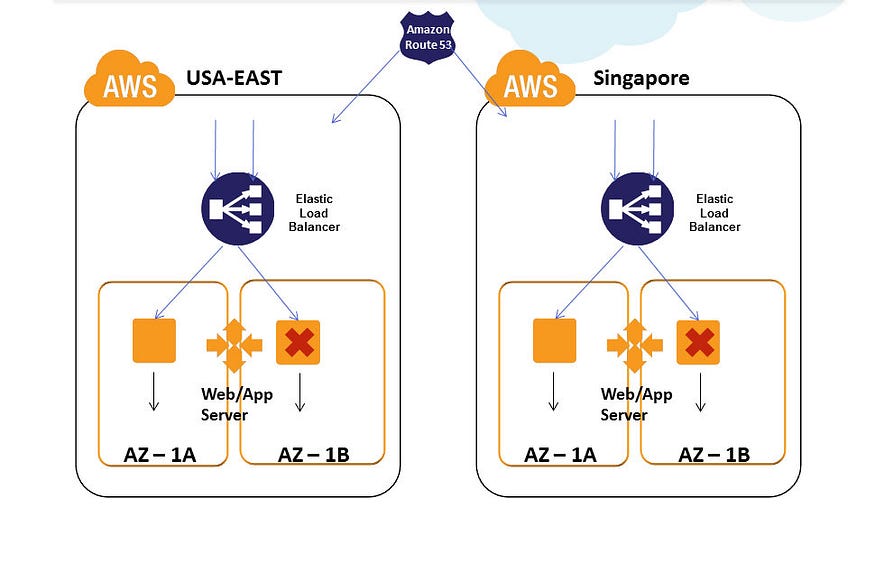
Multi-Region Deployment Courtesy of http://harish11g.blogspot.com
使用多区域部署的99.95%(3.5个9)场景
应用特点
- 根据可用性图表,这些应用程序每年的停机时间约为4小时。
- 这些应用程序必须高度可用,需要非常短的停机时间和很少的数据丢失
- 例如银行、投资和应急服务
部署设计
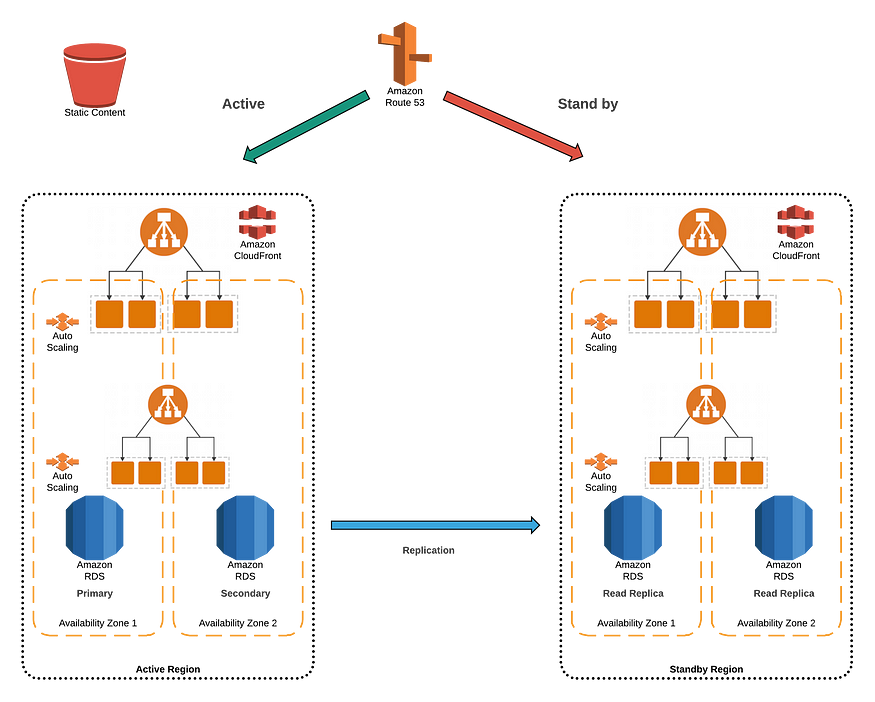
- 99.95 % SLA
- 跨两个区域使用热备用
- 被动站点扩展并最终保持一致,以接收与主动站点相同的流量
- 即使在1个AZ故障期间,两个区域也应保持静态稳定,以处理所有容量需求
- 在所有层中实施软件/应用程序恢复模式
- 将需要一个轻量级的路由组件来监控应用程序运行状况和区域依赖性。路由组件将自动化故障,停止复制
- 故障切换期间,请求将被路由到静态网站
- 软件更新将使用蓝绿/金丝雀部署方法
- 部署管道还必须包括性能、负载和故障注入测试
- 监视服务器/db/静态内容和区域故障并发出警报
- 通过游戏日使用Runbook验证体系结构
可用性计算
假设2次故障需要人工干预,每次事故30分钟,则影响将为60分钟。自动软件更新不需要停机。这为我们提供了最高99.95%的可用性
99.999%(5个9)或更高的方案
应用特点
- 根据可用性图表,这些应用程序每年的停机时间约为5分钟
- 这些应用程序必须高度可用,并且不允许停机和数据丢失
- 例如高收入银行、投资和关键政府职能
部署设计
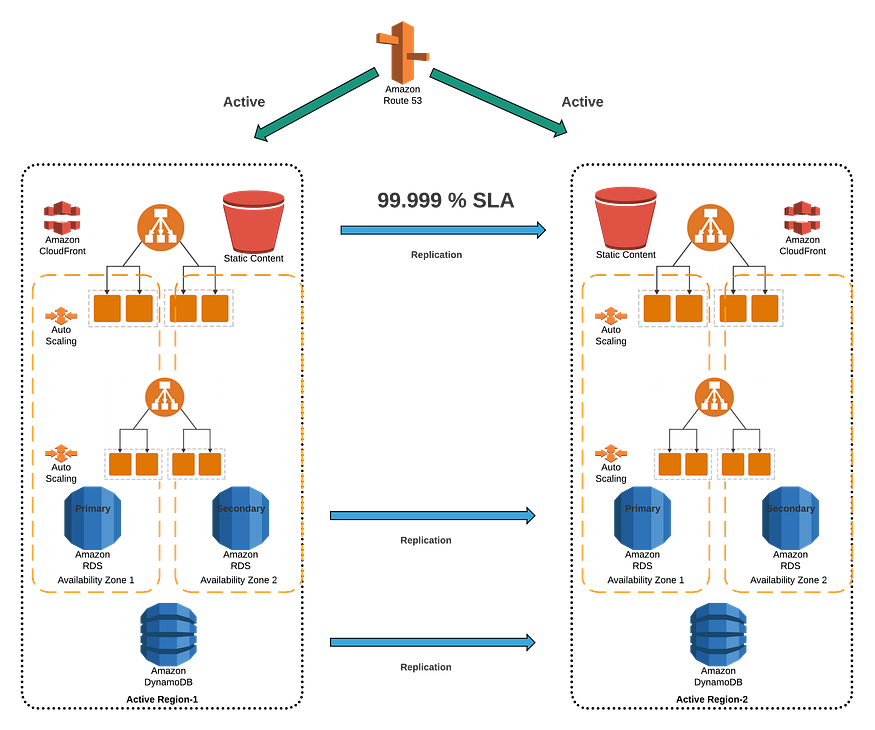
- 强一致性数据存储
- 所有层完全冗余
- 尽可能使用NoSQL数据库来改进分区策略
- 利用主动/主动多区域方法。每个区域必须是静态稳定的
- 路由层将向正常站点发送流量,并在故障期间停止复制
- 在所有层中实施软件/应用程序恢复模式
- 部署管道还必须包括性能、负载和故障注入测试
- 软件更新将使用蓝绿/金丝雀部署方法
- 如果不满足KPI,部署应完全自动化并自动回滚
- 数据存储复制技术应自动解决冲突
可用性计算
假设所有恢复过程都是自动化的,并且具有冗余性,则影响将小于一分钟,预计将发生4次此类事件。自动软件更新不需要任何停机时间。这为我们提供了99.999%的可用性
- 54 次浏览
【高可用性】高可用性的架构模式
您可以查看有关不同体系结构模式的信息,这些模式可用于提高正常运行时间和提高应用程序弹性。
(DOM)应用程序通常部署在外部系统的集成网络中,以形成一个有凝聚力的业务生态系统。长时间的应用程序或系统停机可能会产生严重的业务后果。
解耦和组件独立是一种非常强大的体系结构模式,可以将整个生态系统解决方案的关键部分与其他领域的停机或故障隔离开来。通过在解决方案设计期间采用以下一种或多种模式,可以大大提高基于解决方案的可用性和正常运行时间。这些模式中的每一种都可以使应用程序的一个或多个部分与其他部分分离,从而为外部用户和客户等关键领域提供更高的可用性和正常运行时间。
这些设计模式中的每一种都可以被应用以提供增加的应用弹性。虽然这些示例讨论了网站集成,但这些模式也可以应用于其他集成领域。
围绕系统设计良好的解决方案实际上可以将整个解决方案的可用性和正常运行时间提高到高于开箱即用的水平。例如,在某些关键领域,即使产品计划内或计划外停机,解决方案也可以继续可用。
最后,与基于技术和冗余的解决方案相比,还有一些其他与流程和部署相关的解决方案设计考虑因素实际上可以以更低的成本提供更好的可用性和正常运行时间。
异步集成作为一种解耦技术
您可以使用异步集成作为一种解耦技术,以允许在外部系统仍然可用时不可用。
缓存作为一种解耦技术
当使用缓存作为去耦技术时,消费应用程序(例如,Web商店)从本地数据缓存中获取诸如项目属性、库存余额或项目可用性等信息。这种方法减少了同步查询的需要。
代码、配置和修复程序的热部署
虽然所提供的方法和设计模式使解决方案的关键领域免于停机,但有一些部署技术是由的体系结构提供的或其固有的,允许您在关键的同步应用程序组件上热部署增量更改、配置和修复。
部署过程和回归测试
可以显著影响应用程序可用性和正常运行时间的最重要和最容易被忽视的领域之一是,存在一个严格执行的过程来促进、表征、验证和回归测试增量推出或修复包和升级。
- 30 次浏览
【高可用架构】高可用性设计模式
使用日常商业质量的硬件和软件,可以实现“五个9”的可靠性。关键是这些组件的组合方式。
我们的社会已经开始期待它使用的许多系统提供不间断的服务,例如电话、自动柜员机和信用卡验证网络。其中许多被实现为嵌入式系统。
嵌入式设计人员越来越多地被要求创建能够可靠运行的系统,达到99.999%的时间(称为“五个9”可用性),这相当于每天不到1秒的停机时间。这些系统称为高可用性系统。
高可用性系统的设计基于冗余硬件组件和软件的组合,以管理故障检测和纠正,而无需人工干预。在本文中,我们将快速回顾一些与高可用性和故障管理相关的定义,然后继续讨论容错系统的一些硬件和软件设计模式。
故障与故障(Fault vs. failure)
当我们设计高可用性系统时,我们需要将大部分设计工作集中在故障和故障上。为了更好地定义,我们可以将故障(failure )定义为系统提供的服务不符合其规范的情况。我更喜欢一个将系统提供的服务与我们的期望进行比较的定义,而不是一个规范。但我们的期望往往是主观的,没有很好的文档记录。因此,我们将坚持将系统的服务与其规范进行比较,尽管这会让我们面临来自规范错误或遗漏的问题。
另一方面,故障( fault)是交互系统的故障。这就是我们所认为的不希望发生的事情的可能原因。因此,故障可能是我们系统的子系统故障、组件故障、外部系统故障或编程错误。故障会引发更多的各种故障。或者它们会引发失败。或者,它们可以在不引发任何失败的情况下发生。
例如,故障可能是卡车司机没有遵守金门大桥的负载限制。如果卡车超过负载极限20%或30%,我们预计桥梁不会损坏。但另一个故障可能是同一辆卡车撞上了桥梁道路的中间分隔带。这也不会导致大桥发生物理故障,但可能会导致大桥在数小时内无法实现将人员和车辆穿过金门水道的特定目的。
故障可能是暂时性、永久性或间歇性的。当它们被激活时,可能会导致系统或子系统的状态出错。这些错误可能会引发系统故障。处理故障有四种主要方法:
- 故障预测(Fault forecasting)
- 故障避免 (Fault avoidance)
- 故障排除 (Fault removal)
- 容错性 (Fault tolerance)
故障预测使用数学模型和实际实验来提供故障存在及其后果的估计。例如,一种实用的故障预测技术是将故障注入系统,并研究任何由此产生的故障。
通过使用严格的系统、硬件和软件开发过程(可能包括正式规范和验证技术)来实现故障避免和排除。
容错是通过使用冗余的、可能是多样的系统实现来实现的,以避免故障的影响。实现容错的一种方法被称为“优雅降级”(或“软故障”)——如果不能提供完整的系统性能,则提供合理的部分功能。另一种方式被称为“故障安全”(或“故障停止”)-当出现故障时,将系统停止在安全状态,而不是继续运行。
容错的主要概念是冗余。它基于这样的想法(或希望),即多个独立的故障不会一起袭击您的系统。应设计容错系统以避免单点故障。换言之,如果系统的一部分可能发生故障,那么系统中应该有一个冗余部分可以弥补故障,从而避免故障。
冗余有多种形式:
- 硬件冗余(低级、高级或两者)
- 软件冗余
- 时间冗余
- 信息冗余
硬件冗余的例子包括自检逻辑电路和一架飞机上的多个飞行计算机。软件冗余可能使用两种完全不同的算法来计算相同的结果。时间冗余可以通过通信重新传输来实现。信息冗余可以使用备份、校验和和纠错码来实现。
冗余可以是动态的或静态的。两者都使用复制的系统元素。在静态冗余中,所有副本同时处于活动状态。如果一个复制副本“抛出错误”,则可以立即使用其他复制副本以允许系统继续正确操作。在动态冗余中,一个副本是活动的,其他副本是被动的。如果主动复制副本引发故障,则先前被动复制副本将被激活并接管关键操作。
那么,所有这些与实现高可用性有什么关系呢?首先,一个定义。高可用性是指系统能够容忍故障并根据其规范继续提供服务的能力。系统可以使用此处描述的所有概念和方法来实现高可用性。
可用性通常以“可用性百分比”或“每年停机时间”为单位来衡量。典型的容错系统可能在99.99%的时间内可用,或每年停机不到一小时(每天10秒)。但高可用性系统预计在99.999%的时间内可用,或者每年可用时间不到五分钟(大约每天一秒)。这通常意味着,当出现故障时,必须自动处理。人类太慢,无法在所需的时间内消除或掩盖任何问题。
硬件冗余
与其将硬件构建为由超级可靠组件构建的单个超级可靠模块,不如使用由日常商业质量组件构建的日常商业质量硬件的冗余复制模块通常更具成本效益。
每个复制副本通常都设计为表现出“快速故障”或“故障停止”行为。这大大简化了故障管理决策:每一次故障都会使硬件停止运行;而不是试图一瘸一拐地向故障管理器挑战,以找出模块的哪些输出现在有故障,哪些输出仍然良好。
对于使用静态冗余的容错,每个复制模块可以具有日常商业可靠性。使用两个副本称为配对或双工。如果使用N个副本,则称为N丛。

图1:三重冗余硬件
图1显示了一种3倍或三倍冗余的硬件设计。三个副本显示在图表底部附近。它们将它们的输出提供给“投票器”,后者决定子系统的实际最终输出。当N≥3时,“投票人”通常使用多数决策。但是,这需要是大多数未失败的副本,而不仅仅是副本总数(失败和未失败)的简单多数。
但是,选民不只是一个硬件和软件,可能会像我们系统中的任何其他模块一样出现故障吗?事实上,它可以;如果这样做的话,会给我们的系统带来灾难。但选民通常是非常简单的单位,可以设计和测试以确保其稳健性。或者,您可以创建涉及复制选民和选民的二级选民等的设计。但我们这里不讨论这一点。
对于使用动态冗余的容错,复制的模块仍然具有日常商业可靠性。一种方法是使用由一个活动模块和一个备用模块组成的冗余对。另一种方法是使用模块集群。这些模块不必彼此精确复制,可以具有不同的特性、接口和容量。集群需要故障切换策略来决定当主模块引发故障时如何管理多个模块。以下是一些选择:
- 备用备份(Standby backup)。当主模块在系统中运行时,一个备份模块处于“待机”状态,监视主模块是否存在故障,并准备启动并接管。例如,可以使用这种方法设计高可用性web服务器。
- 旋转备用(Rotating standby)。当主模块在系统中运行时,可能有多个备份模块。主系统出现故障时,一个备份将接管系统的运行。航天飞机上的飞行计算机是按照这样的理念设计的:主模块由一对计算机组成,它们必须始终彼此一致。第一个备份模块是一对类似的模块。但航天飞机上的第二个备用模块是一台计算机,只能通过人工指挥才能接管。
- 故障切换到非关键模块(Failover to non-critical module)。主模块运行系统的关键资源。备份模块可以运行其他非关键功能,但在发生故障时,它可以接管主模块的最关键服务。作为人类,当我们试图发送紧急电子邮件时,电脑的高速互联网连接出现故障,我们会迅速切换到我们从未想过会再次需要的旧调制解调器。
- 相互接管(Mutual takeover)。每个模块运行自己的关键资源,但在发生故障时可以接管另一个模块的关键资源。例如,在心脏重症监护病房中,每8名患者应有一台心脏监测计算机。但是,如果相邻的心脏监测计算机出现故障,每台计算机可以处理另外八名患者(可能有一些轻微的退化)。
故障切换的正确实施至关重要。如果引发故障的主模块继续运行,同时另一个模块试图接管其服务,这将是一场灾难。他们的服务可能会以意想不到的方式发生冲突。如果一个主模块在抛出故障后被停止,而没有其他模块来接管它的服务,这可能同样是灾难性的。因此,故障切换的验证和测试是至关重要的,尽管这不是我们很多人喜欢做的事情。
软件冗余
大多数硬件故障都是随机的,是由物理缺陷造成的,这些缺陷要么在制造过程中持续存在,要么随着组件磨损或受到周围物理世界的冲击而发展。另一方面,软件故障不是物理故障;软件不会磨损。相反,软件故障是由于调用包含软件设计或实现中始终存在的缺陷的软件路径而导致的。由于软件通常比硬件更复杂,因此可以预期它具有更多的内置缺陷,从而导致比硬件故障更多的软件故障。软件容错设计成本也比硬件容错高。
N版本编程是一种成熟的软件容错设计模式。当我在70年代第一次遇到它时,它被称为不同的软件。它是硬件N复用的软件等价物(见图1)。但这并不像硬件N丛的复制那样简单,即同一软件的N个副本将包含相同的错误,并产生N次相同的错误。在N版本编程中,如果某些软件功能的N个单元需要并行运行,它们需要是该功能的N种不同实现,由N个独立的开发团队独立实现。这是N版编程。
1996年6月,阿丽亚娜-5号卫星发射火箭的第一次飞行在到达4000米的高度时发生了火球爆炸。尽管存在硬件冗余,但火箭惯性参考系统(其数字飞行控制的一部分)的故障导致了故障,因为软件冗余没有得到妥善处理。阿丽亚娜-5号上有两台惯性参考计算机,一台处于活动状态,另一台处于“热”备用状态。两者都并行运行,硬件和软件完全相同。该软件与阿丽亚娜-4号上的软件几乎相同,阿丽亚娜4号是一款较旧且成功的运载火箭。但阿丽亚娜-5号上的一些飞行参数值大于阿丽亚娜-4号,因此数据值溢出。该错误是通过关闭计算机来处理的。由于冗余计算机运行的是相同的软件,它也受到了数据溢出的影响,而且很快就被关闭了,整个惯性参考系统都死了。结果,发动机的喷嘴旋转到极端位置,导致火箭突然转向并在自毁前破裂。[1] 数据溢出错误的处理方式适用于随机发生的硬件错误,但不适用于两台计算机上发生的类似软件错误。两台计算机上类似的软件错误可以通过N版本编程避免。
回到70年代,我们认为N版本编程是软件容错的最先进技术。从那时起,这种设计模式出现了许多问题:当你使用它时,软件开发成本飙升,因为你需要支付N个独立的小组来实现N个独立软件设计。但是,如果你试图节省一些成本,你会遇到所谓的“平均智商”问题:成本较低的开发团队拥有资质较差的软件工程师,他们会产生质量较低的代码。因此,你可能会得到N个不同的程序,这些程序都充满了错误,以N种不同的方式创建。
N版本编程的另一个失败是向N个独立开发团队提供什么作为输入的问题。一般来说,一个规范被影印并提供给所有N个开发团队。但是如果这个规范有缺陷,你会得到N个独立开发的类似缺陷软件版本,它们都会做错事。如果在系统发布后发现了规范或使用错误,那么在N个不同的实现中,每个新错误必须被修复N次,从而使维护成本过高。如今,人们通常认为,让一个顶级软件开发团队使用最好的可用基础设施、软件开发工具、技术和测试开发一个高质量的软件版本,可以更好地利用N版本编程的价格。
检查点
与N版本编程的静态冗余不同,许多软件容错设计模式基于动态冗余。它们都采取四个阶段的方法:
- 错误检测
- 损害评估和限制(有时称为“防火墙”)
- 错误恢复
- 故障处理和持续服务
在这些阶段中的第二阶段,当检测到软件错误时,通常采用故障停止方法。但软件是高度复杂的,因此,如何消除围绕错误的错误软件行为的影响通常是不清楚的。在这方面,一个有用的工具是交易的概念。事务是对应用程序状态的操作的集合,因此事务的开始和结束是应用程序处于一致状态的点。例如,每个城市的市政厅都有一个文件系统,其中包含该城镇所有居民的信息。当两个人结婚时,他们的名字和结婚日期都记录在一个名为“已婚夫妇”的文件中。此外,新郎的身份在名为“男性居民”的文件中将从单身变为已婚。新娘的身份在称为“女性居民”的文件中将从单身变成已婚。“如果三个文件更新中的一个失败,或者软件在一路上崩溃,我们需要回到婚姻”交易的开始。“否则,我们可能会出现不一致的状态,比如新郎被列为已婚,而他的妻子仍然被列为单身。”。只有在婚姻交易开始时,以及婚姻交易成功结束时,情况才是一致的。
如果我们想使用事务的概念来容错,我们的系统必须能够在事务开始时保存其状态。这叫做检查点。它包括在即将开始新事务的第一步时对软件状态进行“快照”。仅当上一个事务在无错误状态下完成时,才会拍摄快照。这里的基本恢复策略是重新执行:当在事务期间检测到错误时,事务将失败停止,系统将重新加载回上次保存的检查点。然后从该检查点继续服务,允许新事务建立在其一致状态上。但是,失败停止的事务将丢失。这种错误恢复被称为向后错误恢复,因为软件状态被回滚到过去的无错误点。

图2:检查点回滚场景
简单的检查点有自己危险的单点故障。在拍摄检查点本身的快照过程中可能会出现故障。但有一种解决方案,有时称为检查点回滚。如图2所示。在该图中,省略号表示通过队列发送消息来彼此通信的软件客户端和软件服务器。单个事务可能包括从客户端到服务器的许多请求消息,以及从服务器到客户端的许多响应消息。在事务处理期间,数据在服务器内被修改。在事务结束时,应在右侧显示的两个永久性大容量存储设备中的每一个上记录一组一致的数据。应连同数据一起记录交易序列号。如果稍后检测到错误并且服务器已停止,则可以重新启动此服务器(或启动副本服务器)。作为启动恢复过程的一部分,将检查两个大容量存储设备上的事务序列号。服务器数据将从包含最高序列号的设备中恢复。(另一个大容量存储设备可能包含较低的序列号,因为故障发生在该设备的检查点期间。)
进程对
这种检查点设计模式的一个限制是故障后的恢复可能需要很长时间。启动或重新启动服务器可能需要大量处理,也可能需要将数据恢复回检查点。“热备份”服务器直接使用其自身的永久性大容量存储设备,可以加快恢复速度。这种设计模式称为过程对;如图3所示。

图3:流程对
在这里,我们看到位于图中心的主服务器的工作情况与前面的检查点场景中的工作情况非常相似。客户端直接使用此主服务器。每当主服务器成功完成整个事务时,它就会将有关其新的一致状态的信息传递给备份服务器(右侧)。主服务器和备份服务器都将数据记录在其永久性大容量存储设备中。通过这种方式,备份服务器可以随时了解已完成的事务。当主服务器启动并可供客户端使用时,它会定期向备份服务器发送心跳消息。这些心跳消息可以与一些检查点消息组合。如果备份服务器检测到心跳消息流已停止,则它知道主服务器已停止或不可用,并且它将很快接管新的主服务器。
当客户端、主服务器和备份服务器都在不同的处理器或模块上时,以及当它们都在一个处理器上时,这种设计模式可以工作。
尽管过程对设计模式非常复杂,但仍存在一些问题。例如,检查点消息可能会丢失或无序到达备份服务器。或者,如果主服务器是物理设备的控制器,并且在操作过程中发生故障,则可能会出现问题。备份服务器在接管时可能不知道如何完成操作,因为它不知道主服务器在发生故障之前走了多远。(例如:当发生故障时,主服务器已将核反应堆的石墨棒移动了所需的30cm。)
同样,在流程对设计模式中,当主服务器发生故障时正在进行的事务很可能在执行过程中丢失或丢弃。备份服务器将以主服务器在失败之前向其报告的上次完成事务的状态进行接管。
恢复块
动态软件冗余的另一种设计模式称为恢复块。它基于检查点,但它增加了对软件处理结果的验收测试。您需要像N版本编程一样准备许多处理数据的替代方法,但您并没有为每个事务运行所有处理替代方法。相反,您选择一种处理数据的方法作为主要替代方法,并首先尝试仅使用主要替代方法的处理来执行事务。在主处理结束时,运行验收测试。如果通过了验收测试,你就完成了。如果验收测试失败,则继续尝试下一个替代处理,如图4所示。

图4:恢复块
如图所示,在首次进入恢复块之前,必须执行检查点操作。每次验收测试失败后,软件必须回滚到检查点状态。验收测试是在尝试的每个处理备选方案之后进行的。以这种方式,在处理备选方案成功交付通过验收测试的结果之前,将运行处理备选方案。这些“良好”输出构成了恢复块的最终结果。
前向错误恢复
检查点回滚、进程对和恢复块都是执行向后错误恢复的方法。大多数动态软件容错是使用反向错误恢复来完成的,但正向错误恢复是另一种选择。它的主要思想是从错误状态继续,并进行纠正,以清理受损状态。前向错误恢复取决于准确的损伤评估,通常是系统特定的。前向错误恢复的一个例子是异常处理,它在检测到问题时将控制权传递给专门的异常处理软件,而不是回滚并从以前的检查点状态继续。
前向错误恢复的一种设计模式称为替代处理。当一个事务有两个(或多个)处理备选方案时,可以使用此方法,其中一个备选方案通常非常精确但计算复杂,另一个备选更简单且性能更高。如果主处理出现故障,则第二个备选方案可以用作测试和辅助结果提供程序。例如,平方根算法可以是主要处理,表查找插值可以是其替代方法。一旦算法运行完毕,可以使用表查找插值来测试平方根算法结果的质量,并快速修复这些结果中的一些错误。

图5:飞机飞行控制的替代处理
在图5中,我们看到两个数字飞行控制系统同时运行,以控制一架飞机(波音777)。[2] 图右侧的决策逻辑使用更简单的飞行控制系统的输出作为测试复杂的主飞行控制系统输出的标尺。如果验收测试失败,那么更简单的飞行控制系统的输出也可以作为失败的主要输出的替代。(向左的箭头表示替代处理的结果也可用于向主处理提供反馈。)
这样的设计模式允许将日常商业质量的硬件和软件用作真正高可用性系统的构建块,这些系统可以在无需人工干预的情况下实现“五个9”或更高的可用性。
David Kalinsky是OSE Systems的客户教育总监。他是嵌入式软件技术的讲师和研讨会领导者。近年来,David建立了软件工程方面的高科技培训项目,以开发实时和嵌入式系统。在此之前,他参与了许多嵌入式医疗和航空航天系统的设计。大卫拥有耶鲁大学核物理学博士学位。可以在联系到他。
尾注
- 47 次浏览
性能工程
- 26 次浏览
【性能工程】以用户为中心的web性能指标
- 26 次浏览
【性能工程】十大网站性能指标
十大网站性能指标
发现您网站的十个重要性能指标,从页面速度到转化率,以及如何使用这些重要指标来改进您的网站并让您的访问者满意。
如果您像大多数企业主一样,您可能已经花费了大量时间和金钱来开发您的网站。这是有充分理由的。您的网站是一种非常有价值的资源——它是每天接触客户的最大方式,也许是您可以使用的最强大的营销工具。无论发生什么,确保您的网站始终处于最佳状态才有意义。
但是,您网站的性能可能会因多种因素而波动。这就是为什么关注您网站的性能指标很重要的原因。您网站的性能指标将使您深入了解它的运作方式以及是否需要进行改进,因此它会更好地为您网站的未来访问者运行。但是,您甚至可能没有意识到这些指标的重要性以及性能的微小波动可能意味着什么。这就是为什么我们在下面分解这些重要的性能指标,包括您应该了解的内容以及它们对您网站性能的指示。
1.页面速度
页面速度是需要注意的最重要的指标之一,它的影响可能比你想象的要大得多。简而言之:人们不喜欢等待!尽可能快地保持页面速度,以保留尽可能多的受众。
您是否曾经访问过一个新网站,但在加载过程中却出现了停顿?这是一个令人沮丧的过程,我们都非常熟悉。页面速度慢是所有互联网用户生活的一部分,但如果您的网站遇到页面速度缓慢的问题,您需要找到可以立即开始加快速度的方法。缓慢的页面速度是让人们转身离开您的网站的最快方法之一,无论您要说什么或要卖什么。
从技术角度来看,页面速度是页面加载所需的时间,它包含三个不同的指标:
- 服务器响应时间通常称为首字节时间 (TTFB) -- time to first byte
- 下载 HTML 网页所需的时间 - 也称为传输时间 -- transfer time
- 在浏览器中呈现网页所需的时间 渲染时间 --render
归根结底,页面速度是指从向服务器发送 HTTP 请求到在浏览器上完整和最终显示网页的整个时间跨度。

2. 标题时间 (Time to Title)
与您的页面速度类似,标题时间是个人请求网站后网站标题出现在浏览器选项卡中所需的时间。除了测试个人的耐心之外,页面标题出现的时间越长,网站看起来就越不合法。
虽然这似乎是一个相当小且微不足道的细节,但标题时间可以帮助缓解对网站信誉良好的任何担忧或焦虑,因此这是一个需要关注的重要指标。
3. 开始渲染的时间 (Time to Start Render)
个人发出请求所花费的时间以及内容开始加载所花费的时间——即使它没有完全加载——被称为开始渲染的时间。它与构成页面速度的最后一个指标非常相似——网站渲染所需的时间——但是,它不是渲染所需的全部持续时间,只是开始加载所需的时间。
这个指标也很重要,因为即使页面上的内容没有完全加载,如果个人看到内容开始出现,他们更有可能留在页面上。虽然如果加载所有内容的时间过长,网站访问者的耐心可能仍会受到考验,但快速开始渲染足以让人们保持兴趣并让他们留在您的网站上。
4. 交互时间 (Time to Interact)
另一个与用户耐心有关的指标是交互时间。它指的是个人开始点击链接、输入文本字段、滚动页面以及以其他方式与网站交互之前需要多长时间。正如您可以想象的那样,这是另一个重要的指标,因为个人开始与网页交互的速度越快,他们离开页面的可能性就越小,即使页面没有完全呈现。
一个真实的例子是,如果您在网上购物时将商品添加到购物车,然后立即结账。结帐按钮或链接出现并起作用所需的时间将是在这种情况下进行交互的时间。
5. DNS 查询速度 (DNS Lookup Speed)
您可能听说过“DNS 查找速度”或“DNS 查找时间”,但您可能并不完全理解这个指标是什么。这是指您的域名系统 (DNS) 提供商将域名转换为 IP 地址所需的时间。重要的是要注意,那里有更快和更慢的 DNS 提供商,如果您使用较慢的提供商,它会大大降低您的 DNS 查找速度。
您可以使用大量免费的在线工具来测试您的 DNS 查找速度,并且使用优质的 DNS 提供商可确保您拥有更快的 DNS 查找速度。我们建议您尽可能找到最快的 DNS 提供商。
6. 跳出率(Bounce Rate)
你的跳出率和听起来差不多。人们在没有彻底搜索的情况下“弹跳”离开您的网站,有时甚至没有花时间让网站正确加载。它也可以定义为对您网站的单页访问,用户无法在其他地方进行交互。这通常(尽管并非总是)意味着您的网站的加载时间存在问题或需要紧急解决的类似问题。
如果您发现跳出率很高,那么值得立即查看您的其他指标——尤其是那些倾向于影响访问者在您网站上停留时间的指标。通常,只需进行一些简单的网站改进就足以让访问者留住更长的时间,从而提高您的跳出率。

7.每秒请求数(Requests Per Second)
有时也称为“吞吐量”或“平均负载”,此指标是指您的服务器每秒接收的请求数。这是一个相当基本的指标,用于衡量服务器的主要用途,那些大规模工作的服务器每秒可以达到 2000 个以上的请求。它会让您知道您的 Web 应用程序所承受的压力以及是否需要进行任何调整。
8.错误率 (Error Rate)
在任何给定时间,您的网站上都会不可避免地出现一些错误。您的错误率衡量在任何给定时间发生的错误数量,并跟踪特定时间范围内发生的错误数量。这不仅可以让您了解平均发生的次数,还可以让您知道错误何时会增加。例如,当您的网站上有更多用户时,例如在特殊促销期间,错误可能会更频繁地发生。了解它们何时发生以及需要注意什么可以帮助您预防可能出现的问题,并最大限度地减少可能出现的更大问题。
9. 第一个字节/最后一个字节的时间 (Time to First Byte/Last Byte)
我们简要介绍了第一个字节的时间作为页面速度的一个子集,但它是一个足够重要的指标,足以保证它自己的细分。
需要注意的更重要的信息是第一个个性化信息到达用户的 Web 浏览器需要多长时间,在这种情况下称为第一个字节或 TTFB 的时间。 Google 建议您的 TTFB 保持在 200 毫秒 (ms) 以下。
虽然网站上的所有静态信息通常会很快到达所有用户,但个性化信息可能需要更长的时间,因此这是一个需要考虑的重要指标。代码中的细微改动可以提高这些信息到达的速度。同样,最后一个字节的时间或 TTLB 是指用户收到所有信息的时刻,同样,代码的质量对于这种情况发生的速度起着至关重要的作用。
10. 转化率 (Conversion Rate)
最后但同样重要的是,我们不能在不讨论转化率的情况下讨论指标。这是指有多少独特的访问者最终转化为客户。各种因素会影响转化率,但不可能确定所有因素都在将网站访问者转变为客户的过程中发挥作用。
转化率只是指唯一网站访问者的数量除以转化次数。但是,在转化中发挥作用的众多因素包括您网站上的整体用户体验 (UX)、获得正确类型的流量和网站访问者、在您的网站上具有良好的速度、使用出色的号召性用语,以及许多更重要的变量。有很多方法可以不断提高转化率,让更多的网站访问者转变为客户,这是构建网站的主要目标。

综上所述
持续衡量您网站的指标以了解您的网站在任何给定时间的成功情况至关重要。 虽然您可以日复一日地继续在您的网站上工作,但除非您密切关注这些指标并定期监控它们,否则您永远不会知道它的表现如何。 当您进行改进时,请注意所有指标的性能以响应这些调整。 这将比任何其他方法更好地衡量您的改进是否真正有助于最大化您的转化率和促进销售。
尽管这似乎是一项艰巨的任务,但只要有足够的时间和才能,任何 Web 开发团队都可以做到。 这十个网站性能指标虽然不是在构建和开发网站时唯一值得考虑的指标,但对于确保您的网站能够在当今竞争激烈的在线市场中取得成功至关重要。
原文:https://pantheon.io/blog/top-website-performance-metrics
本文:https://jiagoushi.pro/top-ten-website-performance-metrics
- 36 次浏览
韧性设计
- 52 次浏览
【架构质量】可靠性系列#1:可靠性与韧性
每当我与客户和合作伙伴谈论可靠性时,我都会被提醒,虽然组织和客户之间的目标和优先级不同,但归根结底,每个人都希望他们的服务能够发挥作用。作为客户,您希望能够在方便的时候在线进行操作。作为一个组织或服务提供商,您希望您的客户在他们想要的任何时候执行他们想要执行的任务。
本文是关于构建弹性服务的四部分系列中的第一篇。在我的前两篇文章中,我将讨论与业务战略相关的主题,然后我们将更深入地研究技术细节。四个帖子的完整系列将涵盖:
- 1. 可靠性与弹性——可靠性和弹性之间有什么区别,为什么重要?
- 2. 与可靠性相关的常见威胁——DIAL(发现、错误、授权/身份验证、限制/延迟)是一种方便的助记符,可帮助团队以结构化的方式集思广益,以解决其服务组件之间交互的潜在故障。关于故障模式和故障点的头脑风暴是弹性建模和分析 (RMA) 的关键阶段,可以帮助团队提高服务的可靠性。
- 3. 可靠性增强技术——以 DIAL 中的“D”和“A”为例,我们将研究一些可以纳入与发现和身份验证相关的设计中的可靠性增强技术。
- 4. 可靠性增强技术——以 DIAL 中的“I”和“L”为例,我们将研究一些可用于与错误和限制相关的设计中的可靠性增强技术。
我的目的是深入了解 Microsoft 如何看待可靠性以及我们为提高客户服务可靠性而采用的流程和技术。
那么什么是可靠性?当我询问客户和合作伙伴时,最常见的回答是性能、速度、可用性的一致性——也许最重要的是——弹性。我们都同意的一件事是,要使系统或服务可靠,用户必须相信“它可以正常工作”。
电气和电子工程师协会 (IEEE) 可靠性协会指出,可靠性 [工程] 是“一门设计工程学科,它应用科学知识来确保系统在给定的环境中在所需的时间内执行其预期功能,包括能够在整个生命周期内测试和支持系统。”对于软件,它将可靠性定义为“在特定环境中特定时间段内软件无故障运行的概率”。
可靠的云服务本质上是按照设计者的预期、预期的时间以及客户连接的任何位置运行的服务。这并不是说每个组件都必须在 100% 的时间内完美运行。最后一点让我们明白了我认为可靠性和弹性之间的区别。
可靠性是云服务提供商追求的结果——它就是结果。弹性是基于云的服务能够承受某些类型的故障,但从客户的角度来看仍保持正常运行的能力。换句话说,可靠性是结果,而弹性是实现结果的方式。一项服务可以被描述为可靠,仅仅因为该服务的任何部分都没有发生过故障,但该服务不能被视为具有弹性,因为这些增强可靠性的能力可能从未经过测试。
这里的关键要点是在软件开发生命周期的每个阶段关注弹性以及在您的服务中设计和构建弹性的重要性。 要了解有关构建可靠在线服务的基础知识的更多信息,请阅读我们的白皮书“设计可靠云服务的介绍”。
原文:https://www.microsoft.com/security/blog/2014/03/24/reliability-series-1…
本文:https://jiagoushi.pro/reliability-series-1-reliability-vs-resilience
- 92 次浏览
【韧性工程】所有开发人员都应该知道的韧性软件策略
失败是不可避免的。 然而,正确的软件设计和开发选择可以帮助最大限度地减少其影响、隔离问题并加快恢复时间。
许多架构师努力设计具有避免灾难性故障的能力的应用程序系统。不幸的是,在现实世界中,导致崩溃的错误和过载是不可避免的。
为了正确处理此类故障,开发团队必须为自己配备正确的软件弹性实践。在追求设计风格(例如基于微服务的架构)时,这一点尤为重要,在这种架构中,故障可能会蔓延到分布式组件并导致广泛的中断。
各种软件弹性技术和机制可以帮助团队响应错误、启动恢复过程并在发生故障时保持一致的应用程序性能。让我们来看看架构师可以实施的四种策略来解决错误、最大限度地减少故障的影响并持续维护弹性软件架构。
创建死信队列
个人通信可能因多种原因而陷入困境,例如不可用的收件人、格式不正确的请求和数据丢失。这在事件驱动架构中尤其成问题,其中请求通常被放入消息队列以等待处理,而请求服务继续进行下一个操作。因此,未处理的消息会迅速堵塞这些队列。
死信队列引入了一种机制,专注于处理这些流浪消息,以防止它们使通信渠道混乱,并不必要地吸走保持它们流通所需的资源。开发团队可以设置死信队列来识别滞留消息并隔离故障。这使架构师能够检查特定错误,并维护有助于指导未来设计选择的详细历史文档。
一旦这些恶意消息被认为是过时的,就可以随意从队列中删除它们。或者,可以将它们重新提交以恢复操作或复制错误以进行调试。
使用功能切换进行修改
软件弹性的另一个重要因素与开发团队的功能更新发布周期的方法有关。与其停止添加功能和修改应用程序功能的操作,组织可以使用功能切换方法在推出和更新期间保持应用程序正常运行。
功能切换使开发人员能够增量修改应用程序,同时保持现有生产级代码不变。金丝雀发布和 A/B 测试等技术使开发人员能够在有限数量的实例中推出更新的代码,同时将原始代码保留在生产环境中。
使用功能切换方法,团队可以通过监视新版本实例并使用类似切换机制的回滚来战略性地配置版本,以防修改导致损坏。在某些情况下,如果系统检测到某些错误或性能不一致,团队可能能够自动触发这些回滚切换。
基本弹性设计模式
为了维护弹性软件,开发团队使用特定的设计模式,专注于包含故障和提供紧急对策。许多模式提供了这些类型的恢复机制,并阻止错误从一个分布式组件不受控制地传播到另一个分布式组件。这里有些例子:
- 舱壁(Bulkhead)。此模式隔离子系统并配置单个模块以在出现故障时停止与其他组件的通信,从而降低问题传播的风险。
- 背压(Backpressure)。背压模式自动推回超过预设流量吞吐量容量限制的工作负载请求,保护敏感系统免受过载。
- 断路器(Circuit breaker)。基于隔板和背压模式,断路器提供了一种机制,可以自动切断与有问题的组件的连接。它将定期重试连接以查看错误是否已解决。
- 批量到流(Batch-to-stream.)。该模式旨在管理批处理吞吐量,修改批处理工作负载并将其转换为简化的 OLTP 事务。
- 优雅的退化(Graceful degradation)。这种设计模式本质上为应用程序的所有主要组件安装了一个回退机制。虽然这主要是为了帮助为更新提供回滚,但它也可以在突然失败的情况下派上用场。
促进组件之间的松散耦合
传统的单体应用程序意味着紧密耦合架构中的刚性依赖关系。结果,一个软件组件几乎肯定会影响另一个。或者,在微服务等分布式系统中,架构师可以通过解耦软件组件来最小化这些依赖关系。
在松散耦合架构中,应用程序组件、模块和服务之间存在的依赖关系保持在最低限度。相反,抽象处理必要的数据传输和消息传递过程。因此,发生在一个组件上的更新或故障不太可能导致对另一个组件的意外更改。解耦可以隔离问题并防止它们在其他软件环境中传播,从而限制出现广泛错误的风险。
使用 sidecar 容器来限制故障
Sidecar 是一个支持容器,它与主应用程序容器在同一个 pod 中运行。 Sidecar 使团队能够向容器添加功能并与外部服务集成,而无需更改主要的现有应用程序容器实例。
对于软件弹性,这种技术是有益的,因为主要的应用程序逻辑和代码库保持隔离,限制了风险和故障。然而,边车也有缺点。例如,添加 sidecar 意味着开发人员负责管理更多的容器和增加的资源消耗。努力确保sidecars 不会使工作负载复杂到影响应用程序性能的程度。对于初学者,您需要建立一个完整的容器监控系统,该系统将跟踪边车并衡量它们对它们所服务的生产级容器的影响。
原文:https://www.techtarget.com/searchapparchitecture/feature/Resilient-soft…
- 41 次浏览
【韧性架构】韧性性工程的重要性

韧性工程的重要性
本周 AWS 发生了更大的中断,当然媒体报道再次大肆报道。例如,“亚马逊网络服务中断使企业陷入困境”,华盛顿邮报的标题,仅举一个例子。
你可以找到更多的媒体报道。然而,对我来说,有趣的部分并不是 AWS 发生了罕见的中断之一。这是大多数文章的底线:AWS 发生了部分中断,因此使用 AWS 的公司步履蹒跚。
换句话说:AWS 是有罪的。这些公司是受害者。
个人觉得,没那么简单。实际上,我认为 AWS 按承诺交付,并且确信像 Netflix 这样的一些公司根本不会因为这次中断而步履蹒跚。那么,其他公司做错了什么?
不了解分布式系统
IMO 的第一个问题是,步履蹒跚的公司对分布式系统的本质了解得不够好,无法正确评估风险。
有趣的是,我刚刚在上一篇文章中描述了分布式系统的影响:
- 跨流程边界出现问题。
- 你无法预测什么时候会出错。
- 它会在应用程序级别打击你。
这就是您对分布式系统的基本总结。或者正如亚马逊首席技术官 Werner Vogels 有时描述的那样:
“一切都失败了,一直都是。” ——维尔纳·沃格尔斯
他之所以这么说,是因为 AWS 的人会做的很马虎。看看他们运营的系统环境的复杂性和规模以及他们经历的罕见的更大中断,他们做得非常好 . 他这么说是因为他真正了解分布式系统的本质。
这种“事情会出错并在应用程序级别打击你”不仅对应用程序的某些部分有效。您还需要考虑您使用的基础设施。在任何分布式系统中,即不同的进程(通常在不同的机器上运行)交互时,您必须查看所有“移动”部分及其交互。
您使用的基础架构也是分布式应用程序环境的一部分。这是陷入困境的公司没有(足够)考虑到的。
100% 可用性陷阱
如果软件工程师设计一个分布式应用程序,例如,使用微服务,至少有时他们会考虑他们自己实现的应用程序部分的潜在故障。
但是,一旦涉及应用程序与之交互的其他部分,无论是其他应用程序还是基础设施组件,100% 可用性陷阱就会发生。这个陷阱是一种普遍的、隐含的思维模式,在企业环境中尤其常见。陷阱是这样的:
100% 可用性陷阱(谬误)
我的应用程序与之交互的所有东西都是 100% 可用的。
如果您明确询问人们是否认为这些其他部分可能会失败,他们会说是的。但他们的决定和设计并没有以任何方式反映它。
想想你知道的应用程序代码,例如,尝试写入数据库。如果访问失败会怎样?是否有替代操作编码在这种情况下要做什么,例如,首先重试写入,如果仍然失败将写入请求放入队列并稍后处理,包括监视和处理队列的逻辑?
我很确定,没有这样的代码。最有可能的是,相应的异常被捕获、记录,然后……好吧,继续前进,就好像什么都没发生一样。在韧性工程中,这被称为“静默失败”。您检测到错误,决定忽略它并继续前进。
这种行为在某些地方可能很好,但通常情况并非如此。大多数情况下,这只是 100% 可用性陷阱的结果:从未讨论过故障场景,期望的行为仍未定义,因此实现开发人员不知道如何处理这种情况。因此,他们记录了出现问题并继续前进。他们还应该做什么?
不过,从业务角度来看,这通常不是您想要的。假设这是关于写命令。订单就是你赚钱的东西。订单就是你赖以生存的东西。因此,这是整个应用程序中最重要的一次写入。
现在假设如果由于某种原因写入失败,则命令只是默默地不写入。如果你搜索它,你可以在日志中找到它,但就是这样。这不是你想要的。
或者客户收到一条通用消息,例如:“处理您的请求时出现问题。请稍后再试。” – 这有点好,但也不是你想要的。
从业务的角度来看,您想要的根本不是失去任何订单,因为订单是您存在的基础。
因此,您会期望一些逻辑,例如首先重试写入。如果失败,将订单缓存在队列或其他辅助存储介质中,向客户发送消息,例如“非常感谢您的订单。由于暂时的技术问题,我们无法立即处理您的订单。但我们会在问题解决后尽快处理。这是一个 URL,您可以在其中跟踪您的订单处理状态”,实现并运行队列处理器以及订单处理状态页面。
如果您从业务角度对订单写入过程的期望行为进行推理,您可能会得到这样的结果。但由于 100% 可用性陷阱,通常不会进行这种讨论。
因 AWS 中断而步履蹒跚的公司很可能从未进行过这样的讨论。
不评估 SLA
但是,即使公司对分布式系统了解得不够好并陷入 100% 可用性陷阱,仍然存在 AWS 提供的 SLA,应将其视为风险管理来源。
阅读 AWS 提供的 SLA,我的第一个想法是,如果我想将停机风险降到最低,我需要自己采取额外的措施。我的印象是,步履蹒跚的公司没有这样的想法。
事件的事后分析表明,Kinesis 处于停电的中心。这也影响了其他一些使用 Kinesis 的 AWS 服务。
通常,像 AWS 这样的公司会尽量减少级联故障的可能性。但是在像 AWS 这样的复杂系统环境中,您往往会有微妙的、未知的交叉依赖关系,只有在发生重大故障时才会意识到这些依赖关系,即使您在分布式系统设计方面与 AWS 一样有经验。
但让我们暂时只关注 Kinesis。 Kinesis 提供的 SLA 规定:
AWS 将尽商业上合理的努力使每个 AWS 区域在任何月度计费周期内的每个包含服务 4 的月正常运行时间百分比至少达到 99.9%(“服务承诺”)。
请注意该句子中的“商业上合理”。这不是不惜一切代价保持的保证,但前提是它在商业上对 AWS 有意义。如果他们不能遵守 SLA 的承诺,他们会提供补偿:
如果包含的服务不符合服务承诺,您将有资格获得如下所述的服务积分。
下表列出了根据计费周期内包含服务的实际可用性而定的补偿金额:
| Monthly Uptime Percentage | Service Credit Percentage |
|---|---|
| Less than 99.9% but equal to or greater than 99.0% | 10% |
| Less than 99.0% but equal to or greater than 95.0% | 25% |
| Less than 95.0% | 100% |
IMO 这是一个大胆的承诺。我不知道有任何 IT 部门为其本地基础设施提供甚至接近的 SLA——而且本地基础设施的复杂性比 AWS 提供的基础设施要简单几个数量级。因此,从我的角度来看,关于 SLA 没有什么可抱怨的。
但是,这就是重点:它不是 100% 的可用性保证。
一个月内 99.9% 的可用性意味着您每月仍有超过 43 分钟的不可用时间。这意味着您每月可以轻松丢失 10.000 条消息,而 AWS 不会违反其 99.9% 的可用性承诺。
如果 Kinesis 在一个月内停机最多 7.2 小时,您将少付 10% 的 Kinesis 账单,而对于每月最多 1.5 天的停机时间,您将少付 25%。仅当相关月份的停机时间超过 1.5 天时,您才无需支付任何费用。关于最近的 AWS 中断,这意味着受影响的公司可能会在下个月的 Kinesis 账单中获得 10% 或 25% 的信用额度。
请注意,这不包括因停电造成的收入损失或其他问题的补偿。
再说一遍:我认为 Kinesis SLA 非常好。但是,如果您将此 SLA 与 100% 可用性保证混淆并押注于持续正常运行时间,那么您就错了。
这只是关于使用 Kinesis。任何重要的基于云的应用程序都使用多种服务,通常是十几个或更多。如果您浏览他们的 SLA,您将获得类似的可用性承诺 。
现在让我们假设,您使用 10 个服务。为简单起见,让我们另外假设使用的所有服务都提供与 Kinesis 相同(良好)的 SLA。
重点是:使用的所有部件的可用性成倍增加!
这意味着:如果您使用 10 项具有 99.9% 可用性承诺的服务,那么总体而言,您使用的组合服务的可用性承诺将下降到 99%——如果它们完全不相关 . 如果它们具有依赖关系(正如我们在整个中断),预期可用性较低。这意味着如果所有服务都遵守其 99.9% 的可用性承诺,则在一个月内至少有 7.2 小时的可预期不可用性。
换句话说:如果没有额外的措施,您需要为平均云应用程序每月的一个工作日(从 9 到 5 个)不可用的基础设施做好准备。如果从这个角度来看,停电并没有什么特别之处。无论如何,这只是您需要期待的事情。这个故事令人惊讶的部分是这样的中断很少发生。
也许 AWS 做得太好了,通常远远超出了他们的承诺,结果客户认为可用性是理所当然的,如果预期发生,就会变得草率并抱怨很多。媒体也加入进来。
但最后,步履蹒跚的公司很可能没有足够仔细地评估 SLA。都在里面。你只需要做数学。
本地环境中的相同模式
总而言之,似乎步履蹒跚的公司
- 不了解分布式系统的效果不够好
- 陷入 100% 可用性陷阱
- 没有足够仔细地评估提供的 SLA。
但公平地说:这种心态和由此产生的行为不仅限于公共云的使用。我们随处可见。
我们在本地场景中看到的更多,其中数据库、消息队列、事件总线、容器调度程序、VM 管理程序等都被视为 100% 可用 - 但事实并非如此。此外,在设计在此基础架构上运行的应用程序之前,他们的 SLA(通常比我们看到的 Kinesis SLA 更差)通常没有得到足够仔细的评估。
此外,通常认为远程应用程序在本地环境中 100% 可用。在许多微服务实现中可以观察到相同的效果,其中所有其他服务都被认为是 100% 保证的。
当人们在他们呼吁使用服务网格、Apache Kafka 等时发现这种假设是错误的,并期望这些额外的基础设施能够很好地解决他们的问题——再次陷入 100% 可用性陷阱。
韧性与混沌工程
正如我在这篇文章的开头所写的,不管你怎么看:
- 在分布式系统中,跨进程边界的事情会出错。
- 你无法预测什么时候会出错。
- 它会在应用程序级别打击你。
尤其是最后一句话很重要:它将在应用程序级别打击您。这就是您需要韧性工程的原因。
韧性工程可让您系统地评估业务用例的重要性,检查潜在的故障模式并决定对策。如果操作正确,它是一种强大的风险管理工具,还可以考虑您行为的经济后果。
关于 AWS 中断,韧性工程会问如果发生更长时间的云基础设施中断会产生什么后果。如果影响太大,下一个活动是确定最关键的用例。然后识别潜在的故障场景并定义对策。
最后,这是简单的风险管理:你能承受多少停机时间,你想怎么做?
通常,韧性工程与混沌工程相辅相成。韧性工程可帮助您解决已知的故障模式,而混沌工程可帮助您检测未知的故障模式(并验证韧性措施的有效性)。
与探索性测试类似,您可以模拟任意故障情况并观察系统如何响应它。请注意,您始终小心控制故障模拟(称为“实验”)的“爆炸半径”,即限制实验的潜在影响。
通常,你会在所谓的“游戏日”中捆绑一整套实验。在更高级的组织中,您不断运行故障模拟并观察结果。
即使这个术语听起来有点儿戏,混沌工程也绝不是一场游戏。它是风险管理的重要组成部分。如果您有必须启动并运行的关键用例,则需要探索未知的故障源。在分布式系统中,这不是可选的,但可以决定成败。
您可能会争辩说您没有时间或预算。好吧,步履蹒跚的公司可能采取同样的方式。问题是:这些公司在停电期间没有完成韧性和混乱工程作业,损失了多少金钱和声誉?他们中的一些人可能无法幸免于难。
因此,您需要问自己一个问题:您负担得起吗?
就个人而言,我认为大多数公司都不能忽视韧性和混沌工程。他们中的一些人仍然忽略它,希望事情会顺利进行。但如果涉及风险管理,希望是一个糟糕的顾问。
总结起来
这篇博文比我预期的要长得多,而且我承认我只是触及了表面。我的主要信息是:
- 说在中断期间运行在其基础设施上的应用程序停机是 AWS 的唯一错误,IMO 是不正确的。
- 步履蹒跚的公司对分布式系统的影响不够了解,并陷入了 100% 可用性陷阱。
- 步履蹒跚的公司对 SLA 的评估不够好。从 SLA 的角度来看,中断是意料之中的事。
- 韧性工程有助于评估和减轻可用性,从而降低经济(或更糟)风险。这不仅仅是一场 IT 秀,而是业务和 IT 的共同努力。
- 混沌工程通过发现未知的故障模式来增强韧性工程。
- 韧性和混沌工程是当代风险管理的重要、非可选工具。忽略它们意味着让自己步履蹒跚——或者更糟。
还有很多话要说,但帖子已经太长了。我将在以后的帖子中更详细地讨论讨论的主题。但是现在,我将把它留在那里,希望我能给你一些想法来思考。
- 119 次浏览
【韧性架构设计】分布式系统的韧性
由许多协同工作的微服务组成的云原生应用程序架构形成了一个分布式系统。确保分布式系统可用——减少其停机时间——需要提高系统的弹性。弹性是使用提高可用性的策略。弹性策略的示例包括负载平衡、超时和自动重试、截止日期和断路器。
弹性可以通过不止一种方式添加到分布式系统中。例如,让每个微服务的代码都包含对具有弹性功能的代码库的调用,或者让特殊的网络代理处理微服务请求和回复。弹性的最终目标是确保特定微服务实例的故障或降级不会导致导致整个分布式系统停机的级联故障。
在分布式系统的上下文中,弹性是指分布式系统能够在不利情况发生时自动适应以继续服务于其目的。
术语“可用性”和“弹性”具有不同的含义。可用性是分布式系统启动的时间百分比。弹性是使用策略来提高分布式系统的可用性。
弹性的主要目标之一是防止一个微服务实例的问题导致更多问题,这些问题升级并最终导致分布式系统故障。这被称为级联故障。
弹性策略
分布式系统的弹性策略通常用于 OSI 模型的多个层,如图所示。例如,物理和数据链路层(第 1 层和第 2 层)涉及物理网络组件,例如与 Internet 的连接,因此数据中心和云服务提供商将负责为这些层选择和实施弹性策略。
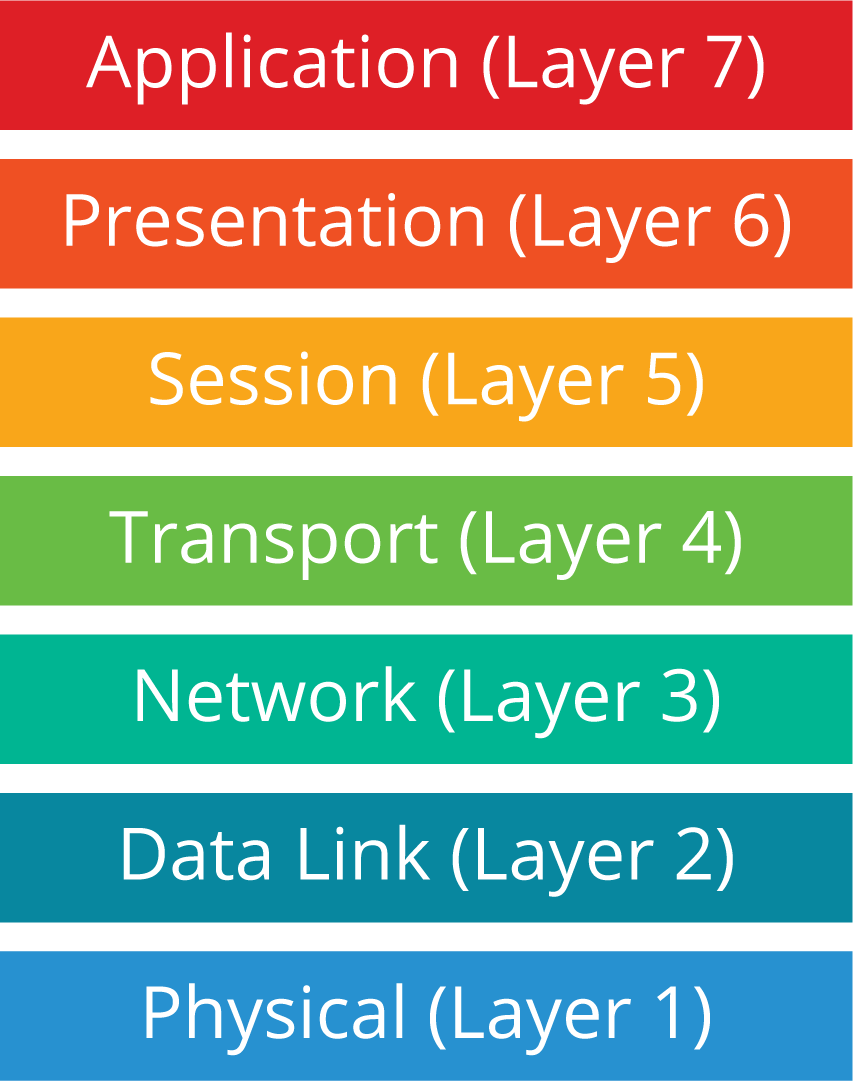
应用层是应用驻留的地方;这是人类用户(以及其他应用程序)直接与之交互的层。应用程序级(第 7 层)弹性策略内置于微服务本身。组织的开发人员可以设计和编写应用程序,使其在降级状态下继续工作,提供重要功能,即使其他功能由于一个或多个微服务的错误、妥协或其他问题而失败。
在流行的视频流应用程序的推荐功能中可以看到此类功能的一个示例。大多数时候主页包含个性化推荐,但如果相关的后端组件出现故障,则会显示一系列通用推荐。此故障不会影响您搜索和播放视频的能力。
传输层(第 4 层)提供网络通信能力,例如确保可靠的通信传输。网络级弹性策略在第 4 层工作,以监控每个微服务已部署实例的网络性能,并将微服务使用请求定向到最佳实例。例如,如果某个特定的微服务实例由于其所在位置的故障(例如网络中断)而停止响应请求,则新请求将自动定向到该微服务的其他实例。
将云原生应用程序部署为分布式系统的组织应考虑网络和/或应用程序级别的弹性策略。在这里,我们将研究云原生应用程序的四种此类策略:
- 负载均衡
- 超时和自动重试
- 截止日期
- 断路器
负载平衡、超时和自动重试支持分布式系统组件的冗余。截止日期和断路器有助于减少分布式系统任何部分的降级或故障的影响。
负载均衡
云原生应用程序的负载平衡可以在 OSI 模型的多个层执行。就像我们刚刚讨论的弹性策略一样,负载平衡可以在第 4 层(网络或连接级别)或第 7 层(应用程序级别)执行。
对于 Kubernetes,第 4 层负载均衡默认使用 kube-proxy 实现。它在网络连接级别平衡负载。 Pod IP 地址的管理和虚拟/物理网络适配器之间的流量路由是通过容器网络接口 (CNI) 实现或覆盖网络(例如 Calico 或 Weave Net)来处理的。
回到第 4 层负载均衡,假设一个网络连接每秒向一个应用程序发送一百万个请求,而另一个网络连接每秒向同一个应用程序发送一个请求。负载均衡器不知道这种差异;它只看到两个连接。如果它将第一个连接发送到一个微服务实例,并将第二个连接发送到第二个微服务实例,它会认为负载是平衡的。
第 7 层负载平衡基于请求本身,而不是连接。第 7 层负载均衡器可以看到连接中的请求,并将每个请求发送到最佳微服务实例,这可以提供比第 4 层负载均衡器更好的均衡。一般来说,当我们说“负载平衡”时,我们指的是第 7 层负载平衡。此外,虽然第 7 层负载均衡可以应用于服务或微服务,但这里我们只关注将其应用于微服务。
对于云原生应用程序,负载平衡是指在微服务的运行实例之间平衡应用程序的请求。负载均衡假设每个微服务有多个实例;每个实例都有多个实例提供了冗余。只要可行,实例都是分布式的,因此如果特定服务器甚至站点出现故障,并非任何微服务的所有实例都将变得不可用。
理想情况下,每个微服务都应该有足够的实例,这样即使发生故障(例如站点中断),每个微服务仍然有足够的可用实例,以便分布式系统继续为当时需要它的所有人正常运行。
负载平衡算法
有许多用于执行负载平衡的算法。让我们仔细看看其中的三个。
- 轮询是最简单的算法。每个微服务的实例轮流处理请求。例如,如果微服务 A 有三个实例——1、2 和 3——第一个请求将发送到实例 1,第二个发送到实例 2,第三个发送到实例 3。一旦每个微服务收到请求,下一个请求将分配给实例 1 以开始另一个循环通过实例。
- 最少请求是一种负载均衡算法,它将新请求分发给当时待处理请求最少的微服务实例。例如,假设微服务 B 有四个实例,实例 1、2 和 3 现在分别处理 10 个请求,但实例 4 只处理两个请求。使用最小请求算法,下一个请求将转到实例 4。
- 会话亲和性,也称为粘性会话,是一种尝试将会话中的所有请求发送到相同微服务实例的算法。例如,如果用户 Z 正在使用一个应用程序并导致请求被发送到微服务 C 的实例 1,那么在同一用户会话中对微服务 C 的所有其他请求都将被定向到实例 1。
这些算法有许多变体——例如,加权通常被添加到循环和最小请求算法中,这样一些微服务实例接收的请求份额比其他微服务实例更大或更小。例如,您可能希望支持通常比其他人更快地处理请求的微服务实例。
在实践中,单独的负载平衡算法通常不能提供足够的弹性。例如,它们会继续向已经失败且不再响应请求的微服务实例发送请求。这就是添加超时和自动重试等策略的好处。
超时和自动重试
超时是任何分布式系统的基本概念。如果系统的一部分发出请求,而另一部分在一定时间内未能处理该请求,则请求超时。然后,请求者可以使用系统故障部分的冗余实例自动重试请求。
对于微服务,在两个微服务之间建立并强制执行超时。如果微服务 A 的实例向微服务 B 的实例发出请求,而微服务 B 的实例没有及时处理,则请求超时。然后,微服务 A 实例可以使用微服务 B 的不同实例自动重试请求。
无法保证在超时后重试请求会成功。例如,如果微服务 B 的所有实例都有相同的问题,则对其中任何一个的请求都可能失败。但是,如果只有一些实例受到影响——例如,一个数据中心的中断——那么重试很可能会成功。
此外,请求不应总是自动重试。一个常见的原因是避免意外复制已经成功的事务。假设从微服务 A 到微服务 B 的请求被 B 成功处理,但它对 A 的回复延迟或丢失。在某些情况下可以重新发出此请求,但在其他情况下则不行。
- 安全事务是相同请求导致相同结果的事务。这类似于 HTTP 中的 GET 请求。 GET 是一个安全事务,因为它从服务器检索数据但不会导致服务器上的数据被更改。多次读取相同的数据是安全的,因此重新发出安全事务的请求应该没问题。安全事务也称为幂等事务。
- 不安全的事务是相同请求导致不同结果的事务。例如,在 HTTP 中,POST 和 PUT 请求是潜在的不安全事务,因为它们将数据发送到服务器。复制请求可能会导致服务器不止一次地接收该数据并可能不止一次地处理它。如果交易正在授权付款或订单,您当然不希望它发生太多次。
截止日期
除了超时,分布式系统还有所谓的分布式超时,或者更常见的是截止日期。这些涉及系统的两个以上部分。假设有四个相互依赖的微服务:A 向 B 发送请求,B 对其进行处理并将自己的请求发送给 C,C 对其进行处理并向 D 发送请求。回复以另一种方式流动,从 D 流向 C ,C 到 B,B 到 A。
下图描述了这种情况。假设微服务 A 需要在 2.0 秒内回复其请求。在最后期限内,完成请求的剩余时间与中间请求一起移动。这使每个微服务能够优先处理它收到的每个请求,并且当它联系下一个微服务时,它会通知该微服务剩余的时间。

断路器
超时和截止日期分别处理分布式系统中的每个请求和回复。断路器对分布式系统有更多的“全局”视图。如果一个特定的微服务实例没有回复请求或者回复请求的速度比预期的慢,那么断路器可能会导致后续请求被发送到其他实例。
断路器通过为单个微服务实例设置服务降级或故障程度的限制来工作。当实例超过该级别时,会触发断路器并导致微服务实例暂时停止使用。
断路器的目标是防止一个微服务实例的问题对其他微服务产生负面影响并可能导致级联故障。问题解决后,可以再次使用微服务实例。
级联故障通常是由于针对经历降级或故障的微服务实例的自动重试而开始的。假设您有一个微服务实例,请求不堪重负,导致它响应缓慢。如果断路器检测到这一点并暂时阻止新请求进入实例,则实例有机会赶上其请求并恢复。
但是,如果断路器不动作并且新请求继续发送到实例,则该实例可能会完全失败。这会强制所有请求转到其他实例。如果这些实例已经接近容量,新请求也可能使它们不堪重负并最终导致它们失败。这个循环继续下去,最终整个分布式系统都失败了。
使用库实施弹性策略
到目前为止,我们已经讨论了几种弹性策略,包括三种形式的负载平衡加上超时和自动重试、截止日期和断路器。现在是时候开始考虑如何实施这些策略了。
首次部署微服务时,实施弹性策略的最常见方法是让每个微服务使用支持一个或多个策略的标准库。 Hystrix 就是一个例子,它是一个为分布式系统添加弹性特性的开源库。由 Netflix 开发到 2018 年,Hystrix 调用可以包裹在一个微服务中依赖于另一个微服务请求的任何调用。弹性库的另一个示例是 Resilience4j,它旨在用于使用 Java 进行函数式编程。
通过应用程序库实施弹性策略当然是可行的,但它并不适用于所有情况。弹性库是特定于语言的,微服务开发人员通常为每个微服务使用最好的语言,因此弹性库可能不支持所有必要的语言。为了使用弹性库,开发人员可能必须使用提供不理想性能或具有其他重大缺陷的语言编写一些微服务。
另一个问题是依赖库意味着为每个微服务中的每个易受攻击的调用添加调用包装器。一些调用可能会丢失,一些包装可能包含错误——让所有微服务的所有开发人员一致地做事情是一个挑战。还有维护问题——未来每个从事微服务工作的新开发人员都必须了解调用包装器。
使用代理实施弹性策略
随着时间的推移,基于库的弹性策略实现已被基于代理的实现所取代。
一般来说,代理位于两方之间的通信中间,并为这些通信提供某种服务。代理通常在两方之间提供某种程度的分离。例如,A 方向 B 方发出请求,但该请求实际上是从 A 发送到代理,代理处理该请求并将自己的请求发送给 B。A 和 B 不直接相互通信。
下图显示了这种通信流程的示例。一个会话发生在微服务 A 的实例及其代理之间,一个单独的会话发生在 A 的代理和微服务 B 的实例之间。A 到代理和代理到 B 会话共同提供 A 和B.
在分布式系统中,代理可以在微服务实例之间实现弹性策略。继续前面的示例,当微服务 A 的实例向微服务 B 发送请求时,该请求实际上会发送到代理。代理会处理 A 的请求并决定它应该转到哪个微服务 B 的实例,然后它会代表 A 发出请求。
代理会监视来自 B 实例的回复,如果没有及时收到回复,它可以自动使用不同的微服务 B 实例重试请求。图中,微服务 A 的代理有微服务 B 的三个实例可供选择,它选择了第三个。如果第三个实例的响应速度不够快,则代理可以使用第一个或第二个实例来代替。
基于代理的弹性的主要优点是无需修改单个微服务即可使用特殊库;任何微服务都可以被代理。
原文:https://www.getambassador.io/learn/service-mesh/resilience-for-distribu…
- 55 次浏览
【韧性架构设计】确保您的应用程序具有网络韧性的 5 种方法
由 COVID-19 大流行引起的大规模转向远程工作,提高了许多组织对弹性应用安全实践的需求。
除了应对这些天应用程序发布的大量和频率之外,应用程序安全团队现在还必须应对与远程工作和签入来自全球各地的代码相关的挑战。
随着应用程序每周、每天甚至每小时发布到生产环境中,DevSecOps 中的“秒”确实从未像现在这样相关或重要。是时候确保您的应用安全方法具有网络弹性了。这里有五个需要关注的领域。
1.自动化
自动化对于网络弹性至关重要。您需要利用工具,以使应用安全解决方案尽可能无接触和流程驱动。理想情况下,任何可以自动化的东西都应该是自动化的,而弹性系统将允许这样做。事实上,一个有弹性的系统不仅会允许它,而且还会推动自动化。
想象一下未来的环境,如果您需要突然扫描 1,000 个应用程序,您可以自动增加处理该容量所需的扫描仪数量。如果容量发生变化并且您不再需要那么多扫描仪,那么您的系统就足够智能,可以解决这个问题并自动降低数量。
在一个真正有弹性的系统中,自动化将允许开发人员编写和提交代码,并且扫描就会发生。你不应该做任何事情。系统会自动删除您无法修复的内容、在您的环境中不重要的内容、或您的 KPI 和类似性质的内容。这几乎就像您踩下汽车的油门踏板一样。有很多事情要做,但你不需要知道引擎除了它所做的任何事情。这是相当强大的。
最终,目标应该是拥有像拼写检查器一样自我修复的代码。我们还没有到那一步,但有一天会有足够的智能让你相信系统可以自行修复问题。
2. 有可操作的结果
您的应用安全计划应专注于推动测试结果的可操作性。它应该以您今天需要关注的事情为中心。从历史上看,当您真正需要的只是与组织和您相关的问题列表时,应用程序安全解决方案倾向于为您提供要解决的问题的清单。
一个有弹性的系统将专注于你今天需要解决的 10 件事,而不是你可能需要随着时间的推移解决的 1000 件事。它使用智能来识别可能影响或阻止您投入生产的问题。
可操作性是自动化的一部分。这意味着开发人员可以编写一些代码,而在幕后对代码进行评估并尽快显示相关且需要修复的内容。这就像从一匹马和一辆马车变成一辆特斯拉。
3.支持更频繁的扫描
您将代码安全地发布到生产环境中的能力以及遥测的速度在很大程度上取决于您能够扫描应用程序的频率。您需要应用程序安全性的弹性,因为您拥有更多应用程序并且您正在更频繁地扫描它们。这给应用安全团队、开发人员和 CISO 带来了很大压力。
弹性系统支持可扩展的扫描容量,从 1 次扫描到 1+n 次。虽然可扩展性与扫描仪数量和您拥有的应用程序数量有关,但弹性系统中的频率与您扫描这些应用程序的频率有关。
例如,如果您使用 GitHub 并且您每天扫描或提交 20 次,则您需要有一个足够有弹性的系统来处理该频率。这是关于具有突发功能,可以在达到阈值时打开更多扫描,而无需打电话给某人或去寻找其他产品。比如说,你只需在 Docker 中启动另一个容器,就完成了。
4. 覆盖范围广
现代 Web 应用程序非常受 Web 服务驱动,您拥有的 Web 服务和 API 越多,应用程序的风险就越大。弹性是指拥有一个应用安全解决方案,它不仅可以解决您现在正在做的事情,而且还具有应对未来挑战的灵活性和可扩展性。
您的解决方案需要与云无关,并具有涵盖本地和 SaaS 环境的灵活性。它应该能够快速支持新的语言和框架。覆盖面广度意味着支持企业现在和未来需要扫描的各种语言。大多数企业不仅仅拥有 .NET 或 Java,它们还拥有数十种语言。
如果您从 .NET 商店开始,并且拥有 .NET 的静态分析功能,那么如果有新团队加入或收购另一家公司,您是否有能力支持 Java?还是您需要出去购买一套全新的产品?一个有弹性的应用程序安全系统将能够扫描这些新应用程序,您可以简单地决定要利用哪种模型,从 SaaS 或内部部署到混合。
5. 确保它是可扩展的
在弹性系统中,您无需添加基础架构即可获得更多扫描功能。您的系统将与云无关,并且能够按需启动扫描服务器,并在您不需要它们时同样轻松地关闭它们。只需几分钟,您就可以从需要额外容量来扫描更多应用程序转变为仅打开额外容量。
许可灵活性对于可扩展性至关重要。它需要足够灵活,这样您就不必在每次需要额外容量进行静态或动态测试时都购买另一个许可证。您的许可证应该允许您根据需要和扫描容量来回移动。
为什么网络弹性是关键
Verizon 年度数据泄露调查报告的最新版本显示,Web 应用程序漏洞是网络犯罪分子的首要目标。 Verizon 在 2019 年调查的数据泄露事件中,约有 40% 实际上涉及应用程序漏洞。
很明显:强大的应用程序安全计划对企业网络弹性至关重要。按照上面的指导来改变你的方法。
保持学习
- 未来是安全即代码。通过 TechBeacon 指南了解 DevSecOps 如何帮助您实现目标。另外:请参阅 SANS DevSecOps 调查报告,了解对从业者的重要见解。
- 使用 TechBeacon 指南快速了解应用程序安全测试的状态。另外:获取 Gartner 的 2021 年 AST 魔力象限。
- 通过 TechBeacon 的 2021 年应用程序安全工具指南了解应用安全工具领域。
- 下载免费的 Forrester Wave 静态应用程序安全测试。另外:在此网络研讨会中了解 SAST-DAST 组合如何提高您的安全性。
- 了解 API 安全需要访问管理的五个原因。
- 了解如何为未来十年制定应用安全策略,并在应用安全开发人员的生活中度过一天。
- 使用 TechBeacon 指南构建现代应用安全基础。
原文:https://techbeacon.com/security/5-ways-ensure-your-applications-are-cyb…
本文:
- 29 次浏览
【韧性架构设计】软件韧性:从意外中恢复的 7 个必备因素
软件弹性是任何可扩展、高性能和容错软件的必备品质。
软件从意外事件中恢复的能力是软件弹性。 这意味着软件工程师必须预测意外事件并对其进行解释。 创建这种容错的解决方案可以在代码中或在基础设施层上。
分布式系统会失败,一个有弹性的软件系统不会试图避免失败,而是期待它并优雅地响应。
在这篇文章中,我们将研究您需要注意的一些方面,以实现软件弹性。
目录
- 什么是软件弹性
- 弹性软件因素
- 逐步推出/部署
- 重试软件弹性
- 弹性软件的超时
- 倒退
- 幂等操作支持软件弹性
- 数据库事务
- 速率限制
- 其他需要考虑的事项
- 结论
什么是软件弹性
卡内基梅隆大学软件工程学院博客指出:
基本上,如果一个系统在逆境中继续执行其任务(即,如果它提供所需的能力,尽管可能导致中断的过度压力)。具有弹性很重要,因为无论系统设计得多么好,现实迟早会合谋破坏系统。
如果软件系统在发生意外事件时能够部分正常运行,这就是软件弹性。在基础设施层面,有 NetFlix 臭名昭著的 Chaos Monkey。 Chaos Monkey 进入您的生产环境并随机开始杀死实例。这可以作为软件弹性的压力测试。
软件弹性也受到爆炸半径的影响。如果就其可以覆盖的半径而言,变更风险较低,则更容易进行变更。如果爆炸半径非常大,您可能还需要考虑其他事情。
弹性软件因素
有多个因素是软件弹性方程的一部分。以下是我在十多年的软件工程职业生涯中的一些经验。
下面提到的示例将与电子商务有关,因为我已经在时尚电子商务领域工作了将近 9 年。
让我们开始吧。
逐步推出/部署
逐步推出或部署是允许访问部分版本的能力。它可能是金丝雀部署或蓝绿色部署,或者只是一个功能标志,甚至是滚动部署。您可以以丰富多彩的方式阅读有关这些部署技术的更多信息。
这里的重点是,即使这是一项手动任务,它对于弹性软件也非常重要。想象一下,您正在更改电子商务网站的支付网关。如果你进行一次大爆炸,100% 的交易从以前的支付网关 A 转到新的支付网关 B,你将陷入困境。
但是,如果您可以像 1% 的客户一样试用 1 周,那么通过新的网关集成来消除任何错误会很有帮助,并且爆炸半径仅为交易的 1%。
慢慢地,你可以从 1 到 5,然后到 10,最后到 100,充满信心。在部署时进行健康检查也是如此。如果运行状况检查失败,部署将自动回滚。根据服务的不同,您甚至可以逐步推出,这意味着这个特定版本只能获得 2% 的流量。运行在基础设施层而非代码层上的 Google Cloud 等服务支持逐步推出。
弹性软件的另一个重要考虑因素是部署而不是发布。
重试软件弹性
如果您调用另一个系统,您总是需要期望它们可能会失败。因此,在这种情况下,重试机制会有所帮助。例如,您正在调用产品评论服务来创建新的产品评论。
如果它未能创建评论,您可以轻松地重试 1 或 2 次以获得成功的响应。
下面是一个非常简单的 curl 示例:
curl -i --retry 3 http://httpbin.org/status/500
这里的 curl 总是会重试 3 次,因为它会返回 500 错误。 下面的 curl 只会运行一次,因为它会在第一次尝试时返回 200:
curl -i --retry 3 http://httpbin.org/status/200
重试是使软件更具弹性的一种简单但有效的方法。
弹性软件的超时
外部系统可能很慢,您无法控制它们的响应时间。这反过来又会使您开发的系统变慢。一旦我们与“流行”的快递服务集成。不幸的是,他们创建货件的响应时间是几秒钟而不是几毫秒。
我们通过最佳超时解决了这个问题,并在可能的情况下推动任务异步。这确实有助于保持软件弹性完好无损。
这解除了进行质量检查并将物品放入盒子中以运送给客户的人员的障碍。当箱子从 QC 站运送到包装站时,将创建装运并打印运输标签。尽管盒子从 QC 到包装站需要几秒钟的时间,但这足以让我们创建货物。如果某些发货失败,有一个简单的重试选项,即按需致电快递员。
故事的寓意,总是添加相关的超时并快速失败。根据需要为用户提供一种在需要时手动重试的方法。超时非常重要。
倒退
回退是一个非常简单的概念。如果主要的东西不起作用,请使用备份。对于 Web 系统来说,主要的事情可以是来自 API 的响应。因此,如果您的 API 调用在重试后仍然失败,您可以回退到响应的本地副本。
另一个纯代码的例子可以很简单:
const shippingFee = fees.shipping ? fees.shipping: 10.00;
在上面的代码片段中,它会查找 fee.shipping 如果不可用,它会回退到 10.00 的值。我们可以在 API 调用中实现相同的功能,如果我们没有从 API 调用中得到想要的结果,它将优雅地降级为使用默认值。
回退似乎很明显,但有时我看到它们被遗忘或省略。
这可能会导致高流量系统出现问题。
幂等操作支持软件弹性
一个堆栈溢出答案总结得很好:
在计算中,幂等操作是指使用相同的输入参数多次调用它时不会产生额外影响的操作。
在现实生活中,它就像公共汽车上的那个停止按钮。停车标志亮起后按一次或100次,效果相同,指示公交车司机在下一个公交车站停车。例如,API 中的 GET 操作是幂等的。这对于设计弹性系统很重要,让我用一个例子来解释一下。
您正在设计一个 API 来将消息标记为已读。
无论调用多少次 API 将单条消息标记为已读,第一个都将其从未读设置为已读,并且所有其他都不会更改状态。
这是一个易于理解的幂等性示例。在使您的系统具有弹性时,您可以安全地忽略第二个和以后的请求,以保留您的资源。
数据库事务
理解数据库事务的最简单方法是全有或全无。如果您有 3 个步骤来完成一项任务,并且在第 2 步中存在问题,它将回滚整个操作。
一个典型的例子是两个银行账户之间的汇款,要么全部通过,要么什么也没发生。
不应该出现A账户扣款但B账户没有充值的情况。数据库事务对于数据的一致性非常重要。
通过充分利用隔离级别,我们可以使用数据库事务来应对竞争条件。例如,一个 cron 将更新 20 条记录,如果这些行与另一个系统(如 ERP)成功同步,则名为 synced 的标志将设置为 true。可以通过以下步骤完成,以避免另一个 cron 同时执行相同的任务:
准备基础任务,例如将这些行与企业资源规划 (ERP) 软件同步启动数据库事务SELECT … FOR UPDATE,隔离级别已提交,会话超时时间比平时长将行与 ERP 同步使用更新查询将所选行的同步标志设置为 1提交交易如果有任何问题,回滚整个事务
因此,在上述情况下,如果第 4 步失败,事务将回滚。当行被 select for update 锁定时,另一个 cron 将无法读取它,因为它被锁定为 UPDATE 并且在隔离级别读取提交的情况下完成。
这有助于通过停止同步相同的行两次来创建容错和弹性软件。如果另一个 cron 甚至在第一个 cron 运行时错误地运行,它将等待这些行可以被新的 SELECT ... FOR UPDATE 查询自由读取。
速率限制
到现在为止,您肯定已经发现,要使软件更具弹性,就需要以最佳方式使用资源。这个速率限制因素正在避免我们的资源被滥用。例如,Twitter API 速率限制调用。让我们以 Twitter API 上的 /statuses/user_timeline 为例,它显示“900 个请求/15 分钟窗口(用户身份验证)”和“100,000 个请求/24 小时窗口(应用程序级别)”。因此,如果作为消费者,您拨打超过 900 次电话以获取用户的雕像,则会收到状态码为 429 的响应。
开发 API 时必须遵循相同的原则,即使它们被其他内部服务使用。让我们假设如果其他内部服务之一有一个错误配置的无限循环,那么当它开始疯狂地攻击您的服务时,您的服务将停机。
如果您有一个良好的速率限制,其他服务将尽早开始发现错误,他们可以更快地解决问题。
最后,您的服务不会占用资源,也不会通过更快地失败来保持正常。
其他需要考虑的事项
为了获得更好的软件弹性,还有许多其他事情需要考虑。数据库读写隔离是一种很好的做法。其中有一个主要用于写入和多个读取副本的主数据库。
在这种情况下,读取的大部分操作在读取副本之间进行负载平衡,并且主节点获得写入。
主服务器与只读副本同步可能会有“几秒钟”的延迟,但这是您应该愿意为它提供的弹性支付的成本。
另一个重要的软件弹性模式是断路器模式。
类似于您家的断路器,如果您的软件系统多次无法访问另一个软件系统,它会破坏标记它打开的电路。它会定期检查其他系统是否已恢复。
当另一个系统恢复时,电路再次闭合。微软博客对断路器模式有很好的解释。
弹性软件系统自动扩展。它们根据负载累加资源。这一点也和软件的可扩展性有关,一般软件可扩展性和弹性是齐头并进的。自动缩放系统依赖于健康检查。
对于具有弹性负载的系统,它们应该能够在负载高时添加资源,并在流量下降时降低资源。
这使软件保持弹性并且成本也处于最佳状态。
结论
弹性和自我修复软件对于高正常运行时间非常重要。
即使在逆境的情况下,软件性能可能会降低但功能性能是弹性软件的标志。
软件弹性是通过始终质疑如果失败会发生什么来实现的,尤其是在与数据库或外部 API 等外部服务通信时。我希望这可以帮助您构建更具弹性的软件。如果您还有其他方面要分享,请不要忘记发表评论。
原文:https://geshan.com.np/blog/2020/12/software-resilience/
本文:
- 58 次浏览
【韧性设计】节流模式
控制应用程序实例、单个租户或整个服务使用的资源消耗。这可以使系统继续运行并满足服务水平协议,即使需求增加对资源造成极大负载。
背景和问题
云应用程序的负载通常会根据活动用户的数量或他们正在执行的活动类型而随时间变化。例如,更多用户可能会在工作时间处于活跃状态,或者系统可能需要在每个月底执行计算成本高昂的分析。活动中也可能出现突然的和意料之外的爆发。如果系统的处理需求超过了可用资源的容量,那么它的性能就会很差,甚至会失败。如果系统必须满足商定的服务水平,则此类故障可能是不可接受的。
有许多策略可用于处理云中的不同负载,具体取决于应用程序的业务目标。一种策略是使用自动缩放在任何给定时间将供应的资源与用户需求相匹配。这有可能始终如一地满足用户需求,同时优化运行成本。但是,虽然自动缩放可以触发额外资源的配置,但这种配置并不是立即的。如果需求快速增长,可能会出现资源短缺的时间窗口。
解决方案
自动缩放的另一种策略是允许应用程序仅在某个限制内使用资源,然后在达到此限制时限制它们。系统应该监控它是如何使用资源的,以便当使用量超过阈值时,它可以限制来自一个或多个用户的请求。这将使系统能够继续运行并满足任何现有的服务水平协议 (SLA)。有关监控资源使用情况的更多信息,请参阅 Instrumentation and Telemetry Guidance。
该系统可以实施多种节流策略,包括:
- 拒绝在给定时间段内每秒访问系统 API 超过 n 次的单个用户的请求。这需要系统计量每个租户或运行应用程序的用户的资源使用情况。有关详细信息,请参阅服务计量指南。
- 禁用或降低选定非必要服务的功能,以便必要服务可以在有足够资源的情况下畅通无阻地运行。例如,如果应用程序正在流式传输视频输出,它可以切换到较低的分辨率。
- 使用负载均衡来平滑活动量(基于队列的负载均衡模式更详细地介绍了这种方法)。在多租户环境中,这种方法会降低每个租户的性能。如果系统必须支持具有不同 SLA 的租户组合,则可能会立即执行高价值租户的工作。可以推迟对其他租户的请求,并在积压情况缓解后进行处理。优先队列模式可以用来帮助实现这种方法。
- 推迟代表较低优先级的应用程序或租户执行的操作。这些操作可以暂停或限制,但会生成一个异常通知租户系统正忙,稍后应重试该操作。
该图显示了使用三个功能的应用程序的资源使用(内存、CPU、带宽和其他因素的组合)与时间的面积图。特性是功能的一个区域,例如执行一组特定任务的组件、执行复杂计算的一段代码或提供诸如内存缓存之类的服务的元素。这些特征标记为 A、B 和 C。
特性线正下方的区域指示应用程序在调用此特性时使用的资源。例如,功能 A 的线下方的区域显示正在使用功能 A 的应用程序使用的资源,功能 A 和功能 B 的线之间的区域表示调用功能 B 的应用程序使用的资源。聚合区域每个功能都显示系统的总资源使用情况。
上图说明了延迟操作的影响。就在时间 T1 之前,分配给使用这些功能的所有应用程序的总资源达到阈值(资源使用限制)。此时,应用程序有耗尽可用资源的危险。在这个系统中,功能 B 不如功能 A 或功能 C 重要,因此它被暂时禁用并且它正在使用的资源被释放。在时间 T1 和 T2 之间,使用功能 A 和功能 C 的应用程序继续正常运行。最终,这两个功能的资源使用减少到在时间 T2 有足够的容量再次启用功能 B 的程度。
自动缩放和限制方法也可以结合使用,以帮助保持应用程序响应并在 SLA 范围内。如果预计需求将保持高位,则在系统横向扩展时,节流提供了一种临时解决方案。此时,可以恢复系统的全部功能。
下图显示了系统中运行的所有应用程序对时间的总体资源使用情况的区域图,并说明了如何将限制与自动缩放结合起来。
在时间 T1,达到指定资源使用的软限制的阈值。此时,系统可以开始横向扩展。但是,如果新资源没有足够快地可用,则现有资源可能会耗尽,系统可能会失败。如前所述,为防止这种情况发生,系统会暂时受到限制。当自动缩放完成并且额外的资源可用时,可以放松限制。
问题和考虑
在决定如何实现此模式时,您应该考虑以下几点:
- 限制应用程序和使用的策略是影响整个系统设计的架构决策。应该在应用程序设计过程的早期考虑节流,因为一旦实现了系统就不容易添加。
- 必须快速执行节流。系统必须能够检测到活动的增加并做出相应的反应。系统还必须能够在负载减轻后迅速恢复到原始状态。这需要持续捕获和监控适当的性能数据。
- 如果服务需要暂时拒绝用户请求,它应该返回特定的错误代码,以便客户端应用程序了解拒绝执行操作的原因是由于限制。客户端应用程序可以在重试请求之前等待一段时间。
- 系统自动缩放时,节流可用作临时措施。在某些情况下,如果活动突然爆发并且预计不会长期存在,则最好简单地限制而不是扩展,因为扩展会大大增加运行成本。
- 如果在系统自动缩放时将节流用作临时措施,并且如果资源需求增长非常快,则系统可能无法继续运行,即使在节流模式下运行也是如此。如果这不可接受,请考虑保持更大的容量储备并配置更积极的自动缩放。
何时使用此模式
使用此模式:
- 确保系统继续满足服务水平协议。
- 防止单个租户垄断应用程序提供的资源。
- 处理活动的突发。
- 通过限制保持系统运行所需的最大资源水平来帮助优化系统成本。
例子
最后一张图说明了如何在多租户系统中实现节流。每个租户组织的用户都可以访问云托管的应用程序,并在其中填写和提交调查。该应用程序包含监控这些用户向应用程序提交请求的速率的工具。
为了防止来自一个租户的用户影响应用程序对所有其他用户的响应能力和可用性,对来自任何一个租户的用户每秒可以提交的请求数施加了限制。应用程序阻止超过此限制的请求。
下一步
在实施此模式时,以下指南也可能是相关的:
- 仪器仪表和遥测指导。限制取决于收集有关服务使用量的信息。描述如何生成和捕获自定义监控信息。
- 服务计量指南。描述如何计量服务的使用,以了解它们的使用方式。此信息可用于确定如何限制服务。
- 自动缩放指导。节流可用作系统自动缩放时的临时措施,或消除系统自动缩放的需要。包含有关自动缩放策略的信息。
相关指导
在实现此模式时,以下模式也可能是相关的:
- 基于队列的负载均衡模式。基于队列的负载均衡是实现节流的常用机制。队列可以充当缓冲区,帮助平衡应用程序发送到服务的请求的速率。
- 优先队列模式。系统可以使用优先队列作为其节流策略的一部分,以维持关键或更高价值应用程序的性能,同时降低不太重要的应用程序的性能。
原文:https://docs.microsoft.com/en-us/azure/architecture/patterns/throttling
- 28 次浏览